The Freenet social trust graph
Are trust relationships different in anonymous networks? This article should give you the tools to find out.
Update 2017: Now available from figshare with DOI 10.6084/m9.figshare.4725664
Update 2020: This data was used in Fuzzy Graph Modelling of Anonymous Networks (2018)!
Update 2020-11: Added graph of WoT under attack.
Recently we were asked in the #freenet IRC channel, whether we have a copy of the trust graph in the Web of Trust plugin (which provides service discovery and spam protection). While there is an easy way to get the non-spamming identities directly from the plugin (see wotutil), I decided to take the opportunity to do some Guile hacking: Crawling all the identities to dump a full copy of the trust graph. This also gives us IDs which are marked as spammers, and consequently ignored by the Web of Trust plugin.
So, firstoff, this is how the whole trust graph looks, about 13,000 identities and 250,000 trust relationships, with the size of the nodes showing the analyzed hub-value of the identities and the color showing the Eigenvector Centrality. Many of the nodes overlap, since the graph layouting in Gephi took hours to optimize it.

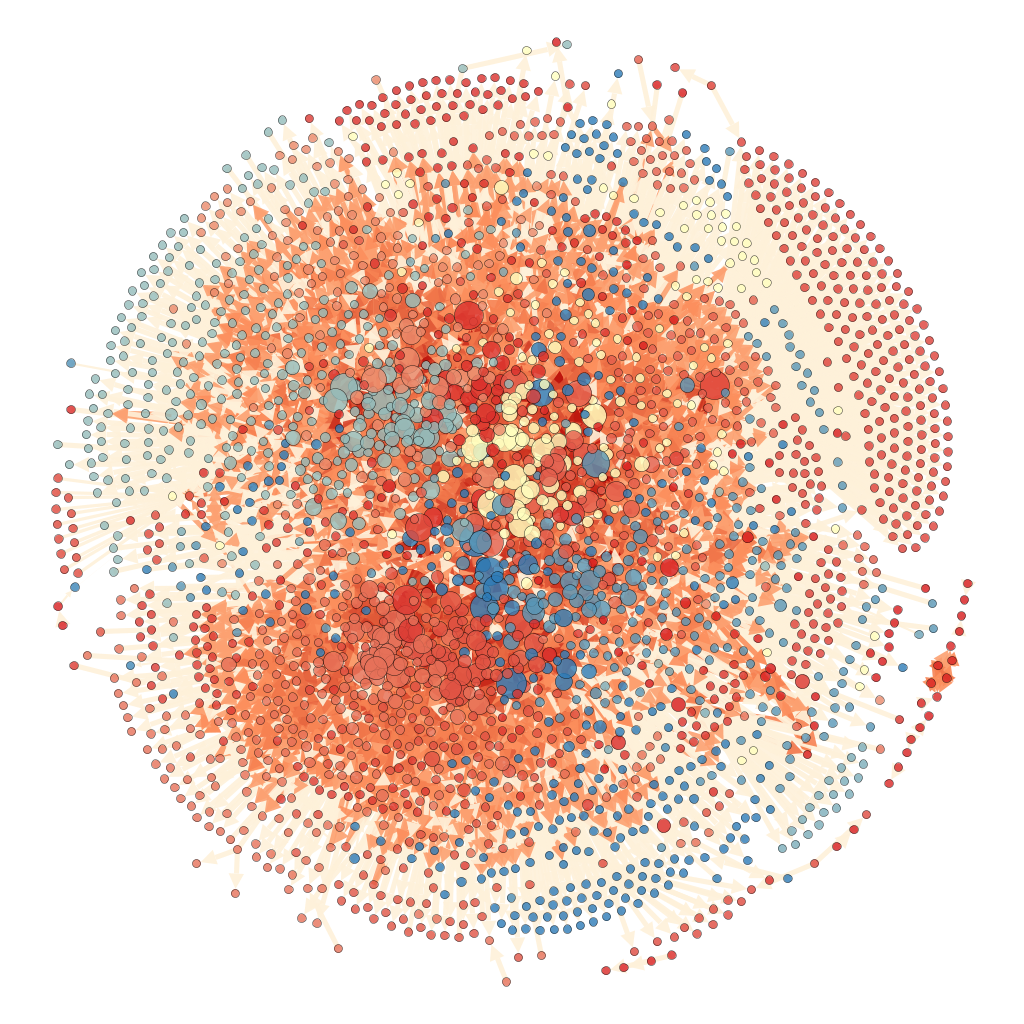
This is the 2020-11-01 graph, likely attackers in red, circles packed by hubbiness with Mike Bostock's Algorithm (also Gephi, but fast):

I will not investigate all the details here. Instead, the files trust-deduplicated.csv and trust-sone.csv contain anonymized snapshots of the edges in the Web of Trust graph which can be loaded in common graph analysis tools. The first contains all trust values, the second only those which were set by the anonymous social network Sone, which indicates that the user saw at least one message of the other user.
An example of the investigations which can be done with this dataset is the following graph, where I let Gephi split the graph into communities using clustering analysis. The colors indicate the community, while the size of the nodes shows the hub-value and the color of the connections shows the betweenness. This uses the Reingold layout.
It’s already visible, that there are communities where the trust connection is realized by only a single node which trusts many others, but that there is also a well-connected center.
The identities in the csv files are given by an index in the list of identities instead of using their key to make it easy for researchers to use the data without having to fear that they might de-anonymize someone with correlation analysis or similar. The index-value depends on the identity files downloaded at
This dataset was created using the following scripts:
Simply execute them in order to get the file trust-anonymized.csv
(the most current version is available from notabug via Git from Bitbucket via Mercurial and from a static clone via Mercurial)
(to run the scripts, you need Guile 2.0.11 or later installed and Freenet running on port 8888. You might have to run them several times to retrieve seldomly accessed identities)
If you use this dataset, for example to investigate social interaction or the effects of anonymity, please drop me a note and reference the Freenet Project and me (Arne Babenhauserheide).
I release the csv files under cc by. If you use my Guile Scheme scripts (with the scm suffix) for research, I hereby grant the additional permission to use them under cc by, too. This should make it easy to comply with releasing your scripts and data as Open Access.
| Anhang | Größe |
|---|---|
| trust-deduplicated-force-atlas-hub-centrality.png | 1.37 MB |
| trust-sone-reingold.png | 953.21 KB |
| trust-sone.csv | 218.92 KB |
| trust-deduplicated.csv | 3.58 MB |
| crawl-wot.scm | 8.64 KB |
| parse-crawled.scm | 3.35 KB |
| anonymize-csv.scm | 3.18 KB |
| deduplicate-csv.scm | 1.35 KB |
| trust-anonymized-2020-11-01-under-attack.csv | 3.17 MB |
| attacking-nodes-2020-11-01.csv | 277 Bytes |
| 2020-11-01-parse-crawled.scm | 3.35 KB |
| 2020-11-01-crawl-wot.scm | 9.49 KB |
| 2020-11-01-deduplicate-csv.scm | 1.35 KB |
| 2020-11-01-anonymize-csv.scm | 3.47 KB |
| 2020-11-01-graph-attackers-red-hubbiness-circle-pack.png | 894.42 KB |
{kind=link}
{kind=link}
{kind=link}
- Druckversion
- Login to post comments
Use Node:
⚙ Babcom is trying to load the comments ⚙
This textbox will disappear when the comments have been loaded.
If the box below shows an error-page, you need to install Freenet with the Sone-Plugin or set the node-path to your freenet node and click the Reload Comments button (or return).
If you see something like Invalid key: java.net.MalformedURLException: There is no @ in that URI! (Sone/search.html), you need to setup Sone and the Web of Trust
If you had Javascript enabled, you would see comments for this page instead of the Sone page of the sites author.
Note: To make a comment which isn’t a reply visible to others here, include a link to this site somewhere in the text of your comment. It will then show up here. To ensure that I get notified of your comment, also include my Sone-ID.
Link to this site and my Sone ID: sone://6~ZDYdvAgMoUfG6M5Kwi7SQqyS-gTcyFeaNN1Pf3FvY
This spam-resistant comment-field is made with babcom.
Diese Seite nutzt Cookies. Und Bilder. Manchmal auch Text. Eins davon muss ich wohl erwähnen — sagen die meisten anderen, und ich habe grade keine Zeit, Rechtstexte dazu zu lesen…