Mein erstes Papier: Carbontracker und TM5-4DVar
Mein erstes Papier ist seit dem 25. März 2015 in Interaktiver Diskussion und seit 1. September 2015 veröffentlicht:
Comparing the CarbonTracker and TM5-4DVar data assimilation systems for CO₂ surface flux inversions
— A. Babenhauserheide, S. Basu, S. Houweling, W. Peters and A. Butz
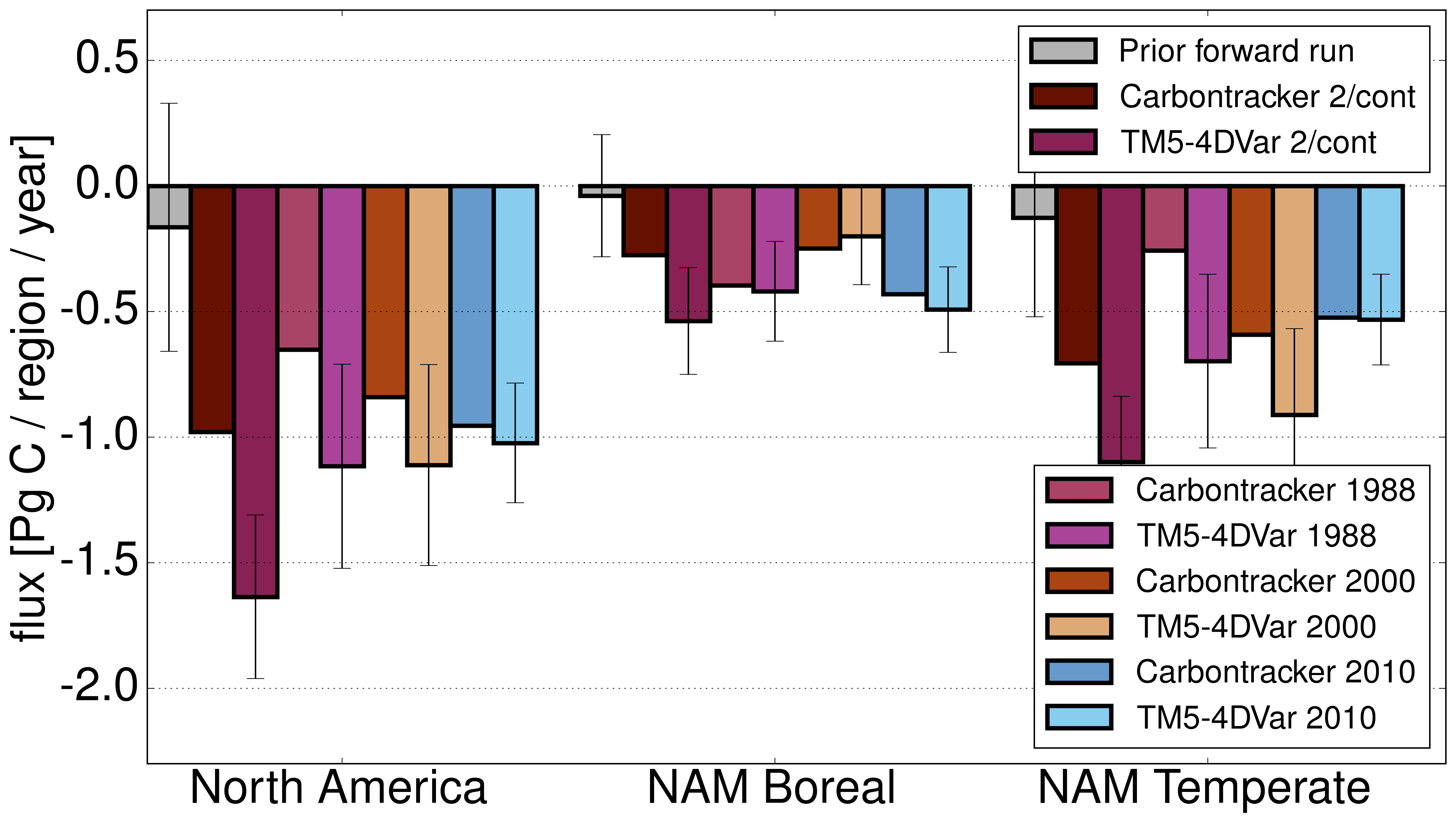
(alle Bilder, die ich hier nutze, sind Open Access,1 genauer gesagt: unter cc by lizensiert: A. Babenhauserheide. Bitte nennt die Autoren und verlinkt das Papier, wenn ihr sie verwendet.)
Zusammen mit den Co-Autoren habe ich zwei Inverse Modelle verglichen, mit denen die CO₂ Quellen und Senken in der Biosphäre (wie verrottende Blätter und Kohlenstoffaufnahme in Wäldern) optimiert werden, um konsistent mit Messungen der CO₂ Konzentration in der Atmosphäre zu sein.
Wir konnten zeigen, dass die Modelle im Rahmen der Validierungsmöglichkeiten gleich gut sind, die Mindestunsicherheit abschätzen, die bei dem genutzten Messnetzwerk (Stationen von 2010) für Quellen und Senken durch Annahmen im Inversen Modell bewirkt wird (auf kontinentaler Skala im Durchschnitt bei 0.25 PgC/a — in der Größenordnung der halben jährlichen Europäischen Flüsse), und zeigen, dass bei steigender Beobachtungsdichte der Unterschied zwischen beiden Modelles sinkt, so dass ein dichteres Messnetzwerk es ermöglichen würde, robuste Flüsse auf Subkontinentaler Skala zu erhalten.
Verkürzt:
- Die Modelle sind im Rahmen der Messgenauigkeit gleich gut.
- Die Unsicherheit jährlicher kontinentaler Flüsse liegt bei dem Messnetzwerk von 2010 bei mindestens 0.25 PgC/a.
- Ein dichteres Messnetzwerk kann robuste Flüsse auf subkontinentaler Skala liefern.
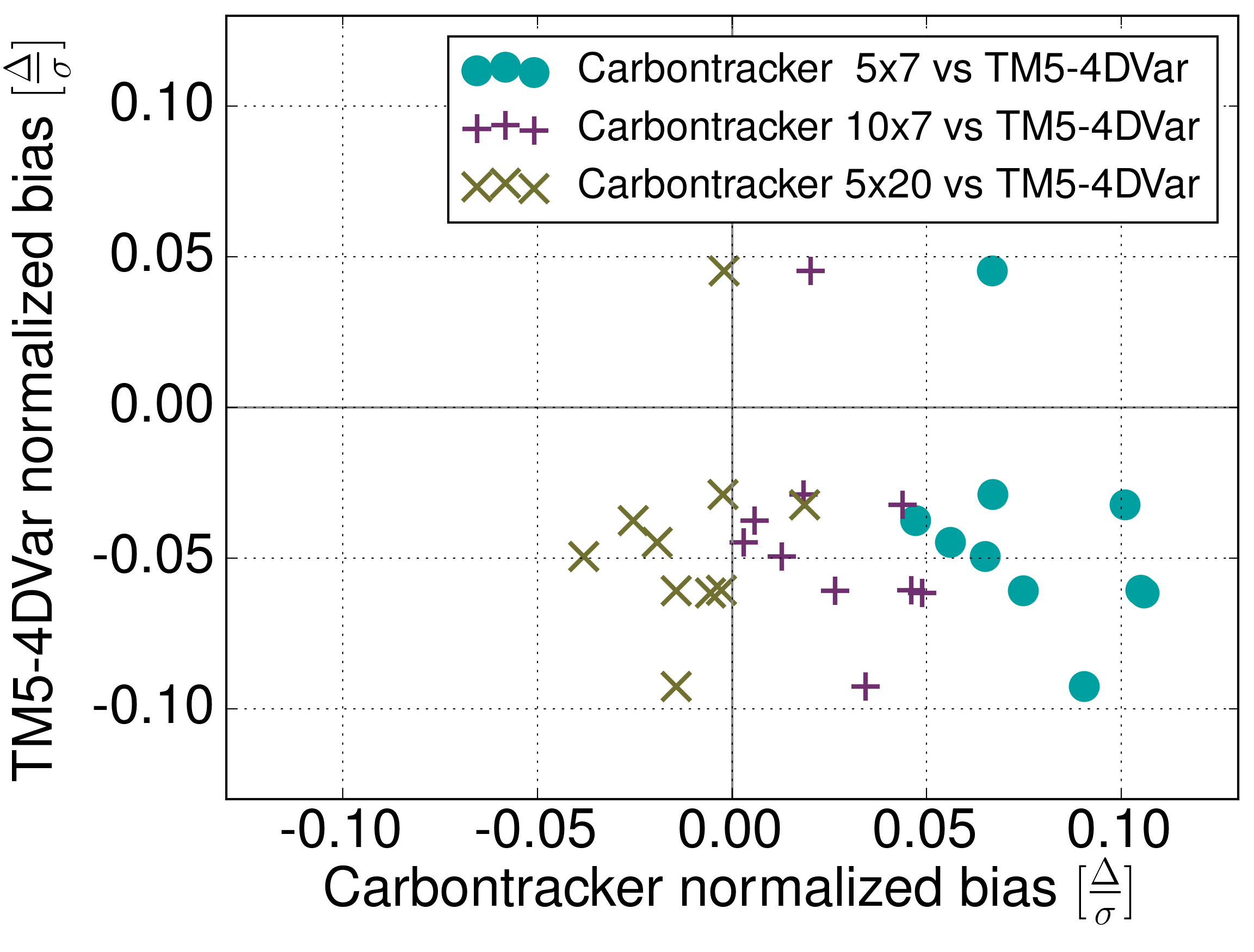
Außerdem konnten wir einige interessante Aspekte der Flüsse in der Antarktis und in Asien untersuchen.
Die Ergebnisse klingen erstmal nach wenig, waren aber drei Jahre Arbeit: Beide Modelle zum Laufen bringen, dafür sorgen, dass alle Eingabeparameter und Eingabedaten hinreichend gleich sind, und relevante, statistisch robuste Vergleiche zu finden. Und debuggen, debuggen, debuggen :)
Von der Aussage „wir haben Ergebnisse“
bis hin zu „unsere Ergebnisse sind wissenschaftlich tragfähig“
ist es ein weiter Weg: Wir haben ein Jahr lang immer und immer wieder neue Vergleiche und Analysen laufen lassen, geprüft und diskutiert, bis wir ein Ergebnis hatten, mit dem wir zufrieden waren. Es war viel Arbeit, aber sie war es wert.
Und damit zurück zum Papier.
Die beiden verglichenen Modelle sind Carbontracker und TM5-4DVar.
Carbontracker ist das etablierte Modell des Earth Science Research Lab von NOAA. Es liefert operative2 CO₂ Flüsse (Quellen und Senken) und wird durch einem internationalen Team von Wissenschaftlern weiterentwickelt. Wouter Peters aus den Niederlanden ist dabei eine der treibenden Kräfte und war Erstautor des ursprünglichen Papiers zu Carbontracker:
An atmospheric perspective on North American carbon dioxide exchange: CarbonTracker
— Wouter Peters, Andrew R. Jacobson , Colm Sweeney , Arlyn E. Andrews, Thomas J. Conway, Kenneth Masarie, John B. Miller, Lori M. P. Bruhwiler, Gabrielle Pétron , Adam I. Hirsch , Douglas E. J. Worthy, Guido R. van der Werf, James T. Randerson , Paul O. Wennberg, Maarten C. Krol , and Pieter P. Tans
TM5-4DVar ist ein eng mit dem Transport Model 5 (TM5) verzahntes inverses Modell, das bis vor ein paar Jahren hauptsächlich in den Niederlanden entwickelt wurde, von wo aus Sander Houweling weiterhin als einer der Hauptentwickler agiert. Der Erstautor des Papiers, das wir zu TM5-4DVar referenziert haben ist Sourish Basu, der uns viel mit dem Aufsetzen und verstehen des Modells geholfen hat:
Global CO₂ fluxes estimated from GOSAT retrievals of total column CO₂
— S. Basu, S. Guerlet, A. Butz, S. Houweling, O. Hasekamp, I. Aben, P. Krummel, P. Steele, R. Langenfelds, M. Torn, S. Biraud, B. Stephens, A. Andrews, and D. Worthy
Das Papier fängt wie üblich mit der Einleitung an: Warum ist das hier wirklich wichtig. Die Kurzform der Antwort ist: Weil die globalen Modelle für Quellen und Senken von CO₂ viel besser werden müssen, wenn wir erkennen wollen, wie die Biosphäre auf den Klimawandel reagiert. Wenn wir das nicht können, haben wir kaum eine Chance einzugreifen, wenn sich das ändert. Aktuell nehmen Ozeane und Biosphäre etwa 50% des CO₂ auf, das wir in die Atmosphäre pumpen. Würde das wegfallen, würden die CO₂ Konzentrationen doppelt so schnell steigen wie bisher. Und aktuell könnten wir nur sagen, dass sich etwas ändert, aber nicht wo.
Danach kommt die minimale Menge an Mathematik, um die Modelle zu verstehen (Dank für eine deutlich kompaktere Darstellung geht an André, meinen Gruppenleiter), gefolgt von der Beschreibung des Aufbaus: Welche Daten nutzen wir, wie bereiten wir sie auf, aus welchen Modellen kommen sie, welche Modelle sind Teil unserer Prozessierungskette und was für Experimente machen wir.
Und dann kommen wir zu den Ergebnissen.
Um das etwas spannender zu machen, habe ich sie im up-goer five text editor beschrieben:
We let think-boxes dream two dreams starting from the same ideas how much animal-breath we can find in the air at less than one hundred places in the world and where animal-breath could go to and where it could come from.
The dreams of the think-boxes search for better ideas where animal-breath could come from and where it could go to.
To find out how good the dreams fit the real world we look how different they are from places where we know how much animal breath is in the air which we did not tell the think-boxes about when they started to dream.
Then we look where the dreams are different to get an idea how close they are to the real world. This idea is not the real world but it tells us how different the real world can be from the dreams.
We find that the dreams are so close to each other that we can not say which one is better.
We also find that we do not know whether the old world is a place where animal-breath goes to or where it comes from.
But we see that when we would have as many places which look at animal-breath at every place in the world as in the new world, then we could know about the old world, too. And to find out for smaller places whether animal-breath goes there or whether it comes from there, we only need to start more places where we watch animal-breath.
Twenty new places should allow understanding the old world well enough that we would see it when its woods would take up only half as much animal breath as the year before.
And that is what I did for three years: Finding out how well we know where animal-breath comes from and goes to.
Und um das abzurunden, gleich noch den Grund, warum ich das eigentlich mache:
This is what I do for work:
I tell think-boxes how to find out where animal-breath which we can see in the air comes from and goes to.
That animal-breath warms our world because it holds warming light down which the ground sends up away. It does not only come from animals, but also from burning things which we bring out from the ground where they had rested.
We can see how much of that animal-breath is in the air at the moment, but only on the ground at very few places or from high up with much wrong-being.
To find out where it comes from, I tell the think-boxes to dream many different dreams. They dream where the animal-breath could come from and how much of it we would see if the dream were true at the places in the world at which we know how much there really is. Then they change the dreams to make how much animal-breath the dreams see fit better what we see in the real world.
And when the dreams agree with what we see in the real world, we think that what the dreams say where the animal-breath comes from and goes to is close to where it comes from in the real world.
And that is what I want to find out: I try to learn where animal-breath comes from and where it goes.
Das war’s ☺
Ich hoffe, euch hat meine Beschreibung meines Papiers gefallen!
Was ich hier geschrieben habe ist nur eine Annäherung an das Papier und ganz sicher keine offizielle Übersetzung. Wer sich über irgendetwas hier wundert und damit ins Internet rennt, ohne vorher das Papier zu lesen, der oder die ist doof ☺
Damit sollte auch klar sein, wie ernst ich solche Beschwerden nehmen würde.
-
Dank Open Access darf ich jetzt auch endlich darüber schreiben, was ich die letzten zwei Jahre gemacht habe. In meinem Arbeitsvertrag steht nämlich „Klappe halten“, und erst die Lizensierung unter cc Namensnennung erlaubt mir formell, die selbsterstellten Grafiken hier zu zeigen. Ich weiß, dass viele das nicht so ernst nehmen, aber ich arbeite an Freenet mit, da will ich mir rechtlich keine offene Flanke geben. ↩
-
Operativ bedeutet, dass regelmäßig Daten geliefert werden, die als qualitativ hochwertig angesehen werden3, dass andere darauf aufbauen können. ↩
-
Qualitativ hochwertig heißt in allererster Linie, dass Unsicherheiten sauber angegeben werden. Damit ist klar, welche Aussagen auf Grundlage der Daten getroffen werden können und welche nicht. Bei einem Wert von 3±3 könnte ich zum Beispiel nicht sagen, dass der Wert positiv ist, weil bei einer erneuten Berechnung, die andere (aber gleich gute) Grundlagen verwendet, mit einer Wahrscheinlichkeit von 16% ein negativer Wert herauskommen würde. Bei 3±3 wird der Bereich 0 bis 6 als „ein Sigma“ (1σ) bezeichnet: In diesem Bereich liegen bei Gaussscher Normalverteilung (typischer Zufall) 68% der Messwerte. Der Bereich -3 bis 9 wird als „zwei Sigma“ (2σ) bezeichnet. Darin liegen 95% der Messwerte. Wenn ein Ergebnis außerhalb zwei Sigma liegt, wird das meist als Indikator gesehen, dass es signifikant von dem erwarteten Wert abweicht. Wenn also jemand sagt „in der Tanzkneipe sind normalerweise 15±6 Leute“ und am Karaokeabend zähle ich 30 Leute, sind das mehr als zwei Sigma (der 2σ Bereich ist 3 bis 27) , also könnte ich sagen, dass Karaoke die Anzahl der Leute in der Kneipe signifikant erhöht. Wer gemerkt hat, dass hier was nicht stimmt, weil es nicht möglich ist, um 3σ nach unten abzuweichen, und deswegen die ganze Kneipen-Statistik in Frage stellt, hat recht - und wird vermutlich Spaß an dem Wikipedia-Artikel zur Poisson-Verteilung haben ☺. ↩
| Anhang | Größe |
|---|---|
| flux-histobs-flux-ct-t4d-alternating-nam.pdf | 50.59 KB |
| flux-histobs-flux-ct-t4d-alternating-nam.png | 224.15 KB |
| randomsets-case-resampling-ctvst4d-5x7-5x20.pdf | 148.83 KB |
| randomsets-case-resampling-ctvst4d-5x7-5x20.png | 153.14 KB |
{kind=link}
{kind=link}
- Druckversion
- Login to post comments
Use Node:
⚙ Babcom is trying to load the comments ⚙
This textbox will disappear when the comments have been loaded.
If the box below shows an error-page, you need to install Freenet with the Sone-Plugin or set the node-path to your freenet node and click the Reload Comments button (or return).
If you see something like Invalid key: java.net.MalformedURLException: There is no @ in that URI! (Sone/search.html), you need to setup Sone and the Web of Trust
If you had Javascript enabled, you would see comments for this page instead of the Sone page of the sites author.
Note: To make a comment which isn’t a reply visible to others here, include a link to this site somewhere in the text of your comment. It will then show up here. To ensure that I get notified of your comment, also include my Sone-ID.
Link to this site and my Sone ID: sone://6~ZDYdvAgMoUfG6M5Kwi7SQqyS-gTcyFeaNN1Pf3FvY
This spam-resistant comment-field is made with babcom.
Diese Seite nutzt Cookies. Und Bilder. Manchmal auch Text. Eins davon muss ich wohl erwähnen — sagen die meisten anderen, und ich habe grade keine Zeit, Rechtstexte dazu zu lesen…