„Free, Reliable, Ethical and Efficient“
„Frei, Robust, Ethisch und Innovativ”
„Libre, Inagotable, Bravo, Racional y Encantado“
Articles connected to Free Software (mostly as defined by the GNU Project [1]). This is more technical than Politics and Free Licensing [2], though there is some overlap.
Also see my lists of articles about specific free software projects:
There is also a German Version to this Page: Freie Software [6]. Most articles are not translated, so the content on the german page and on the english page is very different.
New version: draketo.de/software/wisp [7]
» I love the syntax of Python, but crave the simplicity and power of Lisp.«
display "Hello World!" ↦ (display "Hello World!")
define : factorial n (define (factorial n) if : zero? n ↦ (if (zero? n) . 1 1 * n : factorial {n - 1} (* n (factorial {n - 1}))))
hg clone https://hg.sr.ht/~arnebab/wisp [9]
guix install guile guile-wisp./configure; make install from the releases.»ArneBab's alternate sexp syntax is best I've seen; pythonesque, hides parens but keeps power« — Christopher Webber in twitter [14], in identi.ca [15] and in his blog: Wisp: Lisp, minus the parentheses [16]
♡ wow ♡
»Wisp allows people to see code how Lispers perceive it. Its structure becomes apparent.« — Ricardo Wurmus in IRC, paraphrasing the wisp statement from his talk at FOSDEM 2019 about Guix for reproducible science in HPC [17].
☺ Yay! ☺
with (open-file "with.w" "r") as port format #t "~a\n" : read portFamiliar with-statement in 25 lines [18].
Update (2020-09-15): Wisp 1.0.3 [19] provides a
wispbinary to start a wisp repl or run wisp files, builds with Guile 3, and moved to sourcehut for libre hosting: hg.sr.ht/~arnebab/wisp [9].
After installation, just runwispto enter a wisp-shell (REPL).
This release also ships wisp-mode 0.2.6 (fewer autoloads), ob-wisp 0.1 (initial support for org-babel), and additional examples. New auxiliary projects include wispserve [20] for experiments with streaming and download-mesh via Guile and wisp in conf [21]:conf new -l wisp PROJNAMEcreates an autotools project with wisp whileconf new -l wisp-enter PROJAMEcreates a project with natural script writing [22] and guile doctests [23] set up. Both also install a script to run your project with minimal start time: I see 25ms to 130ms for hello world (36ms on average). The name of the script is the name of your project.
For more info about Wisp 1.0.3, see the NEWS file [24].
To test wisp v1.0.3, install Guile 2.0.11 or later [25] and bootstrap wisp:wget https://www.draketo.de/files/wisp-1.0.3.tar_.gz;
tar xf wisp-1.0.3.tar_.gz ; cd wisp-1.0.3/;
./configure; make check;
examples/newbase60.w 123If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.
If you have additional questions, see the Frequently asked Questions (FAQ) and chat in #guile at freenode [27].
That’s it - have fun with wisp syntax [28]!
Update (2019-07-16): wisp-mode 0.2.5 [29] now provides proper indentation support in Emacs: Tab increases indentation and cycles back to zero. Shift-tab decreases indentation via previously defined indentation levels. Return preserves the indentation level (hit tab twice to go to zero indentation).
Update (2019-06-16): In c programming the uncommon way [30], specifically c-indent [31], tantalum is experimenting with combining wisp and sph-sc [32], which compiles scheme-like s-expressions to c. The result is a program written like this:pre-include "stdio.h" define (main argc argv) : int int char** declare i int printf "the number of arguments is %d\n" argc for : (set i 0) (< i argc) (set+ i 1) printf "arg %d is %s\n" (+ i 1) (array-get argv i) return 0 ;; code-snippet under GPLv3+To me that looks so close to C that it took me a moment to realize that it isn’t just using a parser which allows omitting some special syntax of C, but actually an implementation of a C-generator in Scheme (similar in spirit to cython, which generates C from Python), which results in code that looks like a more regular version of C without superfluous parens. Wisp really completes the round-trip from C over Scheme to something that looks like C but has all the regularity of Scheme, because all things considered, the code example is regular wisp-code. And it is awesome to see tantalum take up the tool I created and use it to experiment with ways to program that I never even imagined! ♡
TLDR: tantalum uses wisp [31] for code that looks like C and compiles to C but has the regularity of Scheme!
Update (2019-06-02): The repository at https://www.draketo.de/proj/wisp/ [33] is stale at the moment, because the staticsite extension [34] I use to update it was broken by API changes and I currently don’t have the time to fix it. Therefore until I get it fixed, the canonical repository for wisp is https://bitbucket.org/ArneBab/wisp/ [35]. I’m sorry for that. I would prefer to self-host it again, but the time to read up what i have to adjust blocks that right now (typically the actual fix only needs a few lines). A pull-request which fixes the staticsite extension [36] for modern Mercurial would be much appreciated!
Update (2019-02-08): wisp v1.0 [37] released as announced at FOSDEM [38]. Wisp the language is complete:display "Hello World!"
↦ (display "Hello World!")
And it achieves its goal:
“Wisp allows people to see code how Lispers perceive it. Its structure becomes apparent.” — Ricardo Wurmus at FOSDEM
Tooling, documentation, and porting of wisp are still work in progress, but before I go on, I want thank the people from the readable lisp project [39]. Without our initial shared path, and without their encouragement, wisp would not be here today. Thank you! You’re awesome!
With this release it is time to put wisp to use. To start your own project, see the tutorial Starting a wisp project [40] and the wisp tutorial [41]. For more info, see the NEWS file [42]. To test wisp v1.0, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-1.0.tar.gz;
tar xf wisp-1.0.tar.gz ; cd wisp-1.0/;
./configure; make check;
examples/newbase60.w 123
If you have additional questions, see the Frequently asked Questions (FAQ) and chat in #guile at freenode [27].
That’s it - have fun with wisp syntax [43]!
Update (2019-01-27): wisp v0.9.9.1 [44] released which includes the emacs support files missed in v0.9.9, but excludes unnecessary files which increased the release size from 500k to 9 MiB (it's now back at about 500k). To start your own wisp-project, see the tutorial Starting a wisp project [40] and the wisp tutorial [41]. For more info, see the NEWS file [45]. To test wisp v0.9.9.1, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.9.1.tar.gz;
tar xf wisp-0.9.9.1.tar.gz ; cd wisp-0.9.9.1/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2019-01-22): wisp v0.9.9 [47] released with support for literal arrays in Guile (needed for doctests), example start times below 100ms, ob-wisp.el for emacs org-mode babel and work on examples: network, securepassword, and downloadmesh. To start your own wisp-project, see the tutorial Starting a wisp project [40] and the wisp tutorial [41]. For more info, see the NEWS file [48]. To test wisp v0.9.9, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.9.tar.gz;
tar xf wisp-0.9.9.tar.gz ; cd wisp-0.9.9/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2018-06-26): There is now a wisp tutorial [41] for beginning programmers: “In this tutorial you will learn to write programs with wisp. It requires no prior knowledge of programming.” — Learn to program with Wisp [49], published in With Guise and Guile [50]
Update (2017-11-10): wisp v0.9.8 [51] released with installation fixes (thanks to benq!). To start your own wisp-project, see the tutorial Starting a wisp project [40]. For more info, see the NEWS file [52]. To test wisp v0.9.8, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.8.tar.gz;
tar xf wisp-0.9.8.tar.gz ; cd wisp-0.9.8/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2017-10-17): wisp v0.9.7 [53] released with bugfixes. To start your own wisp-project, see the tutorial Starting a wisp project [40]. For more info, see the NEWS file [54]. To test wisp v0.9.7, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.7.tar.gz;
tar xf wisp-0.9.7.tar.gz ; cd wisp-0.9.7/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2017-10-08): wisp v0.9.6 [55] released with compatibility for tests on OSX and old autotools, installation toguile/site/(guile version)/language/wispfor cleaner installation, debugging and warning when using not yet defined lower indentation levels, and withwisp-scheme.scmmoved tolanguage/wisp.scm. This allows creating a wisp project by simply copyinglanguage/. A short tutorial for creating a wisp project is available at Starting a wisp project [40] as part of With Guise and Guile [56]. For more info, see the NEWS file [57]. To test wisp v0.9.6, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.6.tar.gz;
tar xf wisp-0.9.6.tar.gz ; cd wisp-0.9.6/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2017-08-19): Thanks to tantalum, wisp is now available as package for Arch Linux [58]: from the Arch User Repository (AUR) as guile-wisp-hg [11]! Instructions for installing the package are provided on the AUR page in the Arch Linux wiki [59]. Thank you, tantalum!
Update (2017-08-20): wisp v0.9.2 [60] released with many additional examples including the proof-of-concept for a minimum ceremony dialog-based game duel.w [61] and the datatype benchmarks in benchmark.w [62]. For more info, see the NEWS file [63]. To test it, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.2.tar.gz;
tar xf wisp-0.9.2.tar.gz ; cd wisp-0.9.2/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2017-03-18): I removed the link to Gozala’s wisp, because it was put in maintenance mode. Quite the opposite of Guile which is taking up speed and just released Guile version 2.2.0 [64], fully compatible with wisp (though wisp helped to find and fix one compiler bug [65], which is something I’m really happy about ☺).
Update (2017-02-05): Allan C. Webber presented my talk Natural script writing with Guile [66] in the Guile devroom [67] at FOSDEM. The talk was awesome — and recorded! Enjoy Natural script writing with Guile by "pretend Arne" ☺
presentation (pdf, 16 slides) [69] and its source (org) [70].
Have fun with wisp syntax [46]!
Update (2016-07-12): wisp v0.9.1 [71] released with a fix for multiline strings and many additional examples. For more info, see the NEWS file [72]. To test it, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.1.tar.gz;
tar xf wisp-0.9.1.tar.gz ; cd wisp-0.9.1/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2016-01-30): I presented Wisp [73] in the Guile devroom [74] at FOSDEM. The reception was unexpectedly positive — given some of the backlash the readable project [39] got I expected an exceptionally sceptical audience, but people rather asked about ways to put Wisp to good use, for example in templates, whether it works in the REPL (yes, it does) and whether it could help people start into Scheme.The atmosphere in the Guile devroom was very constructive and friendly during all talks, and I’m happy I could meet the Hackers there in person. I’m definitely taking good memories with me. Sadly the video did not make it, but the schedule-page [73] includes the presentation (pdf, 10 slides) [81] and its source (org) [82].Wisp is ”The power and simplicity of #lisp [75] with the familiar syntax of #python [76]” talk by @ArneBab [77] #fosdem [78] pic.twitter.com/TaGhIGruIU [79]
— Jan Nieuwenhuizen (@JANieuwenhuizen) January 30, 2016 [80]
Have fun with wisp syntax [46]!
Update (2016-01-04): Wisp is available in GNU Guix [83]! Thanks to the package [84] from Christopher Webber you can try Wisp easily on top of any distribution:
This already gives you Wisp at the REPL (take care to follow all instructions for installing Guix on top of another distro, especially the locales).guix package -i guile guile-wisp
guile --language=wisp
Have fun with wisp syntax [46]!
Update (2015-10-01): wisp v0.9.0 [85] released which no longer depends on Python for bootstrapping releases (but ./configure still asks for it — a fix for another day). And thanks to Christopher Webber there is now a patch [86] to install wisp within GNU Guix [83]. For more info, see the NEWS file [72]. To test it, install Guile 2.0.11 or later [25] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.0.tar.gz;
tar xf wisp-0.9.0.tar.gz ; cd wisp-0.9.0/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]!
Update (2015-09-12): wisp v0.8.6 [87] released with fixed macros in interpreted code, chunking by top-level forms,: .parsed as nothing, ending chunks with a trailing period, updated example evolve [88] and added examples newbase60 [89], cli [90], cholesky decomposition [91], closure [92] and hoist in loop [93]. For more info, see the NEWS file [72].To test it, install Guile 2.0.x or 2.2.x [25] and Python 3 [94] and bootstrap wisp:
If it prints 23 (123 in NewBase60 [26]), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.6.tar.gz;
tar xf wisp-0.8.6.tar.gz ; cd wisp-0.8.6/;
./configure; make check;
examples/newbase60.w 123
That’s it - have fun with wisp syntax [46]! And a happy time together for the ones who merge their paths today ☺
Update (2015-04-10): wisp v0.8.3 [95] released with line information in backtraces. For more info, see the NEWS file [72].To test it, install Guile 2.0.x or 2.2.x [25] and Python 3 [94] and bootstrap wisp:
If it prints 120120 (two times 120, the factorial of 5), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.3.tar.gz;
tar xf wisp-0.8.3.tar.gz ; cd wisp-0.8.3/;
./configure; make check;
guile -L . --language=wisp tests/factorial.w; echo
That’s it - have fun with wisp syntax [46]!
Update (2015-03-18): wisp v0.8.2 [96] released with reader bugfixes, new examples [97] and an updated draft for SRFI 119 (wisp) [98]. For more info, see the NEWS file [72].To test it, install Guile 2.0.x or 2.2.x [25] and Python 3 [94] and bootstrap wisp:
If it prints 120120 (two times 120, the factorial of 5), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.2.tar.gz;
tar xf wisp-0.8.2.tar.gz ; cd wisp-0.8.2/;
./configure; make check;
guile -L . --language=wisp tests/factorial.w; echo
That’s it - have fun with wisp syntax [46]!
Update (2015-02-03): The wisp SRFI just got into draft state: SRFI-119 [98] — on its way to an official Scheme Request For Implementation!
Update (2014-11-19): wisp v0.8.1 [99] released with reader bugfixes. To test it, install Guile 2.0.x [25] and Python 3 [94] and bootstrap wisp:
If it prints 120120 (two times 120, the factorial of 5), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.1.tar.gz;
tar xf wisp-0.8.1.tar.gz ; cd wisp-0.8.1/;
./configure; make check;
guile -L . --language=wisp tests/factorial.w; echo
That’s it - have fun with wisp syntax [46]!
Update (2014-11-06): wisp v0.8.0 [100] released! The new parser now passes the testsuite and wisp files can be executed directly. For more details, see the NEWS [101] file. To test it, install Guile 2.0.x [25] and bootstrap wisp:
If it prints 120120 (two times 120, the factorial of 5), your wisp is fully operational.wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.0.tar.gz;
tar xf wisp-0.8.0.tar.gz ; cd wisp-0.8.0/;
./configure; make check;
guile -L . --language=wisp tests/factorial.w;
echo
That’s it - have fun with wisp syntax [46]!
On a personal note: It’s mindboggling that I could get this far! This is actually a fully bootstrapped indentation sensitive programming language with all the power of Scheme [102] underneath, and it’s a one-person when-my-wife-and-children-sleep sideproject. The extensibility of Guile [25] is awesome!
Update (2014-10-17): wisp v0.6.6 [103] has a new implementation of the parser which now uses the scheme read function. `wisp-scheme.w` parses directly to a scheme syntax-tree instead of a scheme file to be more suitable to an SRFI. For more details, see the NEWS [104] file. To test it, install Guile 2.0.x [25] and bootstrap wisp:
That’s it - have fun with wisp syntax [46] at the REPL!wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.6.6.tar.gz;
tar xf wisp-0.6.6.tar.gz; cd wisp-0.6.6;
./configure; make;
guile -L . --language=wisp
Caveat: It does not support the ' prefix yet (syntax point 4).
Update (2014-01-04): Resolved the name-clash together with Steve Purcell und Kris Jenkins: the javascript wisp-mode was renamed to wispjs-mode [105] and wisp.el is called wisp-mode 0.1.5 [106] again. It provides syntax highlighting for Emacs and minimal indentation support via tab. You can install it with `M-x package-install wisp-mode`
Update (2014-01-03): wisp-mode.el was renamed to wisp 0.1.4 [107] to avoid a name clash with wisp-mode for the javascript-based wisp.
Update (2013-09-13): Wisp now has a REPL! Thanks go to GNU Guile [25] and especially Mark Weaver, who guided me through the process (along with nalaginrut who answered my first clueless questions…).
To test the REPL, get the current code snapshot [108], unpack it, run./bootstrap.sh, start guile with$ guile -L .(requires guile 2.x) and enter,language wisp.
Example usage:then hit enter thrice.display "Hello World!\n"
Voilà, you have wisp at the REPL!
Caveeat: the wisp-parser is still experimental and contains known bugs. Use it for testing, but please do not rely on it for important stuff, yet.
Update (2013-09-10): wisp-guile.w can now parse itself [109]! Bootstrapping: The magical feeling of seeing a language (dialect) grow up to live by itself:python3 wisp.py wisp-guile.w > 1 && guile 1 wisp-guile.w > 2 && guile 2 wisp-guile.w > 3 && diff 2 3. Starting today, wisp is implemented in wisp.
Update (2013-08-08): Wisp 0.3.1 [110] released (Changelog [111]).
Wisp is a simple preprocessor which turns indentation sensitive syntax into Lisp syntax.
The basic goal is to create the simplest possible indentation based syntax which is able to express all possibilities of Lisp.
Basically it works by inferring the parentheses of lisp by reading the indentation of lines.
It is related to SRFI-49 [112] and the readable Lisp S-expressions Project [39] (and actually inspired by the latter), but it tries to Keep it Simple and Stupid: wisp is a simple preprocessor which can be called by any lisp implementation to add support for indentation sensitive syntax. To repeat the initial quote:
I love the syntax of Python, but crave the simplicity and power of Lisp.
With wisp I hope to make it possible to create lisp code which is easily readable for non-programmers (and me!) and at the same time keeps the simplicity and power of Lisp.
Its main technical improvement over SRFI-49 and Project Readable is using lines prefixed by a dot (". ") to mark the continuation of the parameters of a function after intermediate function calls.
The dot-syntax means, instead of marking every function call, it marks every line which does not begin with a function call - which is the much less common case in lisp-code.
See the Updates for information how to get the current version of wisp.
Enter in Enter three witches [113].
display "Hello World!" ↦ (display "Hello World!")
display ↦ (display string-append "Hello " "World!" ↦ (string-append "Hello " "World!"))
display ↦ (display string-append "Hello " "World!" ↦ (string-append "Hello " "World!")) display "Hello Again!" ↦ (display "Hello Again!")
' "Hello World!" ↦ '("Hello World!")
string-append "Hello" ↦ (string-append "Hello" string-append " " "World" ↦ (string-append " " "World") . "!" ↦ "!")
let ↦ (let : ↦ ((msg "Hello World!")) msg "Hello World!" ↦ (display msg)) display msg ↦
define : hello who ↦ (define (hello who) display ↦ (display string-append "Hello " who "!" ↦ (string-append "Hello " who "!")))
define : hello who ↦ (define (hello who) _ display ↦ (display ___ string-append "Hello " who "!" ↦ (string-append "Hello " who "!")))
To make that easier to understand, let’s just look at the examples in more detail:
display "Hello World!" ↦ (display "Hello World!")
This one is easy: Just add a bracket before and after the content.
display "Hello World!" ↦ (display "Hello World!") display "Hello Again!" ↦ (display "Hello Again!")
Multiple lines with the same indentation are separate function calls (except if one of them starts with ". ", see Continue arguments, shown in a few lines).
display ↦ (display string-append "Hello " "World!" ↦ (string-append "Hello " "World!"))
If a line is more indented than a previous line, it is a sibling to the previous function: The brackets of the previous function gets closed after the (last) sibling line.
By using a . followed by a space as the first non-whitespace character on a line, you can mark it as continuation of the previous less-indented line. Then it is no function call but continues the list of parameters of the funtcion.
I use a very synthetic example here to avoid introducing additional unrelated concepts.
string-append "Hello" ↦ (string-append "Hello" string-append " " "World" ↦ (string-append " " "World") . "!" ↦ "!")
As you can see, the final "!" is not treated as a function call but as parameter to the first string-append.
This syntax extends the notion of the dot as identity function. In many lisp implementations1 we already have `(= a (. a))`.
= a ↦ (= a . a ↦ (. a))
With wisp, we extend that equality to `(= '(a b c) '((. a b c)))`.
. a b c ↦ a b c
If you use `let`, you often need double brackets. Since using pure indentation in empty lines would be really error-prone, we need a way to mark a line as indentation level.
To add multiple brackets, we use a colon to mark an intermediate line as additional indentation level.
let ↦ (let : ↦ ((msg "Hello World!")) msg "Hello World!" ↦ (display msg)) display msg ↦
Since we already use the colon as syntax element, we can make it possible to use it everywhere to open a bracket - even within a line containing other code. Since wide unicode characters would make it hard to find the indentation of that colon, such an inline-function call always ends at the end of the line. Practically that means, the opened bracket of an inline colon always gets closed at the end of the line.
define : hello who ↦ (define (hello who) display : string-append "Hello " who "!" ↦ (display (string-append "Hello " who "!")))
This also allows using inline-let:
let ↦ (let : msg "Hello World!" ↦ ((msg "Hello World!")) display msg ↦ (display msg))
and can be stacked for more compact code:
let : : msg "Hello World!" ↦ (let ((msg "Hello World!")) display msg ↦ (display msg))
To make the indentation visible in non-whitespace-preserving environments like badly written html, you can replace any number of consecutive initial spaces by underscores, as long as at least one whitespace is left between the underscores and any following character. You can escape initial underscores by prefixing the first one with \ ("\___ a" → "(___ a)"), if you have to use them as function names.
define : hello who ↦ (define (hello who) _ display ↦ (display ___ string-append "Hello " who "!" ↦ (string-append "Hello " who "!")))
I do not like adding any unnecessary syntax element to lisp. So I want to show explicitely why the syntax elements are required to meet the goal of wisp: indentation-based lisp with a simple preprocessor.
We have to be able to continue the arguments of a function after a call to a function, and we must be able to split the arguments over multiple lines. That’s what the leading dot allows. Also the dot at the beginning of the line as marker of the continuation of a variable list is a generalization of using the dot as identity function - which is an implementation detail in many lisps.
`(. a)` is just `a`.
So for the single variable case, this would not even need additional parsing: wisp could just parse ". a" to "(. a)" and produce the correct result in most lisps. But forcing programmers to always use separate lines for each parameter would be very inconvenient, so the definition of the dot at the beginning of the line is extended to mean “take every element in this line as parameter to the parent function”.
Essentially this dot-rule means that we mark variables at the beginning of lines instead of marking function calls, since in Lisp variables at the beginning of a line are much rarer than in other programming languages. In Lisp, assigning a value to a variable is a function call while it is a syntax element in many other languages. What would be a variable at the beginning of a line in other languages is a function call in Lisp.
(Optimize for the common case, not for the rare case)
For double brackets and for some other cases we must have a way to mark indentation levels without any code. I chose the colon, because it is the most common non-alpha-numeric character in normal prose which is not already reserved as syntax by lisp when it is surrounded by whitespace, and because it already gets used for marking keyword arguments to functions in Emacs Lisp, so it does not add completely alien characters.
The function call via inline " : " is a limited generalization of using the colon to mark an indentation level: If we add a syntax-element, we should use it as widely as possible to justify the added syntax overhead.
But if you need to use : as variable or function name, you can still do that by escaping it with a backslash (example: "\:"), so this does not forbid using the character.
In Python the whitespace hostile html already presents problems with sharing code - for example in email list archives and forums. But in Python the indentation can mostly be inferred by looking at the previous line: If that ends with a colon, the next line must be more indented (there is nothing to clearly mark reduced indentation, though). In wisp we do not have this help, so we need a way to survive in that hostile environment.
The underscore is commonly used to denote a space in URLs, where spaces are inconvenient, but it is rarely used in lisp (where the dash ("-") is mostly used instead), so it seems like a a natural choice.
You can still use underscores anywhere but at the beginning of the line. If you want to use it at the beginning of the line you can simply escape it by prefixing the first underscore with a backslash (example: "\___").
A few months ago I found the readable Lisp project [39] which aims at producing indentation based lisp, and I was thrilled. I had already done a small experiment with an indentation to lisp parser, but I was more than willing to throw out my crappy code for the well-integrated parser they had.
Fast forward half a year. It’s February 2013 and I started reading the readable list again after being out of touch for a few months because the birth of my daughter left little time for side-projects. And I was shocked to see that the readable folks had piled lots of additional syntax elements on their beautiful core model, which for me destroyed the simplicity and beauty of lisp. When language programmers add syntax using \\, $ and <>, you can be sure that it is no simple lisp anymore. To me readability does not just mean beautiful code, but rather easy to understand code with simple concepts which are used consistently. I prefer having some ugly corner cases to adding more syntax which makes the whole language more complex.
I told them about that [114] and proposed a simpler structure which achieved almost the same as their complex structure. To my horror they proposed adding my proposal to readable, making it even more bloated (in my opinion). We discussed a long time - the current syntax for inline-colons is a direct result of that discussion in the readable list - then Alan wrote me a nice mail [115], explaining that readable will keep its direction. He finished with «We hope you continue to work with or on indentation-based syntaxes for Lisp, whether sweet-expressions, your current proposal, or some other future notation you can develop.»
It took me about a month to answer him, but the thought never left my mind (@Alan: See what you did? You anchored the thought of indentation based lisp even deeper in my mind. As if I did not already have too many side-projects… :)).
Then I had finished the first version of a simple whitespace-to-lisp preprocessor.
And today I added support for reading indentation based lisp from standard input which allows actually using it as in-process preprocessor without needing temporary files, so I think it is time for a real release outside my Mercurial repository [116].
So: Have fun with wisp v0.2 (tarball) [117]!
PS: Wisp is linked in the comparisions of SRFI-110 [118].
| Anhang | Größe |
|---|---|
| wisp-1.0.3.tar_.gz [19] | 756.71 KB |
Update: The recording is now online at ftp.fau.de/fosdem/2017/K.4.601/naturalscriptwritingguile.vp8.webm [119]
Here’s the stream to the Guile [25] devroom at #FOSDEM: https://live.fosdem.org/watch/k4601 [120]
Schedule (also on the FOSDEM page [67]):
Every one of these talks sounds awesome! Here’s where we get deep.
Update 2020: In Dryads Wake [121] I am starting a game using the way presented here to write dialogue-focused games with minimal ceremony. Demo: https://dryads-wake.1w6.org [122]
Update 2018: Bitbucket is dead to me. You can find the source at https://hg.sr.ht/~arnebab/ews [123]
Update 2017: A matured version of the work shown here was presented at FOSDEM 2017 as Natural script writing with Guile [66]. There is also a video of the presentation [119] (held by Chris Allan Webber; more info… [124]). Happy Hacking!
Programming languages allow expressing ideas in non-ambiguous ways. Let’s do a play.
say Yes, I do!
Yes, I do!
This is a sketch of applying Wisp [125] to a pet issue of mine: Writing the story of games with minimal syntax overhead, but still using a full-fledged programming language. My previous try was the TextRPG [126], using Python. It was fully usable. This experiment drafts a solution to show how much more is possible with Guile Scheme using Wisp syntax (also known an SRFI-119 [98]).
To follow the code here, you need Guile 2.0.11 [25] on a GNU Linux system. Then you can install Wisp and start a REPL with
wget https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.6.tar.gz
tar xf wi*z; cd wi*/; ./c*e; make check; guile -L . --language=wisp
For finding minimal syntax, the first thing to do is to look at how such a structure would be written for humans. Let’s take the obvious and use Shakespeare: Macbeth, Act 1, Scene 1 [127] (also it’s public domain, so we avoid all copyright issues). Note that in the original, the second and last non-empty line are shown as italic.
SCENE I. A desert place.
Thunder and lightning. Enter three Witches
First Witch
When shall we three meet again
In thunder, lightning, or in rain?
Second Witch
When the hurlyburly's done,
When the battle's lost and won.
Third Witch
That will be ere the set of sun.
First Witch
Where the place?
Second Witch
Upon the heath.
Third Witch
There to meet with Macbeth.
First Witch
I come, Graymalkin!
Second Witch
Paddock calls.
Third Witch
Anon.
ALL
Fair is foul, and foul is fair:
Hover through the fog and filthy air.
Exeunt
Let’s analyze this: A scene header, a scene description with a list of people, then the simple format
person
something said
and something more
For this draft, it should suffice to reproduce this format with a full fledged programming language.
This is how our code should look:
First Witch
When shall we three meet again
In thunder, lightning, or in rain?
As a first step, let’s see how code which simply prints this would look in plain Wisp. The simplest way would just use a multiline string:
display "First Witch When shall we three meet again In thunder, lightning, or in rain?\n"
That works, but it’s not really nice. For one thing, the program does not have any of the semantic information a human would have, so if we wanted to show the First Witch in a different color than the Second Witch, we’d already be lost. Also throwing everything in a string might work, but when we need highlighting of certain parts, it gets ugly: We actually have to do string parsing by hand.
But this is Scheme, so there’s a better way. We can go as far as writing the sentences plainly, if we add a macro which grabs the variable names for us. We can do a simple form of this in just six short lines:
define-syntax-rule : First_Witch a ... format #t "~A\n" string-join map : lambda (x) (string-join (map symbol->string x)) quote : a ... . "\n"
This already gives us the following syntax:
First_Witch When shall we three meet again In thunder, lightning, or in rain?
which prints
When shall we three meet again
In thunder, lightning, or in rain?
Note that :, . and , are only special when they are preceded by
whitespace or are the first elements on a line, so we can freely use
them here.
To polish the code, we could get rid of the underscore by treating
everything on the first line as part of the character (indented lines
are sublists of the main list, so a recursive syntax-case [128] macro can
distinguish them easily), and we could add highlighting with
comma-prefixed parens (via standard Scheme preprocessing these get
transformed into (unquote (...))). Finally we could add a macro for
the scene, which creates these specialized parsers for all persons.
A completed parser could then read input files like the following:
SCENE I. A desert place. Thunder and lightning. Enter : First Witch Second Witch Third Witch First Witch When shall ,(emphasized we three) meet again In thunder, lightning, or in rain? Second Witch When the hurlyburly's done, When the battle's lost and won. ; ... ALL Fair is foul, and foul is fair: Hover through the fog and filthy air. action Exeunt
And with that the solution is sketched. I hope it was interesting for you to see how easy it is to create this!
Note also that this is not just a specialized text-parser. It provides access to all of Guile Scheme, so if you need interactivity or something like the branching story [129] from TextRPG, scene writers can easily add it without requiring help from the core system. That’s part of the Freedom for Developers from the language implementors which is at the core of GNU Guile [25].
Don’t use this as data interchange format for things downloaded from the web, though: It does give access to a full Turing complete language. That’s part of its power which allows you to realize a simple syntax without having to implementent all kinds of specialized features which are needed for only one or two scenes. If you want to exchange the stories, better create a restricted interchange-format which can be exported from scenes written in the general format. Use lossy serializiation to protect your users.
And that’s all I wanted to say ☺
Happy Hacking!
PS: For another use of Shakespeare in programming languages, see the Shakespeare programming language [130]. Where this article uses Wisp [131] as a very low ceremony language to represent very high level concepts, the Shapespeare programming language takes the opposite approach by providing an extremely high-ceremony language for very low-level concepts. Thanks to ZMeson [132] for reminding me ☺
| Anhang | Größe |
|---|---|
| 2015-09-12-Sa-Guile-scheme-wisp-for-low-ceremony-languages.org [133] | 6.35 KB |
| enter-three-witches.w [134] | 1.23 KB |
 [135]
[135]Python is the first language I loved. I dreamt in Python, I planned in Python, I thought I would never need anything else.
- Free: html [136] | pdf [137]
- Softcover: 14.95 € [135]
with pdf, epub, mobi
- Source: download [138]
free licensed under GPL
Update 2025: I published the libre book Naming & Logic: programming essentials with Scheme [139], a quick start into Guile Scheme. It gets you from your first
defineto deploying your application, either as a server, or as web assembly, or as binaries. Thanks to the minimalism of Scheme, it just needs 64 DinA6 pages while teaching programming with the best practices I found in a decade of using Guile Scheme.
Python is a language where I can teach a handful of APIs and cause people to learn most of the language as a whole. — Raymond Hettinger (2011-06-20) [140]
Why, I feel all thin, sort of stretched if you know what I mean: like butter that has been scraped over too much bread. — Bilbo Baggins in “The Lord of the Rings”
You must unlearn what you have learned. — Yoda in “The Empire Strikes Back“
Guile Scheme [25] is the official GNU extension language, used for example in GNU Cash [141] and GNU Guix [83] and the awesome Lilypond [142].
Every sufficiently complex application/language/tool will either have to use Lisp or reinvent it the hard way. — Greenspuns 10th rule [143]
As free cultural work [144], py2guile is licensed under the GPLv3 or later [145]. You are free to share, change, remix and even to resell it as long as you say that it’s from me (attribution) and provide the whole corresponding source under the GPL (sharealike).
For instructions on building the ebook yourself, see the README in the source.
Happy Hacking!
— Arne Babenhauserheide
[146]py2guile [146] is a book I wrote about Python and Guile Scheme. It’s selling at 14.95 € [147] for the printed softcover.
To fight the new german data retention laws, you can get the ebook gratis: Just install Hyphanet [148], then the following links work:
Escape total surveillance and get an ebook about the official GNU extension language for free today!
[137]Python is the first language I loved. I dreamt in Python, I planned in Python, I thought I would never need anything else.
Download “Python to Guile” (pdf) [137]
You can read more about this on the Mercurial mailing list [153].
- Free: html [136] | pdf [137]
preview edition
(complete)
Yes, this means that with Guile I will contribute to a language developed via Git, but it won’t be using a proprietary platform.
If you like py2guile, please consider buying the book:
- Softcover: 14.95 € [147]
with digital companion
- Source: download [138]
free licensed under GPL
More information: draketo.de/py2guile [154]
I was curious why this happened so I read through PEP 0481. It's interesting that Git was chosen to replace Mercurial due to Git's greater popularity, yet a technical comparison was deemed as subjective. In fact, no actual comparison (of any kind) was discussed. What a shame. — Emmanuel Rosa on G+ [155]
yes. And the popularity contest wasn’t done in any robust way — they present values between 3x as popular and 18x as popular. That is a crazy margin of error — especially for a value on which to base a very disrupting decision. — my answer
Yesterday Python maintainers chose to move to GitHub and Git. Python is now developed using a C-based tool on a Ruby-based, unfree platform. And that changed my view on what’s happening in the community. Python no longer fosters its children and it even stopped dogfooding where its tools are as good as or better than other tools. I don’t think it will die. But I don’t bet on it for the future anymore. — EDIT to my answer on Quora [156] “is Python a dying language?” which originally stated “it’s not dying, it’s maturing”.
The PEP for github hedges somewhat by using github for code but not bug tracker. Not ideal considering BitKeeper, but a full on coup for GitHub. — Martin Owens
that’s something like basic self-defense, but my experience with projects who moved to GitHub is that GitHub soon starts to invade your workflows, changing your cooperation habits. At some point people realize that they can’t work well without GitHub anymore.
Not becoming dependent on GitHub while using it requires constant vigilance. Seeing how Python already switched to Git and GitHub because existing infrastructure wasn’t maintained does not sound like they will be able or willing to put in the work to keep independent. — my answer on G+ [157]
I was already pretty disappointed when I heard that Python is moving to Git. Seeing it choose the proprietary platform is an even sadder choice from my perspective. Two indicators for a breakage in the culture of the project.
For me that’s a reason to leave Python. Though it’s not like I did not get a foreboding of that. It’s why I started learning Guile Scheme in 2013 — and wrote about the experience.
I will still use Python for many practical tasks — it acquired the momentum for that, especially in science (I was a champion for Python in the institute, which is now replacing Matlab and IDL for many people here, and I will be teaching Python starting two weeks from now). I think it will stay strong for many years; a good language to start and a robust base for existing programs. But with what I learned the past years, Python is no longer where I place my bets. — slightly adjusted version of my post on the Mercurial mailing list [153].
(this is taken from a message I wrote to Brett, so I don’t have to say later that I stayed silent while Python went down. I got a nice answer, and despite the disagreement we said a friendly good bye)
Back when I saw that Python might move to git, I silently resigned and stopped caring to some degree. I have seen a few projects move to Git in the past years (and in every project problems remained even years after the switch), so when it came to cPython, the quarrel with git-fans just didn’t feel worthwhile anymore.
Seeing Python choose GitHub with the notion of “git is 3x to 18x more popular than Mercurial and free solutions aren’t better than GitHub” makes me lose my trust in the core development community, though.
PEP 481 states, that it is about the quality of the tooling, but it names the popularity numbers quite prominently: python.org/dev/peps/pep-0481/ [158]
If they are not relevant, they shouldn’t be included, but they are included, so they seem to be relevant to the decision. And “the best tooling” is mostly subjective, too — which is shown in the PEP itself which mostly talks about popularity, not quality. It even goes into length about how to avoid many of the features of GitHub.
I’ve seen quite a few projects try to avoid lock-in to GitHub. None succeeded. Not even in one where two of about six active developers were deeply annoyed by GitHub. This is exactly what the scipy part of the PEP describes: lock-in due to group effects.
Finally, using hg-git is by far not seamless. I use it for several projects, and when the repositories become big (as cPython’s is), the overhead of the conversion becomes a major hassle. It works, but native Mercurial would be much more efficient. When pushing takes minutes, you start to think twice about whether you’ll just do the quick fix right now. Not to forget that at some point people start to demand signing of commits in git-style (not possible with hg-git, you can only sign commits mercurial-style) as well as other gitologisms (which have an analogue in Mercurial but aren’t converted by hg-git).
Despite my disappointment, I wish you all the best. Python is a really cool language. It’s the first one I loved and will always stay dear to me, so I’m happy that you work on it — and I hope you keep it up.
So, I think this is goodbye. A bit melancholic, but that’s how that goes.
Good luck to you in your endeavors,
Arne Babenhauserheide
And that’s enough negativity from me.
Thank you, Brett, for reminding me that even though we might disagree, it’s important to remember that people in the project are hit by negativity much harder than it feels for the one who writes.
For my readers: If that also happened to you one time or the other, please read his article:
Thank you, Brett. Despite everything I wrote here, I still think that Python is a great project, and it got many things right — some of which are things which are at least as important as code but much less visible, like having a large, friendly community.
I’m happy that Python exists, and I hope that it keeps going. And where I use programming to make a living, I’m glad when I can do it in Python. Despite all my criticism, I consider Python as the best choice for many tasks, and this is also written in py2guile [146]: almost the the first half of the book talks about the strengths of Python. Essentially I could not criticize Python as strongly as I’m doing it here if I did not like it so much. Keep that in mind when you think about what you read.
Also Brett now published an article where he details his decision to move to GitHub. It is a good read: The history behind the decision to move Python to GitHub — Or, why it took over a year for me to make a decision [160]
It's often said, that Gentoo is all about choice, but that doesn't quite fit what it is for me.
After all, the highest ability to choose is Linux from scratch and I can have any amount of choice in every distribution by just going deep enough (and investing enough time).
What really distinguishes Gentoo for me is that it makes it convenient to choose.
Since we all have a limited time budget, many of us only have real freedom to choose, because we use Gentoo which makes it possible to choose with the distribution-tools. Therefore only calling it “choice” doesn't ring true in general - it misses the reason, why we can choose.
So what Gentoo gives me is not just choice, but convenient choice.
Some examples to illustrate the point:
I recently rebuilt my system after deciding to switch my disk layout (away from reiserfs towards a simple ext3 with reiser4 for the portage tree). When doing so I decided to try to use a "pure" KDE 4 - that means, a KDE 4 without any remains from KDE3 or qt3.
To use kde without any qt3 applications, I just had to put "-qt3" and "-qt3support" into my useflags in /etc/make.conf and "emerge -uDN world" (and solve any arising conflicts).
Imagine doing the same with a (K)Ubuntu...
Similarly to enable emacs support on my GentooXO (for all programs which can have emacs support), I just had to add the "emacs" useflag and "emerge -uDN world".
Just add
ACCEPT_LICENSE="-* @FSF-APPROVED @FSF-APPROVED-OTHER"
to your /etc/make.conf to make sure you only get software under licenses which are approved by the FSF.
For only free licenses (regardless of the approved state) you can use:
ACCEPT_LICENSE="-* @FREE"
All others get marked as masked by license. Default (no ACCEPT_LICENSE in /etc/make.conf) is “* -@EULA”: No unfree software. You can check your setting via emerge --info | grep ACCEPT_LICENSE. More information… [161]
Another part where choosing is made convenient in Gentoo are testing and unstable programs.
I remember my pain with a Kubuntu, where I wanted to use the most recent version of Amarok. I either had to add a dedicated Amarok-only testing repository (which I'd need for every single testing program), or I had to switch my whole system into testing. I did the latter and my graphical package manager ceased to work. Just imagine how quickly I ran back to Gentoo.
And then have a look at the ease of deciding to take one package into testing in Gentoo:
EDIT: Once I had a note here “It would be nice to be able to just add the missing dependencies with one call”. This is now possible with --autounmask-write.
And for some special parts (like KDE 4) I can easily say something like
(I don't have the kde-testing overlay on my GentooXO, where I write this post, so the exact command might vary slightly)
So to finish this post: For me, Gentoo is not only about choice. It is about convenient choice.
And that means: Gentoo gives everybody the power to choose.
I hope you enjoy it as I do!
Update 2016: I nowadays just use
emerge --sync; emerge @security
To keep my Gentoo up to date, I use daily and weekly update scripts which also always run revdep-rebuild after the saturday night update :)
My daily update is via pkgcore [163] to pull in all important security updates:
pmerge @glsa
That pulls in the Gentoo Linux Security Advisories - important updates with mostly short compile time. (You need pkgcore for that: "emerge pkgcore")
Also I use two cron scripts.
Note: It might be useful to add the lafilefixer to these scripts (source [164]).
The following is my daily update (in /etc/cron.daily/update_glsa_programs.cron )
\#! /bin/sh
\### Update the portage tree and the glsa packages via pkgcore
\# spew a status message
echo $(date) "start to update GLSA" >> /tmp/cron-update.log
\# Sync only portage
pmaint sync /usr/portage
\# security relevant programs
pmerge -uDN @glsa > /tmp/cron-update-pkgcore-last.log || cat \
/tmp/cron-update-pkgcore-last.log >> /tmp/cron-update.log
\# And keep everything working
revdep-rebuild
\# Finally update all configs which can be updated automatically
cfg-update -au
echo $(date) "finished updating GLSA" >> /tmp/cron-update.log
And here's my weekly cron - executed every saturday night (in /etc/cron.weekly/update_installed_programs.cron ):
\#!/bin/sh \### Update my computer using pgkcore, \### since that also works if some dependencies couldn't be resolved. \# Sync all overlays eix-sync \## First use pkgcore \# security relevant programs (with build-time dependencies (-B)) pmerge -BuD @glsa \# system, world and all the rest pmerge -BuD @system pmerge -BuD @world pmerge -BuD @installed \# Then use portage for packages pkgcore misses (inlcuding overlays) \# and for *EMERGE_DEFAULT_OPTS="--keep-going"* in make.conf emerge -uD @security emerge -uD @system emerge -uD @world emerge -uD @installed \# And keep everything working emerge @preserved-rebuild revdep-rebuild \# Finally update all configs which can be updated automatically cfg-update -au
For a long time it bugged me, that eix uses a seperate database which I need to keep up to date. But no longer: With pkgcore [163] as fast as it is today, I set up pquery to replace eix.
The result is pix:
alias pix='pquery --raw -nv --attr=keywords'
(put the above in your ~/.bashrc)
The output looks like this:
$ pix pkgcore
* sys-apps/pkgcore
versions: 0.5.11.6 0.5.11.7
installed: 0.5.11.7
repo: gentoo
description: pkgcore package manager
homepage: http://www.pkgcore.org [165]
keywords: ~alpha ~amd64 ~arm ~hppa ~ia64 ~ppc ~ppc64 ~s390 ~sh ~sparc ~x86
It’s still a bit slower than eix, but it operates directly on the portage tree and my overlays — and I no longer have to use eix-sync for syncing my overlays, just to make sure eix is updated.
Aside from pquery, pkgcore also offers pmerge to install packages (almost the same syntax as emerge) and pmaint for synchronizing and other maintenance stuff.
From my experience, pmerge is hellishly fast for simple installs like pmerge kde-misc/pyrad, but it sometimes breaks with world updates. In that case I just fall back on portage. Both are Python, so when you have one, adding the other is very cheap (spacewise).
Also pmerge has the nice pmerge @glsa feature: Get Gentoo Linux security updates. Due to it’s almost unreal speed (compared to portage) checking for security updates now doesn’t hurt anymore.
$ time pmerge -p @glsa
* Resolving...
Nothing to merge.
real 0m1.863s
user 0m1.463s
sys 0m0.100s
It differs from portage in that you call world as set explicitely — either via a command like pmerge -aus world or via pmerge -au @world.
pmaint on the other hand is my new overlay and tree synchronizer. Just call pmaint sync to sync all, or pmaint sync /usr/portage to sync only the given overlay (in this case the portage tree).
Using pix as replacement of eix isn’t yet perfect. You might hit some of the following:
pix always shows all packages in the tree and the overlays. The keywords are only valid for the highest version, though. marienz from #pkgcore on irc.freenode.net is working on fixing that.
If you only want to see the packages which you can install right away, just use pquery -nv. pix is intended to mimik eix as closely as possible, so I don’t have to change my habits ;) If it doesn’t fit your needs, just change the alias.
To search only in your installed packages, you can use pquery --vdb -nv.
Sometimes pquery might miss something in very broken overlay setups (like my very grown one). In that case, please report the error in the bugtracker [166] or at #pkgcore on irc.freenode.net:
23:27 <marienz> if they're reported on irc they're probably either
fixed pretty quickly or they're forgotten
23:27 <marienz> if they're reported in the tracker they're harder
to forget but it may take longer before they're
noticed
I hope my text helps you in changing your Gentoo system further towards the system which fits you best!
If the video doesn’t show, you can also download it as Ogg Theora & Vorbis “.ogv” [167] or find it on youtube [168].
This video shows the activity of the Hurd coders and answers some common questions about the Hurd, including “How stagnated is Hurd compared to Duke Nukem Forever?”. It is created directly from commits to Hurd repositories, processed by community codeswarm [170].
Every shimmering dot is a change to a file. These dots align around the coder who did the change. The questions and answers are quotes from todays IRC discussions (2010-07-13) in #hurd at irc.freenode.net.
You can clearly see the influx of developers in 2003/2004 and then again a strenthening of the development in 2008 with less participants but higher activity than 2003 (though a part of that change likely comes from the switch to git with generally more but smaller commits).
I hope you enjoyed the high-level look on the activity of the Hurd project [171]!
PS: The last part is only the information title with music to honor Sean Wright [172] for allowing everyone to use and adapt his Album Enchanted [173].
→ An answer to just accept it, truth hurds [174], where Flameeyes told his reasons for not liking the Hurd and asked for technical advantages (and claimed, that the Hurd does not offer a concept which got incorporated into other free software, contributing to other projects). Note: These are the points I see. Very likely there are more technical advantages which I don’t see well enough to explain them.
The translator system in the Hurd is a simple concept that makes many tasks easy, which are complex with Linux (like init, network transparency, new filesystems, …). Additionally there are capabilities (give programs only the access they need - adjusted at runtime), subhurds and (academic) memory management.
Information for potential testers: The Hurd is already usable, but it is not yet in production state. It progressed a lot during the recent years, though. Have a look at the status report [175] if you want to see if it’s already interesting for you. See running the Hurd [176] for testing it yourself.
Table of Contents:
Firstoff: FUSE [187] is essentially an implementation of parts of the translator system [188] (which is the main building block of the Hurd [171]) to Linux, and NetBSD recently got a port of the translators system of the Hurd [189]. That’s the main contribution to other projects that I see.
As an update in 2015: A pretty interesting development in the past few years is that the systemd developers have been bolting features onto Linux which the Hurd already provided 15 years ago. Examples: socket-activation provides on-demand startup like passive translators, but as crude hack piggybacked on dbus which can only be used by dbus-aware programs while passive translators can be used by any program which can access the filesystem, calling priviledged programs via systemd provides jailed priviledge escalation like adding capabilities at runtime, but as crude hack piggybacked on dbus and specialized services.
That means, there is a need for the features of the Hurd, but instead of just using the Hurd, where they are cleanly integrated, these features are bolted onto a system where they do not fit and suffer from bad performance due to requiring lots of unnecessary cruft to circumvent limitations of the base system. The clean solution would be to just set 2-3 full-time developers onto the task of resolving the last few blockers (mainly sound and USB) and then just using the Hurd.
On the bare technical side, the translator-based filesystem stands out: The filesystem allows for making arbitrary programs responsible for displaying a given node (which can also be a directory tree) and to start these programs on demand. To make them persistent over reboots, you only need to add them to the filesystem node (for which you need the right to change that node). Also you can start translators on any node without having to change the node itself, but then they are not persistent and only affect your view of the filesystem without affecting other users. These translators are called active, and you don’t need write permissions on a node to add them.
The filesystem implements stuff like Gnome VFS (gvfs) and KDE network transparency on the filesystem level, so those are available for all programs. And you can add a new filesystem as simple user, just as if you’d write into a file “instead of this node, show the filesystem you get by interpreting file X with filesystem Y” (this is what you actually do when setting a translator but not yet starting it (passive translator)).
One practical advantage of this is that the following works:
settrans -a ftp\: /hurd/hostmux /hurd/ftpfs /
dpkg -i ftp://ftp.gnu.org/path/to/*.deb
This installs all deb-packages in the folder path/to on the FTP server. The shell sees normal directories (beginning with the directory “ftp:”), so shell expressions just work.
You could even define a Gentoo mirror translator (settrans mirror\: /hurd/gentoo-mirror), so every program could just access mirror://gentoo/portage-2.2.0_alpha31.tar.bz2 and get the data from a mirror automatically: wget mirror://gentoo/portage-2.2.0_alpha31.tar.bz2
Or you could add a unionmount translator to root which makes writes happen at another place. Every user is able to make a readonly system readwrite by just specifying where the writes should go. But the writes only affect his view of the filesystem.
Starting a network process is done by a translator, too: The first time something accesses the network card, the network translator starts up and actually provides the device. This replaces most initscripts in the Hurd: Just add a translator to a node, and the service will persist over restarts.
It’s a surprisingly simple concept, which reduces the complexity of many basic tasks needed for desktop systems.
And at its most basic level, Hurd is a set of protocols for messages which allow using the filesystem to coordinate and connect processes (along with helper libraries to make that easy).
Also it adds POSIX compatibility to Mach while still providing access to the capabilities-based access rights underneath, if you need them: You can give a process permissions at runtime and take them away at will. For example you can start all programs without permission to use the network (or write to any file) and add the permissions when you need them.
Different from Linux, you do not need to start privileged and drop permissions you do not need (goverened by the program which is run), but you start as unprivileged process and add the permissions you need (governed by an external process):
groups # → root
addauth -p $(ps -L) -g mail
groups # → root mail
And then there are subhurds (essentially lightweight virtualization which allows cutting off processes from other processes without the overhead of creating a virtual machine for each process). But that’s an entire post of its own…
And the fact that a translator is just a simple standalone program means that these can be shared and tested much more easily, opening up completely new options for lowlevel hacking, because it massively lowers the barrier of entry.
For example the current Hurd can use the Linux network device drivers and run them in userspace (via DDE), so you can simply restart them and a crashing driver won’t bring down your system.
And then there is the possibility of subdividing memory management and using different microkernels (by porting the Hurd layer, as partly done in the NetBSD port), but that is purely academic right now (search for Viengoos to see what its about).
So in short:
The translator system in the Hurd is a simple concept that makes many tasks easy, which are complex with Linux (like init, network transparency, new filesystems, …). Additionally there are capabilities (give programs only the access they need - adjusted at runtime), subhurds and (academic) memory management.
Best wishes,
Arne
PS: I decided to read flameeyes’ post as “please give me technical reasons to dispell my emotional impression”.
PPS: If you liked this post, it would be cool if you’d flattr it:
![]() [190]
[190]
PPPS: Additional information can be found in Gaël Le Mignot’s talk notes [191], in niches for the Hurd [192] and the GNU Hurd documentation pages [193].
P4S: This post is also available in the Hurd Staging Wiki [194].
AGPL [195] is a hack on copyright, so it has to use copyright, else it would not compile/run.
All the GPL [196] licenses are a hack on copyright. They insert a piece of legal code into copyright law to force it to turn around on itself.
You run that on the copyright system, and it gives you code which can’t be made unfree.
To be able to do that, it has to be written in copyright language (else it could not be interpreted).
my_code = "<your code>"
def AGPL ( code ):
"""
>>> is_free ( AGPL ( code ) )
True
"""
return eval (
transform_to_free ( code ) )
copyright ( AGPL ( my_code ) )
You pass “AGPL ( code )” to the copyright system, and it ensures the freedom of the code.
The transformation means that I am allowed to change your code, as long as I keep the transformation, because copyright law sees only the version transformed by AGPL, and that stays valid.
Naturally both AGPL definition and the code transformed to free © must be ©-compatible. And that means: All rights reserved. Else I could go in and say: I just redefine AGPL and make your code unfree without ever touching the code itself (which is initially owned by you by the laws of ©):
def AGPL ( code ):
"""
>>> is_free ( AGPL ( code ) )
False
"""
return eval (
transform_to_mine ( code ) )
In this Python-powered copyright-system, I could just define this after your definition but before your call to copyright(), and all calls to APGL ( code ) would suddenly return code owned by me.
Or you would have to include another way of defining which exact AGPL you mean. Something like “AGPL, but only the versions with the sha1 hashes AAAA BBBB and AABA”. cc tries to use links for that, but what do you do if someone changes the DNS resolution to point creativecommons.org to allmine.com? Whose DNS server is right, then - legally speaking?
In short: AGPL is a hack on copyright, so it has to use copyright, else it would not compile/run.
→ An answer I wrote to this question on Quora [197].
Software Engineering: What is the truth of 10x programmers?
Do they really exist?…
Let’s answer the other way round: I once had to take heavy anti-histamines for three weeks. My mind was horribly hazy from that, and I felt awake only about two hours per day. However I spent every day working on a matrix multiplication problem.
It was three weeks of failure, because I just could not grasp the problem. I was unable to hold it in my mind.
Then I could finally drop the anti-histamine.
On the first day I solved the problem on my way to buy groceries. On the second day I planned the implementation while walking for two hours . On the third day I finished the program.
This taught me to accept it when people don’t manage to understand things I understand: I know that the brain can actually have different paces and that complexity which feels easy to me might feel infeasible for others. It sure did feel that way to me while I took the anti-histamines.
It also taught me to be humble: There might be people to whom my current state of mind feels like taking anti-histamines felt to me. I won’t be able to even grasp the patterns they see, because they can use another level of complexity.
To get a grasp of the impact, I ask myself a question: How would an alien solve problems who can easily keep 100 things in its mind — instead of the 4 to 7 which is the rough limit for humans [198]?
This is the biggest news item [199] for free culture and free software in the past 5 years: The creativecommons attribution sharealike license is now one-way compatible to the GPL — see the message from creativecommons [200] and from the Free Software Foundation [201].
Some license compatibility legalese might sound small, but the impact of this is hard to overestimate.
(I’ll now revise some of my texts about licensing — CC BY-SA got a major boost in utility because it not longer excludes usage in copyleft documents which need the source to have a defended sharealike clause)
You have an awesome project, but you see people reach for inferior tools? There are people using your project, but you can’t reach the ones you care about? Read on for a way to ensure that your communication doesn’t ruin your prospects but instead helps your project to shine.
Communicating your project is an essential step for getting the users you want. Here I summarize my experience from working on several different projects including KDE [208] (where I learned the basics of PR - yay, sebas!), the Hurd [171] (where I could really make a difference by improving the frontpage and writing the Month of the Hurd), Mercurial [209] (where I practiced minimally invasive PR) and 1d6 [207] (my own free RPG where I see how much harder it is to do PR, if the project to communicate is your own).
Since voicing the claim that marketing is important often leads to discussions with people who hate marketing of any kind, I added an appendix [210] with an example which illustrates nicely what happens when you don’t do any PR - and what happens if you do PR of the wrong kind.
If you’re pressed for time and want the really short form, just jump to the questionnaire [211].
Before we jump directly to the guide, there is an important term to define: Good marketing. That is the kind of marketing, we want to do.
The definition I use here is this:
Good marketing ensures that the people to whom a project would be useful learn about the project.
and
Good marketing starts with the existing strengths of a project and finds people to whom these strengths are useful.
Thus good marketing does not try to interfere with the greater plan of the project, though it might identify some points where a little effort can make the project much more interesting to users. Instead it finds users to whom the project as it is can be useful - and ensures that these know about the project.
Be fair to competitors, be honest to users, put the project goals before generic marketing considerations.
As such, good marketing is an interface between the project and its (potential) users.
This guide depends on one condition: Your project already has at least one area in which it excels over other projects. If that isn’t the case, please start by making your project useful to at least some people.
The basic way for communicating your project to its potential users always follows the same steps.
To make this text easier to follow, I’ll intersperse it with examples from the latest project where I did this analysis: GNU Guile: The GNU Ubiquitous Intelligent Language for Extensions [221]. Guile provides a nice example, because its mission is clearly established in its name and it has lots of backing, but up until our discussion actually had a wikipedia-page which was unappealing to the point of being hostile against Guile itself.
To improve the communication of our project, we first identify our target groups.
To do so, we begin by asking ourselves, who would profit from our project:
Try to find about 3 groups of people and give them names which identify them. Those are the people we must reach to grow on the short term.
In the next step, we ask ourselves, whom we want or need as users to fullfill our mission (our long-term goal):
Again try to find about 3 groups of people and give them names which identify them. Those are the people we must reach to achieve our longterm goal. If while writing this down you find that one of the already identified groups which we could reach would actually detract us from our goal, mark them. If they aren’t direly needed, we would do best to avoid targeting them in our communication, because they will hinder us in our longterm progress: They could become a liability which we cannot get rid of again.
Now we have about 6 target groups: Those are the people who should know about our project, either because they would benefit from it for pursuing their goals, or because we need to reach them to achieve our own goals. We now need to find out, which kind of information they actually need or search.
GNU Guile is called The GNU Ubiquitous Intelligent Language for Extensions [221]. So its mission is clear: Guile wants to become the de-facto standard language for extending programs - at least within the GNU project.
This part just requires thinking ourselves into the role of each of the target groups. For each of the target groups, ask yourself:
What would you want to know, if you were to read about our project?
As result of this step, we have a set of answers. Judge them on their strengths: Would these answers make you want to invest time to test our project? If not, can we find a better answer?
If our answers for a given group are not yet strong enough, we cannot yet communicate our project convincingly to them. In that case it is best to postpone reaching out to that group, otherwise they could get a lasting weak image of our project which would make it harder to reach them when we have stronger answers at some point in the future.
Remove all groups whose wishes we cannot yet fullfill, or for whom we do not see ourselves as the best choice.
Now we have answers for the target groups. When we now talk or write about our project, we should keep those target groups in mind.
You can make that arbitrarily complex, for example by trying to find out which of our target groups use which medium. But lets keep it simple:
Ensure that our website (and potentially existing wikipedia page) includes the information which matters to our target groups. Just take all the answers for all the target groups we can already reach and check whether the basic information contained in them is given on the front page of our website.
And if not, find ways to add it.
As next steps, we can make sure that the questions we found for the target groups not only get answered, but directly lead the target groups to actions: For example to start using our project.
For Guile, we used this analysis to fix the Wikipedia-Page. The old-version [227] mainly talked about history and weaknesses (to the point of sounding hostile towards Guile), and aside from the latest release number, it was horribly outdated. And it did not provide the information our target groups required.
The current Wikipedia-Page of GNU Guile [228] works much better - for the project as well as for the readers of the page. Just compare them directly and you’ll see quite a difference. But aside from sounding nicer, the new site also addresses the questions of our target groups. To check that, we now ask: Did we include information for all the potential user-groups?
So there you go: Not perfect, but most of the groups are covered. And this also ensures that the Wikipedia-page is more interesting to its readers: A clear win-win.
Additional points which we should keep in mind:
For whom are we already useful or interesting? Name them as Target-Groups.
Whom do we want as users on the long run? Name them as Target-Groups.
Use bab-com to avoid bad-com ☺ - yes, I know this phrase is horrible, but it is catchy and that fits this article: you need catchy things
The mission statement is a short paragraph in which a project defines its goal.
A good example is:
Our mission is to create a general-purpose kernel suitable for the GNU operating system, which is viable for everyday use, and gives users and programs as much control over their computing environment as possible. → GNU Hurd mission explained [229]
Another example again comes from Guile:
Guile was conceived by the GNU Project following the fantastic success of Emacs Lisp as an extension language within Emacs. Just as Emacs Lisp allowed complete and unanticipated applications to be written within the Emacs environment, the idea was that Guile should do the same for other GNU Project applications. This remains true today. → Guile and the GNU project [230]
Closely tied to the mission statement is the slogan: A catch-phrase which helps anchoring the gist of your project in your readers mind. Guile does not have that, yet, but judging from its strengths, the following could work quite well for Guile 2.0 - though it falls short of Guile in general:
GNU Guile scripting: Use Guile Scheme, reuse anything.
We saw why it is essential to communicate the project to the outside, and we discussed a simple structure to check whether our way of communication actually fits our projects strengths and goals.
Finding the communication strategy actually boils down to 3 steps:
Also a clear mission statement, slogan and project description help to make the project more tangible for readers. In this context, good marketing means to ensure that the right people learn about the real strengths of the project.
With that I’ll conclude this guide. Have fun and happy hacking!
— Arne Babenhauserheide
In free software we often think that quality is a guarantee for success. But in just the 10 years I’ve been using free software nowadays, I saw my share of technically great projects succumbing to inferior projects which simply reached more people and used that to build a dynamic which greatly outpaced the technically better product.
One example for that are pkgcore and paludis. When portage, the package manager of Gentoo, grew too slow because it did ever more extensive tests, two teams set out to build a replacement.
One of the teams decided that the fault of the low performance lay in Python, the language used by portage. That team built a package manager in C++ and had --wonderfully-long-command-options without shortcuts (have fun typing), and you actually had to run it twice: Once to see what would get installed and then again to actually install it (while portage had had an --ask option for ages, with -a as shortcut). And it forgot all the work it had done in the previous run, so you could wait twice as long for the result. They also had wonderful latin names, and they managed the feat of being even slower than portage, despite being written in C++. So their claim that C++ would be magically faster than python was simply wrong (because they skipped analyzing the real performance bottlenecks). They called their program paludis.
Note: Nowadays paludis has a completely new commandline interface which actually supports short command options. That interface is called cave and looks sane.
The other team did a performance analysis and realized that the low performance actually lay with the filesystem: The portage tree, which holds the required information, contains about 30,000 ebuilds and almost 200,000 files in total, and portage accessed far more of those files than actually needed for resolving the dependencies needed to install the package. They picked python as their language - just like portage. They used almost the same commandline options as portage, except for the places where functionality differed. And they actually got orders of magnitude faster than portage - so fast that their search command often finished after less than a second while. portage took over 10 seconds. They called their program pkgcore.
Both had more exact resolution of packages and could break cyclic dependencies and so on.
So, judging from my account of the quality, which project would you expect to succeed?
I sure expected pkgcore to replace portage within a few months. But this is not what happened. And as I see it in hindsight, the difference lay purely in PR.
The paludis team with their slow and hard-to-use program went all over the Gentoo forums claiming that Python is a horrible language and that a C program will kick portage any time. On their website they repeated their attacks against python and claimed superiority at every step. And they gathered quite a few zealots. While actually being slower than portage. Eventually they rebranded paludis as just better and more correct, not faster. And they created their own distribution (exherbo) as direct rival of Gentoo. With a new, portage-incompatible package format. As if they had read the book, how not to be a friendly competitor.
The pkgcore team on the other hand focussed on good technology. They
created the snakeoil library for high-performance python code, but
they were friendly about it and actually contributed back to portage
where code could be shared. But their website was out of date, often
not noting the newest release and you actually had to run pmerge
--help to see the most current commandline options (though you could
simply guess them if you knew portage). And they got attacked by
paludis zealots so much, that this year the main developer finally
sacked the project: He told me on IRC that he had taken so much
vitriol over the years that it simply wasn’t worth the cost anymore.
Update: About a year later someone else took over. Good code often survives the loss of its creator.
So, what can we learn from this? Technical superiority does not gain you anything, if you fail to convince people to actually use your project.
If you don't communicate your project, you don't get users. If you don’t get users, your chances of losing motivation are orders of magnitude higher than if you get users who support you.
And aggressive marketing works, even if you cannot actually deliver on your promises. Today they have a better user-interface and even short option-names. But even to date, exherbo has much fewer packages in its repositories than Gentoo. If the number of files is any measure, the 10,000 files in their special repositories are just about 5% of the almost 200,000 files portage holds. But they managed quite well to fraction the Gentoo users - at least for some time. And their repeated pushes for new standards in the portage tree (EAPIs) created a constant pressure on pkgcore to adapt, which had the effect that nowadays pkgcore cannot install from the portage tree anymore (the search still works, though, and I still use it - I will curse mightily on the day they manage to also break that).
Update: Someone else took over and now pkgcore can install again.
So aggressive marketing and doing everything in the book of unfriendly competition might have allowed the paludis devs to gather some users and destroy the momentum of pkgcore, but it did not allow them to actually become a replacement of portage within Gentoo. Their behaviour alienated far too many people for that. So aggressive and unfriendly marketing is better than no marketing, but it has severe drawbacks which you will likely want to avoid.
If you use overly aggressive, unfriendly or dishonest communication tactics, you get some users, but if your users know their stuff, you won’t win the mindshare you need to actually make a difference.
If on the other hand you want to see communication done right, just take a look at KDE and Gnome nowadays. They cooperate quite well, and they compete on features and by improving their project so users can take an informed choice about the project they choose.
And their number of contributors steadily keeps growing.
So what do they do? Besides being technically great, it boils down to good marketing.
Writing a NEWS [231] file (a list of changes per version, targeted at end-users) significantly reduces the effort for doing a release: To write your release notes, just copy the latest entries from the NEWS file into a message. It is one of the gems in the GNU coding standards [232]: Simple yet extremely useful. (For a detailed realization, refer to the Perl Specification for CPAN Changes files [233].)
However when you’re developing features in parallel, for example by using a pull-request workflow and requiring contributors to update the NEWS file, you will often run into merge conflicts. Resolving these takes time, though the resolution is trivial: Just use the lines from both heads.
To resolve the problem, you can set your version tracking system to use union-merge for NEWS files.
echo " [merge-patterns] # avoid bogus conflicts in NEWS files NEWS = internal:union " >> .hg/hgrc
(necessary for each contributor to avoid surprising users)
echo "/NEWS merge=union" >> .gitattributes git add .gitattributes git commit -m "union-merge NEWS" .gitattributes
(committed, so it sticks, but might mislead contributors into missing genuine conflicts, because a contibutor does not necessarily know about the setting)
Often I want to simply backup a single page from a website. Until now I always had half-working solutions, but today I found one solution using wget [234] which works really well, and I decided to document it here. That way I won’t have to search it again, and you, dear readers, can benefit from it, too ☺
Update 2020: You can also use the copyweb-script [235] from pyFreenet:
copyweb -d TARGET_FOLDER URL
Install viapip3 install --user pyFreenet3.
wget --no-parent --timestamping --convert-links --page-requisites --no-directories --no-host-directories --span-hosts --adjust-extension --no-check-certificate -e robots=off -U 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.1.6) Gecko/20070802 SeaMonkey/1.1.4' [URL]
Optionally add --directory-prefix=[target-folder-name]
(see the meaning of the options [236] and getting wget [237] for some explanation)
That’s it! Have fun copying single sites! (but before passing them on, ensure that you have the right to do it)
As a test, how about running this:
wget -np -N -k -p -nd -nH -H -E --no-check-certificate -e robots=off -U 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.1.6) Gecko/20070802 SeaMonkey/1.1.4' --directory-prefix=download-web-site http://draketo.de/english/download-web-page-with-all-prerequisites
(this command uses the short forms of the options)
Then test the downloaded page with firefox:
firefox download-web-site/download-web-page-all-prerequisites.html
If you run GNU/Linux, you likely already have it - and if not, then your package manager has it. GNU wget is one of the standard tools available everywhere.
Some information in the (sadly) typically terse style can be found on the wget website from the GNU project: gnu.org/s/wget [238].
In case you run Windows, have a look at Wget for Windows [239] from the gnuwin32 project or at GNU Wgetw for Windows [240] from eternallybored.
Alternatively you can get a graphical interface via WinWGet [241] from cybershade.
Or you can get serious about having good tools and install MSYS [242] or Cygwin [243] - the latter gets you some of the functionality of a unix working environment on windows, including wget.
If you run MacOSX, either get wget via fink [244], homebrew [245] or MacPorts [246] or follow the guide from osxdaily [247] or the german guide from dirk [248] (likely there are more guides - these two were just the first hits in google).
--no-parent: Only get this file, not other articles higher up in the filesystem hierarchy.--timestamping: Only get newer files (don’t redownload files).--page-requisites: Get all files needed to display this page.--convert-links: Change files to point to the local files you downloaded.--no-directories: Do not create directories: Put all files into one folder.--no-host-directories: Do not create separate directories per web host: Really put all files in one folder.--span-hosts: Get files from any host, not just the one with which you reached the website.--adjust-extension: Add a .html extension to the file.--no-check-certificate: Do not check SSL certificates. This is necessary if you’re missing one of the host certificates one of the hosts uses. Just use this. If people with enough power to snoop on your browsing would want to serve you a changed website, they could simply use one of the fake certifications authorities they control.-e robots=off: Ignore robots.txt files which tell you to not spider and save this website. You are no robot, but wget does not know that, so you have to tell it.-U 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.1.6) Gecko/20070802 SeaMonkey/1.1.4': Fake being an old Firefox to avoid blocking based on being wget.--directory-prefix=[target-folder-name]: Save the files into a subfolder to avoid having to create the folder first. Without that options, all files are created in the folder in which your shell is at the moment. Equivalent to mkdir [target-folder-name]; cd [target-folder-name]; [wget without --directory-prefix]If you know the required options, mirroring single pages from websites with wget is fast and easy.
Note that if you want to get the whole website, you can just replace --no-parent with --mirror.
Happy Hacking!
Parsing command line arguments on the shell is often done in an ad-hoc fashion, growing unwieldy as time goes by, but there are tools to make that elegant. Here’s a complete example.
I use this in the conf [249] project (easy setup of autotools projects). It builds on the great solution by Adam Katz [250].
# outer loop to allow processing option arguments at the end while test ! $# -eq 0; do # getopts loop, here you define the short options: # h for -h, l: for -l <lang>. -: provides support for long-options. while getopts -- hl:-: arg "$@"; do case $arg in h ) ARG_HELP=true ;; l ) ARG_LANG="$OPTARG" ;; - ) LONG_OPTARG="${OPTARG#*=}" case "$OPTARG" in help ) ARG_HELP=true;; lang=?* ) ARG_LANG="$LONG_OPTARG" ;; # FIXME: using the same option twice (either both # after the argument or both before it) gives the # first, not the second value lang* ) ARG_LANG="${@:$OPTIND:1}" ; OPTIND=$(($OPTIND + 1));; vcs=?* ) ARG_VCS="$LONG_OPTARG" ;; vcs* ) ARG_VCS="${@:$OPTIND:1}" ; OPTIND=$(($OPTIND + 1));; '' ) break ;; # "--" terminates argument # processing to allow giving # options for autogen.sh after # -- * ) echo "Illegal option --$OPTARG" >&2; exit 2;; esac;; \? ) exit 2 ;; # getopts already reported the illegal # option esac done shift $((OPTIND-1)) # remove parsed options and args from $@ list # reinitialize OPTIND to allow parsing again OPTIND=1 # provide help output. if test x"${ARG_HELP}" = x"true"; then echo "${PROG} new [-h | --help] [-l | --lang <LANGUAGE>] [--vcs <VCS>] PROJECT_NAME" exit 0 fi # get the argument if test x"${1}" = x"--"; then if test x"${PROJ}" = x""; then echo "Missing project name." >&2; exit 2 else # nothing more to parse. # Remove -- from the remaining arguments shift 1 break fi fi if test ! x"${1}" = x""; then PROJ="${1%/}" # without trailing slash fi # remove the argument, then continue the loop to allow putting # the options after the argument shift 1 done
Additional explanation for this is available from Adam Katz (2015) [251]. I’m allowed to include it here, because every answer on Stackoverflow is licensed under creativecommons attribution sharealike (cc by-sa) [252] and because cc by-sa is upwards compatible [253] to GPLv3 [145].
# From Adam Katz, 2015: http://stackoverflow.com/users/519360/adam-katz # Available at http://stackoverflow.com/a/28466267/7666 # License: cc by-sa: https://creativecommons.org/licenses/by-sa/3.0/ while getopts ab:c-: arg; do case $arg in a ) ARG_A=true ;; b ) ARG_B="$OPTARG" ;; c ) ARG_C=true ;; - ) LONG_OPTARG="${OPTARG#*=}" case $OPTARG in alpha ) ARG_A=true ;; bravo=?* ) ARG_B="$LONG_OPTARG" ;; bravo* ) echo "No arg for --$OPTARG option" >&2; exit 2 ;; charlie ) ARG_C=true ;; alpha* | charlie* ) echo "No arg allowed for --$OPTARG option" >&2; exit 2 ;; '' ) break ;; # "--" terminates argument processing * ) echo "Illegal option --$OPTARG" >&2; exit 2 ;; esac ;; \? ) exit 2 ;; # getopts already reported the illegal option esac done shift $((OPTIND-1)) # remove parsed options and args from $@ list
With this and with the practical usage at the top you should be able to implement clean commandline parsing with ease.
Happy Hacking!
So you get excited when you hear about surviving a power-outage during updates without a hitch [254] and you want to give Guix [83] a try — but woes, you only have 5 minutes of time?
Fear not, that’s enough to get it up and running — all the way to per-user environments and package install as non-priviledged user!
The instructions here are from the official docs [255], specialized for a GNU Linux host and cut to what I need in a working system.
as user:
$ cd /tmp
$ wget ftp://alpha.gnu.org/gnu/guix/guix-binary-0.8.3.x86_64-linux.tar.xz
become root
$ sudo screen
unpack install and setup Guix
# tar xf guix-binary-0.8.3.x86_64-linux.tar.xz
# mv var/guix /var/ && mv gnu /
# ln -sf /var/guix/profiles/per-user/root/guix-profile ~root/.guix-profile
Create the build users as per Build-Environment-Setup [256]:
# groupadd --system guixbuild
# for i in `seq -w 1 10`;
do
useradd -g guixbuild -G guixbuild \
-d /var/empty -s `which nologin` \
-c "Guix build user $i" --system \
guixbuilder$i;
done
Run the daemon:
# ~root/.guix-profile/bin/guix-daemon --build-users-group=guixbuild
Switch to a second root window with CTRL-a c to adjust the PATH, allow substitutes from the Hydra build server, and to install and set locales [257] (required since we’re installing an overlay, not a full distro).
# echo 'PATH="$HOME/.guix-profile/bin:$HOME/.guix-profile/sbin:${PATH}"' >> $HOME/.bashrc
# echo 'export LOCPATH=$HOME/.guix-profile/lib/locale' >> $HOME/.bashrc
# source $HOME/.bashrc
# guix archive --authorize < ~root/.guix-profile/share/guix/hydra.gnu.org.pub
# guix package -i glibc-utf8-locales
Allow all users to use the guix command (as long as guix-daemon is running):
# mkdir -p /usr/local/bin
# cd /usr/local/bin
# ln -s /var/guix/profiles/per-user/root/guix-profile/bin/guix
Switch back to your regular user and provide the guix profile. Also install the locales (remember that the installation is really per-user, though the users share packages if they install them both). The per-user profile will be generated the first time you run guix package.
$ ln -sf /var/guix/profiles/per-user/$(whoami)/guix-profile ~/.guix-profile
$ echo 'export PATH="$HOME/.guix-profile/bin:$HOME/.guix-profile/sbin:${PATH}"' >> $HOME/.bashrc
$ echo 'export LOCPATH=$HOME/.guix-profile/lib/locale' >> $HOME/.bashrc
$ source $HOME/.bashrc
$ guix package -i glibc-utf8-locales
And now:
$ guix package -i guile-emacs --fallback
$ ~/.guix-profile/bin/emacs -Q
So you believed that only a pipe-dream, just like power-loss-resistant updates and functional packaging using the official GNU extension language [25]? I was glad to be proven wrong, and I hope you’ll feel the same ☺ (though guile-emacs [258] is still experimental it already allows calling elisp functions directly from scheme)
Happy Hacking!
»What is the .asc file?« This explanation is intended to be copied as-is into emails when someone asks about your signature.
The .asc file is a signature which can be used to verify that the email was really sent by me and wasn’t tampered with.[1] It can be verified with standard email security tools like Enigmail[2], Gpg4win[3] or MacGPG[4] - and others tools supporting OpenPGP[5].
Best wishes,
Arne
[1]: For further information on signatures see
https://www.gnupg.org/gph/en/manual/x135.html [259]
[2]: Enigmail enables secure communication in Thunderbird:
https://addons.mozilla.org/de/thunderbird/addon/enigmail/ [260]
[3]: GPG4win provides secure encryption for Windows:
http://gpg4win.org/download.html [261]
[4]: MacGPG provides encryption for MacOSX:
https://gpgtools.org/ [262]
[5]: Encryption for other systems is available from the GnuPG website:
https://www.gnupg.org/download/ [263]
Moved to draketo.de/software/makefile-to-autotools [264].
Autotools: practitioner's guide [265]
Useful examples — and prefixes.
Autotools Mythbuster [266]
With years of Gentoo experience: How not to enrage your distributions.
Autoconf Manual [267]
The official manual. Detailed, huge and hard to digest.
Automake Manual [268]
As above. Keep it handy as reference.
I recently started looking into Autotools, to make it easier to run my code on multiple platforms.
Naturally you can use cmake or scons or waf or ninja or tup, all of which are interesting in there own respect. But none of them has seen the amount of testing which went into autotools, and none of them have the amount of tweaks needed to support about every system under the sun. And I recently found pyconfigure [269] which allows using autotools with python and offers detection of library features.
Warning 2016: Contains some cargo-cult-programming [270] — my current setup is cleaner thanks to using AC_CONFIG_LINKS in configure.ac.
I had already used Makefiles for easily storing the build information of anything from python projects (python setup.py build) to my PhD thesis with all the required graphs.
I also had used scons for those same tasks.
But I wanted to test, what autotools have to offer. And I found no simple guide which showed me how to migrate from a Makefile to autotools - and what I could gain through that.
So I decided to write one.
The starting point is the Makefile I use for building my PhD. That’s pretty generic and just uses the most basic features of make.
If you do not know it yet: A basic makefile has really simple syntax:
# comments start with # thing : required source files # separated by spaces build command second build command # ^ this is a TAB.
The code above is a rule. If you put a file with this content into some folder using the filename Makefile and then run make thing in that folder (in a shell [271]), the program “make [272]” will check whether the source files have been changed after it last created the thing and if they have been changed, it will execute the build commands.
You can use things from other rules as source file for your thing and make will figure out all the tasks needed to create your thing.
My Makefile below creates plots from data and then builds a PDF from an org-mode file.
all: doktorarbeit.pdf sink.pdf sink.pdf : sink.tex images/comp-t3-s07-tem-boas.png images/comp-t3-s07-tem-bona.png images/bona-marble.png images/boas-marble.png pdflatex sink.tex rm -f *_flymake* flymake* *.log *.out *.toc *.aux *.snm *.nav *.vrb # kill litter comp-t3-s07-tem-boas.png comp-t3-s07-tem-bona.png : nee-comp.pyx nee-comp.txt pyxplot nee-comp.pyx doktorarbeit.pdf : doktorarbeit.org emacs --batch --visit "doktorarbeit.org" --funcall org-export-as-pdf
The first step is simple: How can I replicate with autotools what I did with the plain Makefile?
For that I create the files configure.ac and Makefile.am. The basic Makefile.am is simply my Makefile without any changes.
The configure.ac sets the project name, inits automake and tells autoreconf to generate a Makefile.
dnl run `autoreconf -i` to generate a configure script. dnl Then run ./configure to generate a Makefile. dnl Finally run make to generate the project. AC_INIT([Doktorarbeit Inverse GHG], [0.1], [arne.babenhauserheide@kit.edu]) dnl we use the build type foreign here instead of gnu because I do not have a NEWS file and similar, yet. AM_INIT_AUTOMAKE([foreign]) AC_CONFIG_FILES([Makefile]) AC_OUTPUT
Now, if I run `autoreconf -i` it generates a Makefile for me. Nothing fancy here: The Makefile just does what my old Makefile did.
First milestone reached: Feature Equality!
But the generated Makefile is much bigger, offers real –help output and can generate a distribution - which does not work yet, because it misses the source files. But it clearly tells me that with `make distcheck`.
Since `make dist` does not work yet, let’s change that.
… easier said than done. It took me the better part of a day to figure out how to make it happy. Problems there:
So, after much haggling with autotools, I have a working make distcheck:
pdf_DATA = sink.pdf doktorarbeit.pdf sink = sink.tex pkgdata_DATA = images/comp-t3-s07-tem-boas.png images/comp-t3-s07-tem-bona.png dist_pkgdata_DATA = images/bona-marble.png images/boas-marble.png plotdir = . dist_plot_DATA = nee-comp.pyx nee-comp.txt doktorarbeit = doktorarbeit.org EXTRA_DIST = ${sink} ${dist_pkgdata_DATA} ${doktorarbeit} MOSTLYCLEANFILES = \#* *~ *.bak # kill editor backups CLEANFILES = ${pdf_DATA} DISTCLEANFILES = ${pkgdata_DATA} sink.pdf : ${sink} ${pkgdata_DATA} ${dist_pkgdata_DATA} TEXINPUTS=${TEXINPUTS}:$(srcdir)/:$(srcdir)/images// pdflatex $< rm -f *_flymake* flymake* *.log *.out *.toc *.aux *.snm *.nav *.vrb # kill litter ${pkgdata_DATA} : ${dist_plot_DATA} $(foreach i,$^,if test "$(i)" != "$(notdir $(i))"; then cp -u "$(i)" "$(notdir $(i))"; fi;) ${MKDIR_P} images pyxplot $< $(foreach i,$^,if test "$(i)" != "$(notdir $(i))"; then rm -f "$(notdir $(i))"; fi;) doktorarbeit.pdf : ${doktorarbeit} if test "$<" != "$(notdir $<)"; then cp -u "$<" "$(notdir $<)"; fi emacs --batch --visit "$(notdir $<)" --funcall org-export-as-pdf if test "$<" != "$(notdir $<)"; then rm -f "$(notdir $<)"; rm -f $(basename $(notdir $<)).tex $(basename $(notdir $<)).tex~; else rm -f $(basename $<).tex $(basename $<).tex~; fi
You might recognize that this is not the simple Makefile anymore. It is now a setup which defines files for distribution and has custom rules for preparing script runs and for cleanup.
But I can now make a fully working distribution, so when I want to publish my PhD thesis, I can simply add the generated release tarball. I work in a Mercurial repo, so I would more likely just include the repo, but there might be reasons for leaving out the history - and be it only that the history might grow quite big.
Second milestone reached: make distcheck!
An advantage is that in the process of preparing the dist, my automake file got cleanly separated into a section defining files and dependencies and one defining build rules.
But I now also understand where newer build tools like scons got their inspiration for the abstractions they use.
I should note, however, that if you were to build a software project in one of the languages supported by automake (C, C++, Python and quite a few others), I would not have needed to specify the build rules myself.
And being able to freely mix the dependency declaration in automake style with Makefile rules gives a lot of flexibility which I missed in scons.
Now I can build and distribute my project, but I cannot yet make sure that the programs I need for building actually exist.
And that’s finally something which can really help my build, because it gives clear error messages when something is missing, and it allows users to specify which of these programs to use via the configure script. For example I could now build 5 different versions of Emacs and try the build with each of them.
Also I added cross compilation support, though that is a bit over the top for simple PDF creation :)
Firstoff I edited my configure.ac to check for the tools:
dnl run `autoreconf -i` to generate a configure script. dnl Then run ./configure to generate a Makefile. dnl Finally run make to generate the project. AC_INIT([Doktorarbeit Inverse GHG], [0.1], [arne.babenhauserheide@kit.edu]) # Check for programs I need for my build AC_CANONICAL_TARGET AC_ARG_VAR([emacs], [How to call Emacs.]) AC_CHECK_TARGET_TOOL([emacs], [emacs], [no]) AC_ARG_VAR([pyxplot], [How to call the Pyxplot plotting tool.]) AC_CHECK_TARGET_TOOL([pyxplot], [pyxplot], [no]) AC_ARG_VAR([pdflatex], [How to call pdflatex.]) AC_CHECK_TARGET_TOOL([pdflatex], [pdflatex], [no]) AS_IF([test "x$pdflatex" = "xno"], [AC_MSG_ERROR([cannot find pdflatex.])]) AS_IF([test "x$emacs" = "xno"], [AC_MSG_ERROR([cannot find Emacs.])]) AS_IF([test "x$pyxplot" = "xno"], [AC_MSG_ERROR([cannot find pyxplot.])]) # Run automake AM_INIT_AUTOMAKE([foreign]) AM_MAINTAINER_MODE([enable]) AC_CONFIG_FILES([Makefile]) AC_OUTPUT
And then I used the created variables in the Makefile.am: See the @-characters around the program names.
pdf_DATA = sink.pdf doktorarbeit.pdf sink = sink.tex pkgdata_DATA = images/comp-t3-s07-tem-boas.png images/comp-t3-s07-tem-bona.png dist_pkgdata_DATA = images/bona-marble.png images/boas-marble.png plotdir = . dist_plot_DATA = nee-comp.pyx nee-comp.txt doktorarbeit = doktorarbeit.org EXTRA_DIST = ${sink} ${dist_pkgdata_DATA} ${doktorarbeit} MOSTLYCLEANFILES = \#* *~ *.bak # kill editor backups CLEANFILES = ${pdf_DATA} DISTCLEANFILES = ${pkgdata_DATA} sink.pdf : ${sink} ${pkgdata_DATA} ${dist_pkgdata_DATA} TEXINPUTS=${TEXINPUTS}:$(srcdir)/:$(srcdir)/images// @pdflatex@ $< rm -f *_flymake* flymake* *.log *.out *.toc *.aux *.snm *.nav *.vrb # kill litter ${pkgdata_DATA} : ${dist_plot_DATA} $(foreach i,$^,if test "$(i)" != "$(notdir $(i))"; then cp -u "$(i)" "$(notdir $(i))"; fi;) ${MKDIR_P} images @pyxplot@ $< $(foreach i,$^,if test "$(i)" != "$(notdir $(i))"; then rm -f "$(notdir $(i))"; fi;) doktorarbeit.pdf : ${doktorarbeit} if test "$<" != "$(notdir $<)"; then cp -u "$<" "$(notdir $<)"; fi @emacs@ --batch --visit "$(notdir $<)" --funcall org-export-as-pdf if test "$<" != "$(notdir $<)"; then rm -f "$(notdir $<)"; rm -f $(basename $(notdir $<)).tex $(basename $(notdir $<)).tex~; else rm -f $(basename $<).tex $(basename $<).tex~; fi
Third milestone reached: Checking for required tools!
With this I’m at the limit of the advantages of autotools for my simple project.
They allow me to create and check a distribution tarball with relative ease (if I know how to do it), and I can use them to check for tools - and to specify alternative tools via the commandline.
For a C or C++ project, autotools would have given me a lot of other things for free, but even the basic features shown here can be useful.
You have to judge for yourself if they outweight the cost of moving away from the dead simple Makefile syntax.
A little bonus I want to share.
I also wrote an scons script as alternative to my Makefile which I think might be interesting to you. It is almost equivalent to my Makefile since it can build my files, but scons does not match the features of the full autotools build and distribution system. Missing: Clean up temporary files and create a validated distribution tarball.
Missing in SCons: No distcheck!
You might notice that the more declarative style with explicit dependency information looks quite a bit more similar to automake than to plain Makefiles.
The following is my SConstruct file:
#!/usr/bin/env python ## I need a couple of special builders for my projects # the $SOURCE replacement only uses the first source file. $SOURCES gives all. # specifying all source files makes it possible to rerun the build if a single source file changed. orgexportpdf = 'emacs --batch --visit "$SOURCE" --funcall org-export-as-pdf' pyxplot = 'pyxplot $SOURCE' # pdflatex is quite dirty. I directly clean up after it with rm. pdflatex = 'pdflatex $SOURCE -o $TARGET; rm -f *_flymake* flymake* *.log *.out *.toc *.aux *.snm *.nav *.vrb' # build the PhD thesis from emacs org-mode. Command("doktorarbeit.pdf", "doktorarbeit.org", orgexportpdf) # create plots Command(["images/comp-t3-s07-tem-boas.png", "images/comp-t3-s07-tem-bona.png"], ["nee-comp.pyx", "nee-comp.txt"], pyxplot) # build my sink.pdf Command("sink.pdf", ["sink.tex", "images/comp-t3-s07-tem-boas.png", "images/comp-t3-s07-tem-bona.png", "images/bona-marble.png", "images/boas-marble.png"], pdflatex) # My editors leave tempfiles around. I want them gone after a build clean. This is not yet supported! tempfiles = Glob('*~') + Glob('#*#') + Glob('*.bak') # using this here would run the cleaning on every run. #Command("clean", [], Delete(tempfiles))
If you want to integrate building with scons into a Makefile, the following lines allow you to run scons with `make sconsrun`. You might have to also mark sconsrun as .PHONY.
sconsrun : scons python scons/bootstrap.py -Q scons : hg clone https://bitbucket.org/ArneBab/scons
Here you can see part of the beauty of autotools, because you can just add this to your Makefile.am instead of the Makefile and it will work inside the full autotools project (though without the dist-integration). So autotools is a real superset of simple Makefiles.
If org-mode export keeps pestering you about selecting a TeX-master everytime you build the PDF, add the following to your org-mode file:
#+BEGIN_LaTeX %%% Local Variables: %%% TeX-master: t %%% End: #+END_LaTeX
| Anhang | Größe |
|---|---|
| 2013-03-05-Di-make-to-autotools.org [273] | 12.9 KB |
PDF-version [274] (for printing)
orgmode-version [275] (for editing)
For a few days now my Quod Libet [276] has been broken, showing only empty space instead of information panes.
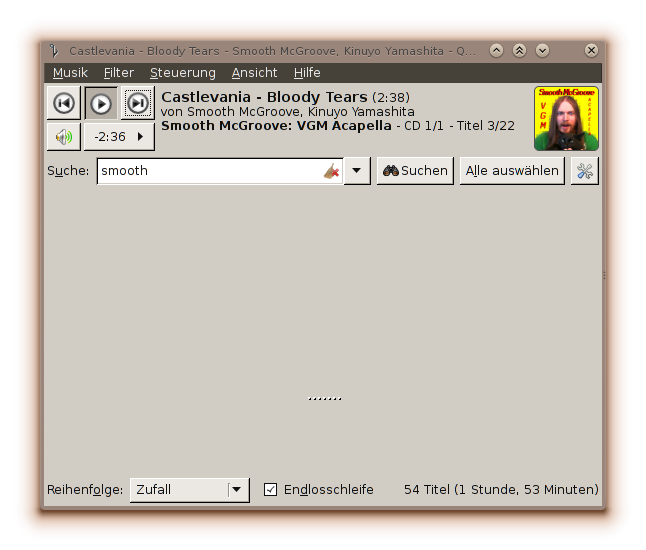
I investigated halfheartedly, but did not find the cause with quick googling. Today I decided to change that. I document my path here, because I did not yet write about how I actually tackle problems like these - and I think I would have profited from having a writeup like this when I started, instead of having to learn it by trial-and-error.
Update: Quodlibet 2.6.3 is now in the Gentoo portage tree [277] - using my ebuild. The update works seamlessly. So to get your Quodlibet 2.5 running again, just call
emerge =media-sound/quodlibet-2.6.3 =media-plugins/quodlibet-plugins-2.6.3. Happy Hacking!Update: I got a second reply [278] in the bug tracker which solved the plugins problem: I had user-plugins which require Quod Libet 3. Solution:
mv ~/.quodlibet/plugins ~/.quodlibet/plugins.for-ql3. Quod Libet works completely again.Solution for the impatient: Update to Quod Libet 2.5.1. In Gentoo [279] that’s easy [280].
As starting point I installed the Quod Libet plugins (media-libs/quodlibet-plugins), thinking that the separation between plugins and mediaplayer might not be perfect. That did not fix the problem, but a look at the plugin listing gave me nice backtraces:
And these actually show the reason for the breakage: Cannot import GTK:
Traceback (most recent call last):
File "/home/arne/.quodlibet/plugins/songsmenu/albumart.py", line 51, in <module>
from gi.repository import Gtk, Pango, GLib, Gdk, GdkPixbuf
File "/usr/lib64/python2.7/site-packages/gi/__init__.py", line 27, in <module>
from ._gi import _API, Repository
ImportError: cannot import name _API
Let’s look which package this file belongs to:
equery belongs /usr/lib64/python2.7/site-packages/gi/__init__.py
* Searching for /usr/lib64/python2.7/site-packages/gi/__init__.py ... dev-python/pygobject-3.8.3 (/usr/lib64/python2.7/site-packages/gi/__init__.py)
So I finally have an answer: pygobject changed the API. Can’t be hard to fix… (a realization process follows)
qlop -l pygobject
... Thu Dec 5 00:26:27 2013 >>> dev-python/pygobject-3.8.3
echo =dev-python/pygobject-3.8.3 >> /usr/portage/package.mask
emerge -u pygobject
LANG=C quodlibet
/usr/lib64/python2.7/site-packages/quodlibet/qltk/songlist.py:44: GtkWarning: Unable to locate theme engine in module_path: "clearlooks",
_label = gtk.Label().create_pango_layout("")
In the bug report at Quod Libet I got a reply [284]: Known issue with quodlibet 2.5 “which triggered a bug in a recent pygtk release, resulting in lists not showing”. The plugins seem to be unrelated. Solution to my immediate problem: Update to 2.5.1. That’s not yet in gentoo, but this is easy to fix:
cd /usr/portage/media-sound/ # create the category in my local portage overlay, defined as # PORTAGE_OVERLAY=/usr/local/portage in /etc/make.conf mkdir -p /usr/local/portage/media-sound # copy over the quodlibet directory, keeping the permissiong with -p cp -rp quodlibet /usr/local/portage/media-sound # most times it is enough to simply rename the ebuild to the new version cd /usr/local/portage/media-sound/quodlibet mv quodlibet-2.5.ebuild quodlibet-2.5.1.ebuild # now prepare all the metadata portage needs - this requires # app-portage/gentoolkit ebuild quodlibet-2.5.1.ebuild digest compile # now it's prepared for the package manager. Just update it as usual: emerge -u quodlibet
I wrote the solution [285] in the Gentoo bug report. I should also state, that the gentoo package for Quod Libet is generally out of date (releases 2.6.3 and 3.0.2 are not yet in the tree).
Quod Libet works again.

As soon as the ebuild in the portage tree is renamed, Quod Libet should work again for all Gentoo users.
The plugins still need to be fixed, but I’ll worry about that later.
Solving the core problem took me some time, but it wasn’t really complicated. The part of the solution process which got me forward boils down to:
And that’s it: To get something working again, check the bug trackers, report bugs and help synchronizing bug tracker info.
| Anhang | Größe |
|---|---|
| 2013-12-11-quod-libet-broken.png [289] | 49.59 KB |
| 2013-12-11-quod-libet-broken-clearlooks.png [290] | 50.44 KB |
| 2013-12-11-quod-libet-broken-plugins.png [291] | 27.47 KB |
| 2013-12-11-quod-libet-fixed.png [292] | 85.61 KB |
| 2013-12-11-Mi-quodlibet-broken.org [275] | 7.11 KB |
| 2013-12-11-Mi-quodlibet-broken.pdf [274] | 419.37 KB |
Don’t want to rely on other’s opinions about the Hurd? How to run your own GNU Hurd, in 140 letters:
wget http://people.debian.org/~sthibault/hurd-i386/debian-hurd.img.tar.gz; tar xf de*hu*gz; qemu-system-x86_64 -hda de*hu*g -m 1G
 [293]
[293]
For additional convenience and performance, setup ssh access and enable kvm:
wget http://people.debian.org/~sthibault/hurd-i386/debian-hurd.img.tar.gz; tar xf de*hu*gz; qemu-system-x86_64 -enable-kvm -net user,hostfwd=tcp:127.0.0.1:2222-:22 -net nic -m 1G -drive cache=writeback,file=$(ls de*hu*g)
⇒ login: root, no pw needed. Set a password for user demo:
passwd demo
⇒ log into your Hurd via ssh:
ssh demo@localhost -p 2222
That’s it: You run the Hurd. You you would want to do that? See cat translator_intro — and much more [294].
Additional information:
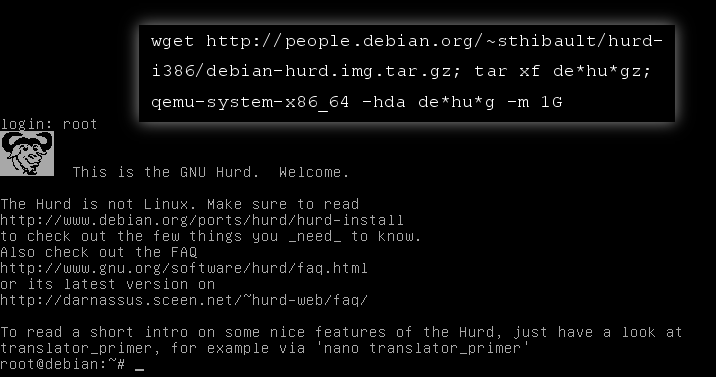 [299]
[299]
| Anhang | Größe |
|---|---|
| 2016-06-08-hurd-howto-140-combined.xcf [300] | 119.56 KB |
| 2016-06-08-hurd-howto-140-combined.png [299] | 19.92 KB |
| hurd-test-2017.webm [301] | 1.05 MB |

4 ways how large raw artwork files are treated in free culture projects to provide the editable source.1
In the discussion about license compatibility of the creativecommons sharealike license [252] towards the GPL [145], Anthony asked [302] how the source-requirement is solved for artwork which often has huge raw files. These are the 4 basic ways I described in my answer.
“The Source is what we have”
The project just asks artists for full resolution PNG image files (without all the layering information) - and only uses these to develop the art. This was spearheaded by the GPL-licensed strategy game Battle for Wesnoth [206].
This is a viable strategy and also allows developing art, though a bit less convenient than with the layered sources. For example the illustrator who created many of the images in the RPG I work on used our PNG instead of her photoshop file to extract a die [303] from the cover she created for us [304]. She took the chance to also touch up the colors a bit - she had learned some new tricks to improve her paintings.
This clearly complies with the GPL, because the GPL just requires providing the file used for editing published file. If the released file is what you actually use to change published files, then the published file is the source.
“Use the FTP, Luke”
Here, files which are too big to be versioned effectively or which most people don’t need when working with the project get version-numbers and are put into an external storage - like an FTP server.
I do that for gimp-files: I put these into our public release-listing [305] via FTP. For example I used that for a multi-layer cover [306] which gets baked into our PDF.
“Make it so!”
Here huge files are simply versioned alongside other files and the versions to be used are created directly from the multi-layered files. The usual way to do that is a Makefile in which scripts explicitly define how the derived file can be extracted.
This is most elegant, because it has no duplication of information, the source is always trivial to find, it’s always clear that the derived file really originated from the source and it is easy to avoid quality loss or even reduce it later.
The disadvantage is that it can be very cumbersome to force new developers to get all huge files and then create them before being able to really start developing.
The common way to do this is a Makefile - for example the one I use for building my PhD thesis [307].
“Hybrids win”
All the ways above can be combined: Huge files are put in version control, but the derived files are included, too, to make it easier for new people to get in. Maybe the huge files are only included on request - for example they could be stubs with which the version control system can retrieve the full files when the user wants them. This can partially be done with the largefiles extension [308] in Mercurial by just not getting the large files.
Also you can just keep separate raw files and derived files. This is also used in Battle for Wesnoth [206]: Optimized files of the right size for the game are stored in one folder while the bigger full resolution files are stored separately.
If you want to include free art in a GPL-covered work, I hope this article gave you some inspiration!
The die was created by Trudy Wenzel (2013) and is licensed under GPLv3 or later. ↩
Fortran developer silently weeps:
! immutable 2D array as argument in Fortran integer, intent(in) :: arg(:,:) ! constant value character(len=10), parameter :: numbers = "0123456789"
See parameter vs. intent(in) [309].
(yes, I’m currently reading a Javascript book)
If you now want to see more of Fortran:
Org-Source [312] (for editing)
PDF [313] (for printing)
“Got a power-outage while updating?
No problem: Everything still works”
GNU Guix [83] is the new functional package manager from the GNU Project [314] which complements the Nix-Store with a nice Guile Scheme [25] based package definition format.
What sold it to me was “Got a power-outage while updating? No problem: Everything still works” from the Guix talk of Ludovico [315] at the GNU Hacker Meeting 2013 [316]. My son once found the on-off-button of our power-connector while I was updating my Gentoo box. It took me 3 evenings to get it completely functional again. This would not have happened with Guix.
Update (2014-05-17): Thanks to zerwas from IRC @ freenode for the patch to guix 0.6 and nice cleanup!
Installation of GNU Guix [83] is straightforward, except if you follow the docs, but it’s not as if we’re not used to that from other GNU utilities, which often terribly short-sell their quality with overly general documentation ☺
So I want to provide a short guide how to setup and run GNU Guix with ease. My system natively runs Gentoo, My system natively runs Gentoo, so some details might vary for you. If you use Gentoo, you can simply copy the commands here into the shell, but better copy them to a text-file first to ensure that I do not try to trick you into doing evil things with the root access you need [317].
In short: This guide provides the First Contact [318] and Black Triangle [319] for GNU Guix [83].
mkdir guix && cd guix
wget http://alpha.gnu.org/gnu/guix/guix-0.6.tar.gz
wget http://alpha.gnu.org/gnu/guix/guix-0.6.tar.gz.sig
gpg --verify guix-0.?.tar.gz.sig
tar xf guix-0.?.tar.gz
cd guix-0.?
./configure && make -j16
sudo make install
Build-users allow for strong separation of build processes: They cannot affect each other, because they actually run as different users.
sudo screen groupadd guix-builder for i in `seq 1 10`; do useradd -g guix-builder -G guix-builder \ -d /var/empty -s `which nologin` \ -c "Guix build user $i" --system \ guix-builder$i; done exit
(if you do not have GNU screen yet, you should get it. It makes working on remote servers enjoyable.
Also we want to run guix as regular user. We need to pre-create the user-specific build-directory. Note: This should really be done automatically.
sudo mkdir -p /usr/local/var/nix/profiles/per-user/$USER sudo chown -R $USER:$USER /usr/local/var/nix/profiles/per-user/$USER
chgrp 1002 /nix/store; chmod 1775 /nix/store
this might be quite Gentoo-specific.
sudo screen echo "#\!/bin/sh" >> /etc/local.d/guix-daemon.start echo "guix-daemon --build-users-group=guix-builder &" >> /etc/local.d/guix-daemon.start echo "#\!/bin/sh" >> /etc/local.d/guix-daemon.stop echo "pkill guix-daemon" >> /etc/local.d/guix-daemon.stop chmod +x /etc/local.d/guix-daemon.start chmod +x /etc/local.d/guix-daemon.stop exit
(the pkill is not the nice way of killing the daemon. Ideally the daemon should have a –kill option)
To avoid having to restart, we just launch the daemon once, now.
sudo /etc/local.d/guix-daemon.start
Guix installs each state of the system in its own directory, which actually enables rollbacks. The current state is made available via ~/.guix-profile/, and so we need ~/.guix-profile/bin in our path:
echo "export PATH=$PATH:~/.guix-profile/bin" >> ~/.bashrc . ~/.bashrc
Guix comes with a quite complete commandline interface. The basics are
For a new distribution-tool, Guix is quite nice. Remember, though, that it builds on Nix: It is not a complete reinvention but rather “stands on the shoulders of giants”.
The download speeds are abysmal, though. http://hydra.gnu.org [320] seems to have a horribly slow internet connection…
And what I direly missed is a short command explanation in the help output:
$ guix --help Usage: guix COMMAND ARGS... Run COMMAND with ARGS. COMMAND must be one of the sub-commands listed below: build download gc hash import package pull refresh substitute-binary
Also I miss the categories I know from Gentoo: Having package-names like grue-hunter seems very unorganized compared to the games-text/grue-hunter which I know from Gentoo.
And it would be nice to have shorthands for the command names:
and so on.
But anyway: A very interesting project which I plan to keep tracking. It might allow me to do less risky local package installs of stuff I need, like small utilities I wrote myself.
The big advantage of that would be, that I could actually take them with me when I have to use different distros (though I’ve been a happy Gentoo user for ~10 years and I don’t see it as likely that I’ll switch completely: Guix would have to include all the roughly 30k packages in Gentoo to actually be a full-fledged alternative - and provide USE flags and all the convenient configurability [321] which makes Gentoo such a nice experience).
Using guix for such small stuff would allow me to decouple experiments from my production environment (which has to keep working).
But enough talk: Have fun with GNU Guix [83] and Happy Hacking!
| Anhang | Größe |
|---|---|
| 2013-09-04-Mi-guix-install.org [312] | 6.53 KB |
| 2013-09-04-Mi-guix-install.pdf [313] | 171.32 KB |
2 years ago I had the task of running a python-program using scipy on our university cluster, using the Intel Compiler. I needed all those (as well as PyNIO and some other stuff) for running TM5 with the python shell [325] on the HC3 of KIT [326].
This proved to be quite a bit more challenging than I had expected - but it was very interesting, too (and there I learned the basics of GNU autotools which still help me a lot).
But no one should have to go to the same effort with as little guidance as I had, so I decided to publish the script and the patches I created for installing everything we needed.1 [327]
The script worked 2 years ago, so you might have to fix some bits. I won’t promise that this contains everything you need to run the script - or that it won’t be broken when you install it. Actually I won’t promise anything at all, except that if the stuff here had been available 2 years ago, that could have saved me about 2 months of time (each of the patches here required quite some tracking of problems, experimenting and fixing, until it provided basic functionality - but actually I enjoyed doing that - I learned a lot - I just don’t want to be forced to do it again). Still, this stuff contains quite some hacks - even a few ugly ones. But it worked.
This script requires and installs quite a few libraries. I retrieved most of the following tarballs from my Gentoo distfiles dir after installing the programs locally. I uploaded them to draketo.de/dateien/scipy-pynio-deps [328]. These files are included there:
satexputils.so also needs interpolatelevels.F90 which I think that I am not allowed to share, so you’re on your own there. Guess why I do not like using non-free (or not-guaranteed-to-be-free) software.
The hdf autotools patch only retrieves the last CFLAG instead of all:
export CC='gcc-4.8.1 -Wall -Werror' echo $CC | grep \ - | sed 's/.* -/-/' -Werror
If you have the regexp-foo [352] to fix that, please improve the patch! But without perl (otherwise we’d have to install perl, too).
Udo Grabowski [353], the maintainer of our institutes sun-cluster [354] somehow managed to get that working on OpenIndiana [355] with the Sun-Compiler, but since I did not need it, I did not dig deeper to see whether I could adapt his solutions to the intel-compiler.
Aside from some inline patches, the script uses the following patches:
This is the full install script I used to install all necessary dependencies.
#!/bin/bash # Untar for i in *.tar* *.tgz; do tar xvf $i || exit done # Install PREFIX=/home/ws/babenhau/ PYPREFIX=/home/ws/babenhau/python/ # Blas cd BLAS cp ../blas-make.inc make.inc || exit #make -j9 clean F77=ifort make -j9 || exit #make -j9 install --prefix=$PREFIX # OR for Intel compiler: ifort -fPIC -FI -w90 -w95 -cm -O3 -xHost -unroll -c *.f || exit #Continue below irrespective of compiler: ar r libfblas.a *.o || exit ranlib libfblas.a || exit cd .. ln -s BLAS blas ## Lapack cd lapack-3.3.1 ln -s ../blas # this has a hardcoded absolute path to blas in it: replace is with the appropriate one for you. cp ../lapack-make.inc make.inc || exit make -j9 clean || exit make -j9 make -j9 || exit cp lapack_LINUX.a libflapack.a || exit #make -j9 install --prefix=$PREFIX cd .. # C interface patch -p0 < lapacke-ifort.diff cd lapacke # patch for lapack 3.3.1 and blas for i in gnu inc intel ; do sed -i s/lapack-3\.2\.1\\/lapack\.a/lapack-3\.3\.1\\/lapack_LINUX.a/ make.$i; sed -i s/lapack-3\.2\.1\\/blas\.a/blas\\/blas_LINUX.a/ make.$i; done make -j9 clean || exit #make -j9 LINKER=ifort LDFLAGS=-nofor-main make -j9 # || exit #LINKER=ifort LDFLAGS=-nofor-main make -j9 install cd .. ## ATLAS cd ATLAS cp ../Make.Linux_HC3 . || exit echo "ATLAS needs manual intervention. Run make by hand first." #echo "just say yes. It makes some stuff we need later." #make #mv bin/Linux_UNKNOWNSSE2_8 bin/Linux_HC3 #for i in bin/Linux_HC3/*; do sed -i s/UNKNOWNSSE2_8/HC3/ $i ; done #rm bin/Linux_HC3/Make.inc #cd bin/Linux_HC3/ #ln -s ../../Make.Linux_HC3 Make.inc #cd - make -j9 install arch=Linux_HC3 || exit cd lib for i in Linux_HC3/* ; do ln -s $i ; done cd ../bin for i in Linux_HC3/* ; do ln -s $i ; done cd ../include for i in Linux_HC3/* ; do ln -s $i ; done cd .. cd .. # Numpy and SciPy with intel compilers # Read this: http://marklodato.github.com/2009/08/30/numpy-scipy-and-intel.html # patching patch -p0 < SuiteSparse.diff || exit patch -p0 < SuiteSparse-umfpack.diff || exit rm numpy ln -s numpy-*.*.*/ numpy patch -p0 < numpy-icc.diff || exit patch -p0 < numpy-icpc.diff || exit patch -p0 <<EOF --- numpy/numpy/distutils/fcompiler/intel.py 2009-03-29 07:24:21.000000000 -0400 +++ numpy/numpy/distutils/fcompiler/intel.py 2009-08-06 23:08:59.000000000 -0400 @@ -47,6 +47,7 @@ module_include_switch = '-I' def get_flags(self): + return ['-fPIC', '-cm'] v = self.get_version() if v >= '10.0': # Use -fPIC instead of -KPIC. @@ -63,6 +64,7 @@ return ['-O3','-unroll'] def get_flags_arch(self): + return ['-xHost'] v = self.get_version() opt = [] if cpu.has_fdiv_bug(): EOF # include -fPIC in the fcompiler. sed -i "s/w90/w90\", \"-fPIC/" numpy/numpy/distutils/fcompiler/intel.py # and more of that patch -p0 < numpy-ifort.diff rm scipy ln -s scipy-*.*.*/ scipy patch -p0 < scipy-qhull-icc.diff || exit patch -p0 < scipy-qhull-icc2.diff || exit # # unnecessary! # patch -p0 <<EOF # --- scipy/scipy/special/cephes/const.c 2009-08-07 01:56:43.000000000 -0400 # +++ scipy/scipy/special/cephes/const.c 2009-08-07 01:57:08.000000000 -0400 # @@ -91,12 +91,12 @@ # double THPIO4 = 2.35619449019234492885; /* 3*pi/4 */ # double TWOOPI = 6.36619772367581343075535E-1; /* 2/pi */ # #ifdef INFINITIES # -double INFINITY = 1.0/0.0; /* 99e999; */ # +double INFINITY = __builtin_inff(); # #else # double INFINITY = 1.79769313486231570815E308; /* 2**1024*(1-MACHEP) */ # #endif # #ifdef NANS # -double NAN = 1.0/0.0 - 1.0/0.0; # +double NAN = __builtin_nanf(""); # #else # double NAN = 0.0; # #endif # EOF # building # TODO: try again later cd SuiteSparse make -j9 -C AMD || exit make -j9 -C UMFPACK || exit cd .. # TODO: build numpy again and make sure it has blas and lapack (and ATLAS?) cd numpy python setup.py -v build_src config --compiler=intel build_clib \ --compiler=intel build_ext --compiler=intel || exit python setup.py install --prefix=$PYPREFIX || exit cd .. # scons and numscons cd scons-2.0.1 python setup.py -v install --prefix=/home/ws/babenhau/python/ || exit cd .. git clone git://github.com/cournape/numscons.git cd numscons python setup.py -v install --prefix=/home/ws/babenhau/python/ || exit cd .. # adapt /home/ws/babenhau/python/lib/python2.7/site-packages/numpy/distutils/fcompiler/intel.py by hand to include fPIC for intelem cd scipy PYTHONPATH=/home/ws/babenhau/python//lib/scons-2.0.1/ ATLAS=../ATLAS/ \ LAPACK=../lapack-3.3.1/libflapack.a LAPACK_SRC=../lapack-3.3.1 BLAS=../BLAS/libfblas.a \ F77=ifort f77_opt=ifort python setup.py -v config --compiler=intel --fcompiler=intelem build_clib \ --compiler=intel --fcompiler=intelem build_ext --compiler=intel --fcompiler=intelem \ -I../SuiteSparse/UFconfig # no exit, because we do the linking by hand later on. # one file is C++ :( icpc -fPIC -I/home/ws/babenhau/python/include/python2.7 -I/home/ws/babenhau/python/lib/python2.7/site-packages/numpy/core/include -I/home/ws/babenhau/python/lib/python2.7/site-packages/numpy/core/include -c scipy/spatial/qhull/src/user.c -o build/temp.linux-x86_64-2.7/scipy/spatial/qhull/src/user.o || exit # linking by hand # for x in csr csc coo bsr dia; do # icpc -xHost -O3 -fPIC -shared \ # build/temp.linux-x86_64-2.7/scipy/sparse/sparsetools/${x}_wrap.o \ # -o build/lib.linux-x86_64-2.7/scipy/sparse/sparsetools/_${x}.so || exit # done #icpc -xHost -O3 -fPIC -openmp -shared \ # build/temp.linux-x86_64-2.7/scipy/interpolate/src/_interpolate.o \ # -o build/lib.linux-x86_64-2.7/scipy/interpolate/_interpolate.so || exit # build again with the C++ file already compiled PYTHONPATH=/home/ws/babenhau/python//lib/scons-2.0.1/ ATLAS=../ATLAS/ \ LAPACK=../lapack-3.3.1/libflapack.a LAPACK_SRC=../lapack-3.3.1 BLAS=../BLAS/libfblas.a \ F77=ifort f77_opt=ifort python setup.py config --compiler=intel --fcompiler=intelem build_clib \ --compiler=intel --fcompiler=intelem build_ext --compiler=intel --fcompiler=intelem \ -I../SuiteSparse/UFconfig || exit # make sure we have cephes cd scipy/special PYTHONPATH=/home/ws/babenhau/python//lib/scons-2.0.1/ ATLAS=../../../ATLAS/ \ LAPACK=../../../lapack-3.3.1/libflapack.a LAPACK_SRC=../lapack-3.3.1 BLAS=../../../BLAS/libfblas.a \ F77=ifort f77_opt=ifort python setup.py -v config --compiler=intel --fcompiler=intelem build_clib \ --compiler=intel --fcompiler=intelem build_ext --compiler=intel --fcompiler=intelem \ -I../../../SuiteSparse/UFconfig cd ../.. # install PYTHONPATH=/home/ws/babenhau/python//lib/scons-2.0.1/ ATLAS=../ATLAS/ \ LAPACK=../lapack-3.3.1/libflapack.a LAPACK_SRC=../lapack-3.3.1 BLAS=../BLAS/libfblas.a \ F77=ifort f77_opt=ifort python setup.py config --compiler=intel --fcompiler=intelem build_clib \ --compiler=intel --fcompiler=intelem install --prefix=$PYPREFIX || exit cd .. # PyNIO # netcdf-4 patch -p0 < netcdf-patch1.diff || exit patch -p0 < netcdf-patch2.diff || exit cd netcdf-4.1.3 CPPFLAGS="-I/home/ws/babenhau/libbutz/hdf5-1.8.7/include -I/home/ws/babenhau/include" LDFLAGS="-L/home/ws/babenhau/libbutz/hdf5-1.8.7/lib/ -L/home/ws/babenhau/lib -lsz -L/home/ws/babenhau/libbutz/szip-2.1/lib -L/opt/intel/Compiler/11.1/080/lib/intel64/libifcore.a -lifcore" ./configure --prefix=/home/ws/babenhau/ --enable-netcdf-4 --enable-shared || exit make -j9; make check install -j9 || exit cd .. # NetCDF4 cd netCDF4-0.9.7 HAS_SZIP=1 SZIP_PREFIX=/home/ws/babenhau/libbutz/szip-2.1/ HAS_HDF5=1 HDF5_DIR=/home/ws/babenhau/libbutz/hdf5-1.8.7 HDF5_PREFIX=/home/ws/babenhau/libbutz/hdf5-1.8.7 HDF5_includedir=/home/ws/babenhau/libbutz/hdf5-1.8.7/include HDF5_libdir=/home/ws/babenhau/libbutz/hdf5-1.8.7/lib HAS_NETCDF4=1 NETCDF4_PREFIX=/home/ws/babenhau/ python setup.py build_ext --compiler="intel" --fcompiler="intel -fPIC" install --prefix $PYPREFIX cd .. # parallel netcdf and hdf5: ~/libbutz/ patch -p0 < pynio-fix-no-grib.diff || exit cd PyNIO-1.4.1 HAS_SZIP=1 SZIP_PREFIX=/home/ws/babenhau/libbutz/szip-2.1/ HAS_HDF5=1 HDF5_DIR=/home/ws/babenhau/libbutz/hdf5-1.8.7 HDF5_PREFIX=/home/ws/babenhau/libbutz/hdf5-1.8.7 HDF5_includedir=/home/ws/babenhau/libbutz/hdf5-1.8.7/include HDF5_libdir=/home/ws/babenhau/libbutz/hdf5-1.8.7/lib HAS_NETCDF4=1 NETCDF4_PREFIX=/home/ws/babenhau/ python setup.py install --prefix=$PYPREFIX || exit # TODO: Make sure that the install goes to /home/ws/.., not home/ws/... cd .. # satexp_utils.so f2py -c -m satexp_utils --f77exec=ifort --f90exec=ifort interpolate_levels.F90 || exit ## pyhdf # recompile hdf with fPIC - grr! cd hdf-4*/ # Fix configure for compilers with - in the name. patch -p0 < ../hdf-fix-configure.ac.diff autoconf FFLAGS="-ip -O3 -xHost -fPIC -r8" CFLAGS="-ip -O3 -xHost -fPIC" CXXFLAGS="$CFLAGS -I/usr/include/rpc -DBIG_LONGS -DSWAP" F77=ifort ./configure --prefix=/home/ws/babenhau/ --disable-netcdf --with-szlib=/home/ws/babenhau/libbutz/szip-2.1 # --with-zlib=/home/ws/babenhau/libbutz/zlib-1.2.5 --with-jpeg=/home/ws/babenhau/libbutz/jpeg-8c # finds zlib and jpeg due to LD_LIBRARY_PATH (hack but works…) make make install cd .. # build pyhdf cd pyhdf-0.8.3/ INCLUDE_DIRS="/home/ws/babenhau/include:/home/ws/babenhau/libbutz/szip-2.1/include" LIBRARY_DIRS="/home/ws/babenhau/lib:/home/ws/babenhau/libbutz/szip-2.1/lib" python setup.py build -c intel --fcompiler ifort install --prefix=/home/ws/babenhau/python cd .. ## matplotlib cd matplotlib-1.1.0 patch -p0 < ../matplotlib-add-icc-support.diff python setup.py build -c intel install --prefix=/home/ws/babenhau/python cd .. # GEOS → http://download.osgeo.org/geos/geos-3.3.2.tar.bz2 cd geos*/ ./configure --prefix=/home/ws/babenhau/ make make check make install cd .. # basemap easy_install --prefix /home/ws/babenhau/python basemap # fails but should now have all dependencies. cd basemap-*/ python setup.py build -c intel install --prefix=/home/ws/babenhau/python cd ..
To ease usage and upstreaming of my fixes, I include all the patches below, so you can find them directly in this text instead of having to browse external textfiles.
--- SuiteSparse/UMFPACK/Lib/GNUmakefile 2009-11-11 21:09:54.000000000 +0100 +++ SuiteSparse/UMFPACK/Lib/GNUmakefile 2011-09-09 14:18:57.000000000 +0200 @@ -9,7 +9,7 @@ C = $(CC) $(CFLAGS) $(UMFPACK_CONFIG) \ -I../Include -I../Source -I../../AMD/Include -I../../UFconfig \ -I../../CCOLAMD/Include -I../../CAMD/Include -I../../CHOLMOD/Include \ - -I../../metis-4.0/Lib -I../../COLAMD/Include + -I../../COLAMD/Include #------------------------------------------------------------------------------- # source files
--- SuiteSparse/UFconfig/UFconfig.mk 2011-09-09 13:14:03.000000000 +0200 +++ SuiteSparse/UFconfig/UFconfig.mk 2011-09-09 13:15:03.000000000 +0200 @@ -33,11 +33,11 @@ # C compiler and compiler flags: These will normally not give you optimal # performance. You should select the optimization parameters that are best # for your system. On Linux, use "CFLAGS = -O3 -fexceptions" for example. -CC = cc -CFLAGS = -O3 -fexceptions +CC = icc +CFLAGS = -O3 -xHost -fPIC -openmp -vec_report=0 # C++ compiler (also uses CFLAGS) -CPLUSPLUS = g++ +CPLUSPLUS = icpc # ranlib, and ar, for generating libraries RANLIB = ranlib @@ -49,8 +49,8 @@ MV = mv -f # Fortran compiler (not normally required) -F77 = f77 -F77FLAGS = -O +F77 = ifort +F77FLAGS = -O3 -xHost F77LIB = # C and Fortran libraries @@ -132,13 +132,13 @@ # The path is relative to where it is used, in CHOLMOD/Lib, CHOLMOD/MATLAB, etc. # You may wish to use an absolute path. METIS is optional. Compile # CHOLMOD with -DNPARTITION if you do not wish to use METIS. -METIS_PATH = ../../metis-4.0 -METIS = ../../metis-4.0/libmetis.a +# METIS_PATH = ../../metis-4.0 +# METIS = ../../metis-4.0/libmetis.a # If you use CHOLMOD_CONFIG = -DNPARTITION then you must use the following # options: -# METIS_PATH = -# METIS = +METIS_PATH = +METIS = #------------------------------------------------------------------------------ # UMFPACK configuration: @@ -194,7 +194,7 @@ # -DNSUNPERF for Solaris only. If defined, do not use the Sun # Performance Library -CHOLMOD_CONFIG = +CHOLMOD_CONFIG = -DNPARTITION #------------------------------------------------------------------------------ # SuiteSparseQR configuration:
--- configure.ac 2012-03-01 15:00:28.000000000 +0100 +++ configure.ac 2012-03-01 15:00:40.000000000 +0100 @@ -815,7 +815,7 @@ dnl Report anything stripped as a flag in CFLAGS and dnl only the compiler in CC_VERSION. CC_NOFLAGS=`echo $CC | sed 's/ -.*//'` -CFLAGS_TO_ADD=`echo $CC | grep - | sed 's/.* -/-/'` +CFLAGS_TO_ADD=`echo $CC | grep \ - | sed 's/.* -/-/'` if test -n $CFLAGS_TO_ADD; then CFLAGS="$CFLAGS_TO_ADD$CFLAGS" fi
--- lapacke/make.intel.old 2011-10-05 13:24:14.000000000 +0200 +++ lapacke/make.intel 2011-10-05 16:17:00.000000000 +0200 @@ -56,7 +56,7 @@ # Ensure that the libraries have the same data model (LP64/ILP64). # LAPACKE = lapacke.a -LIBS = ../../../lapack-3.3.1/lapack_LINUX.a ../../../blas/blas_LINUX.a -lm +LIBS = /opt/intel/Compiler/11.1/080/lib/intel64/libifcore.a ../../../lapack-3.2.1/lapack.a ../../../lapack-3.2.1/blas.a -lm -ifcore # # The archiver and the flag(s) to use when building archive (library) # If your system has no ranlib, set RANLIB = echo.
diff -r 38c2a32c56ae matplotlib-1.1.0/setup.py --- a/matplotlib-1.1.0/setup.py Fri Mar 02 12:29:47 2012 +0100 +++ b/matplotlib-1.1.0/setup.py Fri Mar 02 12:30:39 2012 +0100 @@ -31,6 +31,13 @@ if major==2 and minor1<4 or major<2: raise SystemExit("""matplotlib requires Python 2.4 or later.""") +if "intel" in sys.argv or "icc" in sys.argv: + try: # make it compile with the intel compiler + from numpy.distutils import intelccompiler + except ImportError: + print "Compiling with the intel compiler requires numpy." + raise + import glob from distutils.core import setup from setupext import build_agg, build_gtkagg, build_tkagg,\
--- netcdf-4.1.3/fortran/ncfortran.h 2011-07-01 01:22:22.000000000 +0200 +++ netcdf-4.1.3/fortran/ncfortran.h 2011-09-14 14:56:03.000000000 +0200 @@ -658,7 +658,7 @@ * The following is for f2c-support only. */ -#if defined(f2cFortran) && !defined(pgiFortran) && !defined(gFortran) +#if defined(f2cFortran) && !defined(pgiFortran) && !defined(gFortran) &&!defined(__INTEL_COMPILER) /* * The f2c(1) utility on BSD/OS and Linux systems adds an additional
--- netcdf-4.1.3/nf_test/fortlib.c 2011-09-14 14:58:47.000000000 +0200 +++ netcdf-4.1.3/nf_test/fortlib.c 2011-09-14 14:58:38.000000000 +0200 @@ -14,7 +14,7 @@ #include "../fortran/ncfortran.h" -#if defined(f2cFortran) && !defined(pgiFortran) && !defined(gFortran) +#if defined(f2cFortran) && !defined(pgiFortran) && !defined(gFortran) &&!defined(__INTEL_COMPILER) /* * The f2c(1) utility on BSD/OS and Linux systems adds an additional * underscore suffix (besides the usual one) to global names that have
--- numpy/numpy/distutils/intelccompiler.py 2011-09-08 14:14:03.000000000 +0200 +++ numpy/numpy/distutils/intelccompiler.py 2011-09-08 14:20:37.000000000 +0200 @@ -30,11 +30,11 @@ """ A modified Intel x86_64 compiler compatible with a 64bit gcc built Python. """ compiler_type = 'intelem' - cc_exe = 'icc -m64 -fPIC' + cc_exe = 'icc -m64 -fPIC -xHost -O3' cc_args = "-fPIC" def __init__ (self, verbose=0, dry_run=0, force=0): UnixCCompiler.__init__ (self, verbose,dry_run, force) - self.cc_exe = 'icc -m64 -fPIC' + self.cc_exe = 'icc -m64 -fPIC -xHost -O3' compiler = self.cc_exe self.set_executables(compiler=compiler, compiler_so=compiler,
--- numpy-1.6.1/numpy/distutils/intelccompiler.py 2011-10-06 16:55:12.000000000 +0200 +++ numpy-1.6.1/numpy/distutils/intelccompiler.py 2011-10-10 10:26:14.000000000 +0200 @@ -10,11 +10,13 @@ def __init__ (self, verbose=0, dry_run=0, force=0): UnixCCompiler.__init__ (self, verbose,dry_run, force) self.cc_exe = 'icc -fPIC' + self.cxx_exe = 'icpc -fPIC' compiler = self.cc_exe + compiler_cxx = self.cxx_exe self.set_executables(compiler=compiler, compiler_so=compiler, - compiler_cxx=compiler, - linker_exe=compiler, + compiler_cxx=compiler_cxx, + linker_exe=compiler_cxx, linker_so=compiler + ' -shared') class IntelItaniumCCompiler(IntelCCompiler):
--- numpy-1.6.1/numpy/distutils/fcompiler/intel.py.old 2011-10-10 17:52:34.000000000 +0200 +++ numpy-1.6.1/numpy/distutils/fcompiler/intel.py 2011-10-10 17:53:51.000000000 +0200 @@ -32,7 +32,7 @@ executables = { 'version_cmd' : None, # set by update_executables 'compiler_f77' : [None, "-72", "-w90", "-fPIC", "-w95"], - 'compiler_f90' : [None], + 'compiler_f90' : [None, "-fPIC"], 'compiler_fix' : [None, "-FI"], 'linker_so' : ["<F90>", "-shared"], 'archiver' : ["ar", "-cr"], @@ -129,7 +129,7 @@ 'version_cmd' : None, 'compiler_f77' : [None, "-FI", "-w90", "-fPIC", "-w95"], 'compiler_fix' : [None, "-FI"], - 'compiler_f90' : [None], + 'compiler_f90' : [None, "-fPIC"], 'linker_so' : ['<F90>', "-shared"], 'archiver' : ["ar", "-cr"], 'ranlib' : ["ranlib"] @@ -148,7 +148,7 @@ 'version_cmd' : None, 'compiler_f77' : [None, "-FI", "-w90", "-fPIC", "-w95"], 'compiler_fix' : [None, "-FI"], - 'compiler_f90' : [None], + 'compiler_f90' : [None, "-fPIC"], 'linker_so' : ['<F90>', "-shared"], 'archiver' : ["ar", "-cr"], 'ranlib' : ["ranlib"] @@ -180,7 +180,7 @@ 'version_cmd' : None, 'compiler_f77' : [None,"-FI","-w90", "-fPIC","-w95"], 'compiler_fix' : [None,"-FI","-4L72","-w"], - 'compiler_f90' : [None], + 'compiler_f90' : [None, "-fPIC"], 'linker_so' : ['<F90>', "-shared"], 'archiver' : [ar_exe, "/verbose", "/OUT:"], 'ranlib' : None @@ -232,7 +232,7 @@ 'version_cmd' : None, 'compiler_f77' : [None,"-FI","-w90", "-fPIC","-w95"], 'compiler_fix' : [None,"-FI","-4L72","-w"], - 'compiler_f90' : [None], + 'compiler_f90' : [None, "-fPIC"], 'linker_so' : ['<F90>',"-shared"], 'archiver' : [ar_exe, "/verbose", "/OUT:"], 'ranlib' : None
--- PyNIO-1.4.1/Nio.py 2011-09-14 16:00:13.000000000 +0200 +++ PyNIO-1.4.1/Nio.py 2011-09-14 16:00:18.000000000 +0200 @@ -98,7 +98,7 @@ if ncarg_dir == None or not os.path.exists(ncarg_dir) \ or not os.path.exists(os.path.join(ncarg_dir,"lib","ncarg")): if not __formats__['grib2']: - return None + return "" # "", because an env variable has to be a string. else: print "No path found to PyNIO/ncarg data directory and no usable NCARG installation found" sys.exit()
--- scipy/scipy/spatial/qhull/src/qhull_a.h 2011-02-27 11:57:03.000000000 +0100 +++ scipy/scipy/spatial/qhull/src/qhull_a.h 2011-09-09 15:42:12.000000000 +0200 @@ -102,13 +102,13 @@ #elif defined(__MWERKS__) && defined(__INTEL__) # define QHULL_OS_WIN #endif -#if defined(__INTEL_COMPILER) && !defined(QHULL_OS_WIN) -template <typename T> -inline void qhullUnused(T &x) { (void)x; } -# define QHULL_UNUSED(x) qhullUnused(x); -#else +/*#if defined(__INTEL_COMPILER) && !defined(QHULL_OS_WIN)*/ +/*template <typename T>*/ +/*inline void qhullUnused(T &x) { (void)x; }*/ +/*# define QHULL_UNUSED(x) qhullUnused(x);*/ +/*#else*/ # define QHULL_UNUSED(x) (void)x; -#endif +*/#endif*/ /***** -libqhull.c prototypes (alphabetical after qhull) ********************/
--- scipy/scipy/spatial/qhull/src/qhull_a.h 2011-09-09 15:43:54.000000000 +0200 +++ scipy/scipy/spatial/qhull/src/qhull_a.h 2011-09-09 15:45:17.000000000 +0200 @@ -102,13 +102,7 @@ #elif defined(__MWERKS__) && defined(__INTEL__) # define QHULL_OS_WIN #endif -/*#if defined(__INTEL_COMPILER) && !defined(QHULL_OS_WIN)*/ -/*template <typename T>*/ -/*inline void qhullUnused(T &x) { (void)x; }*/ -/*# define QHULL_UNUSED(x) qhullUnused(x);*/ -/*#else*/ # define QHULL_UNUSED(x) (void)x; -*/#endif*/ /***** -libqhull.c prototypes (alphabetical after qhull) ********************/
--- scipy-0.9.0/scipy/spatial/setup.py 2011-10-10 17:11:23.000000000 +0200 +++ scipy-0.9.0/scipy/spatial/setup.py 2011-10-10 17:11:09.000000000 +0200 @@ -22,6 +22,8 @@ get_numpy_include_dirs()], # XXX: GCC dependency! #extra_compiler_args=['-fno-strict-aliasing'], + # XXX intel compiler dependency + extra_compiler_args=['-lifcore'], ) lapack = dict(get_info('lapack_opt'))
I hope this helps someone out there saving some time - or even better: improving the upstream projects. At least it should be a nice reference for all who need to get scipy working on not-quite-supported architectures.
Happy Hacking!
: Actually I already wanted to publish that script more than a year ago, but time flies and there’s always stuff to do. But at least I now managed to get it done.
| Anhang | Größe |
|---|---|
| 2013-09-26-Do-installing-scipy-and-matplotlib-on-a-bare-cluster-with-the-intel-compiler.org [370] | 29.2 KB |
JSON, the javascript object notation format, is everywhere nowadays. But there are 3 facts which will challenge its dominance.
Due to these changes, servers will become CPU bound again, and basic data structures on the web will become much more relevant. But the most efficient parsing of JSON requires guessing the final data structure while reading the data.
Therefore the changing costs will bring a comeback for binary data structures, and WebAssembly will provide efficient parsers and emitters in the clients.
Look at a typical website and count how much of the dynamic data it uses is structured data. Due to this I expect that 5 years from now, there will be celebrity talks with titles like
Scaling 10x higher with streams of structured data.
(And yes, that tech communication often works like this is a problem.)
Update 2025: Protobuf - How Google Changed Data Serialization FOREVER [371] (youtube, 2023), Reduce Latency By 60% With ProtoBufs!!! [372] (youtube, 2023, reading from an article [373] that comments on a LinkedIn Techblog Entry [374] ). Also Flatbuffers [375] and Cap’n’Proto [376].
If you have deep-rooted doubts, have a look at Towards a JavaScript Binary AST [377], which convinced me to finally publish this article.
(and parsing JSON is a minefield [378])
Easily answering the question: “How much space does this need?”
We just had the problem to find out whether a given dataset will be shareable without complex trickery. So we took the easiest road and checked the memory requirements of the datastructure.
If you have such a need, there’s always a first stop: Fire up the interpreter and try it out.
We just created a three dimensional numpy array of floats and then looked at the memory requirement in the system monitor - conveniently bound to CTRL-ESC in KDE [208]. By making the array big enough we can ignore all constant costs and directly get the cost per stored value by dividing the total memory of the process by the number of values.
All our tests are done in Python3.
For numpy we just create an array of random values cast to floats:
import numpy as np
a = np.array(np.random.random((100, 100, 10000)), dtype="float")
Also we tested what happens when we use "f4" and "f2" instead of "float" as dtype in numpy.
For the native lists, we use the same array, but convert it to a list of lists of lists:
import numpy as np
a = [[[float(i) for i in j] for j in k]
for k in list(np.array(np.random.random((100, 100, 10000)), dtype="float"))]
Instead of using the full-blown numpy, we can also turn the inner list into an array.
import numpy as np
a = [[array.array("d", [float(i) for i in j]) for j in k]
for k in list(np.array(np.random.random((100, 100, 10000)), dtype="float"))]
With a numpy array we need roughly 8 Byte per float. A linked list however requires roughly 32 Bytes per float. So switching from native Python to numpy reduces the required memory per floating point value by factor 4.
Using an inner array (via array module) instead of the innermost list provides roughly the same gains.
I would have expected factor 3: The value plus a pointer to the next and to the previous entry.
The details are in the following table.
| total memory | per value | |
|---|---|---|
| list of floats | 3216.6 MiB | 32.166 Bytes |
| numpy array of floats | 776.7 MiB | 7.767 Bytes |
| np f4 | 395.2 MiB | 3.95 Bytes |
| np f2 | 283.4 MiB | 2.834 Bytes |
| inner array | 779.1 MiB | 7.791 Bytes |
This test was conducted on a 64 bit system, so floats are equivalent to doubles.
The scipy documentation provides a list of all the possible dtype definitions cast to C-types [379].
In Python large numpy arrays require 4 times less memory than a linked list structure with the same data. Using an inner array from the array module instead of the innermost list provides roughly the same gains.
We had a kinda long discussion [381] on identi.ca [382] about Ogg Theora [383] and h.264, and since we lacked a simple comparision method, I hacked up a quick script to test them.
It uses frames from Big Buck Bunny [384] and outputs the files bbb.ogg and bbb.264 (license: cc by [385]).
The ogg file looks like this:
The h.264 file looks like this: download [388]
What you can see by comparing both is that h.264 wins in terms of raw image quality at the same bitrate (single pass).
So why am I still strongly in favor of Ogg Theora?
The reason is simple:
Due to licensing costs of h.264 (a few millions per year, due from 2015 onwards) making h.264 the standard for internet video would have the effect that only big companies would be able to make a video enabled browser - or we would get a kind of video tax for free software: if you want to view internet video with free software, you have to pay for the right to use the x264 library (else the developers couldn't cough up the money to pay for the parent license). And noone but the main developers and huge corporations could distribute the x264 library, because they’d have to pay license fees for that.
And noone could hack on the browser or library and distribute the changed version, so the whole idea of free software would be led ad absurdum. It wouldn't matter that all code would be free licensed, since only those with a h.264 patent license could change it.
So this post boils down to a simple message:
Theoras raw quality may still be worse, but the license costs and their implications provide very clear reasons for supporting Theora - which in my view are far more important than raw technical stuff.
for k in {0..1}
do for i in {0..9}
do for j in {0..9}
do
wget http://media.xiph.org/BBB/BBB-360-png/big_buck_bunny_00$k$i$j.png
done
done
done
mplayer -vo yuv4mpeg -ao null -nosound mf://*png -mf fps=50
theora_encoder_example -z 0 --soft-target -V 400 -o bbb.ogg stream.yuv
mencoder stream.yuv -ovc x264 -of rawvideo -o bbb.264 -x264encopts bitrate=400 -aspect 16:9 -nosound -vf scale=640:360,harddup
| Anhang | Größe |
|---|---|
| bbb-400bps.ogg [386] | 212.88 KB |
| bbb-400bps.264 [388] | 214.39 KB |
| encode.sh [390] | 428 Bytes |
Phoronix recently did a benchmark of GCC vs. LLVM on AMD hardware [391]. Sadly their conclusion did not fit the data they showed. Actually it misrepresented the data so strongly, that I decided to speak up here instead of having my comments disappear in their forums [392]. This post was started on 2013-05-14 and got updates when things changed - first for the better, then for the worse.
Update 3 (the last straw, 2013-11-09): In the recent most blatant attack by Phoronix on copyleft programs - this time openly targeted at GNU [393] - Michael Larabel directly misrepresented a post from Josh Klint to badmouth GDB (Josh confirmed [394] this1). Josh gave a report of his initial experience with GDB in a Kickstarter Update [395] in which he reported some shortcomings he saw in GDB (of which the major gripe is easily resolved with better documentation2) and concluded with “the limitations of GDB are annoying, but I can deal with it. It's very nice to be able to run and debug our editor on Linux”. Michael Larabel only quoted the conclusion up to “annoying” and abused that to support the claim that game developers (in general) call GDB “crap” and for further badmouthing of GDB. With this he provided the straw which I needed to stop reading Phoronix: Michael Larabel is hostile to copyleft and in particular to GNU and he goes as far as rigging test results3 and misrepresenting words of others to further his agenda. I even donated to Phoronix a few times in the past. I guess I won’t do that again, either. I should have learned from the error of the german pirates and should have avoided reading media which is controlled by people who want to destroy what I fight for (sustainable free software).
Update 2 (2013-07-06): But the next [396] went down the drain again… “Of course, LLVM/Clang 3.3 still lacks OpenMP support, so those tests are obviously in favor of GCC.” — I couldn’t find a better way to say that those tests are completely useless while at the same time devaluing OpenMP support as “ignore this result along with all others where GCC wins”…
Update (2013-06-21): The recent report of GCC 4.8 vs. LLVM 3.3 [397] looks much better. Not perfect, but much better.
Taking out the OpenMP benchmarks (where GCC naturally won, because LLVM only processes those tests single-threaded) and the build times (which are irrelevant to the speed of the produced binaries), their benchmark [391] had the following result:
LLVM is slower than GCC by:
- 10.2% (HMMer)
- 12.7% (MAFFT)
- 6.8% (BLAKE2)
- 9.1% (HIMENO)
- 42.2% (C-Ray)
With these results (which were clearly visible on their result summary on OpenBenchmarking [398], Michael Larabel from Phoronix concluded:
» The performance of LLVM/Clang 3.3 for most tests is at least comparable to GCC «
Nobu [399] from their Forums supplied a conclusion which represents the data much better:
» GCC is much faster in anything which uses OpenMP, and moderately faster or equal in anything (except compile times) which doesn't [use OpenMP] «
But Michael from Phoronix did not stop at just ignoring the performance difference between GCC and LLVM. He went on claiming, that
In a few benchmarks LLVM/Clang is faster, particularly when it comes to build times.
And this is blatant reality-distortion which I am very tempted to ascribe to favoritism. LLVM is not “particularly” faster when it comes to build times.
LLVM on AMD FX-8350 Vishera is faster ONLY when it comes to build times!
This was not the first time that I read data-distorting conclusions on Phoronix - and my complaints about that in their forum did not change their actions. So I hope that my post here can help making them aware that deliberately distorting test results is unacceptable.
For my work, compiler performance is actually quite important, because I use programs which run for days or weeks, so 10% runtime reduction can mean saving several days - not counting the cost of using up cluster time.
To fix their blunders, what they would have to do is:
Their current approach gives a distinct disadvantage to GCC (even for the OpenMP tests, because they convey the notion that if LLVM only had OpenMP, it would be better in everything - which as this test shows is simply false), so the compiler-tests from Phoronix work as covert propaganda against GCC, even in tests where GCC flat-out wins. And I already don’t like open propaganda, but when the propaganda gets masked as objective testing, I actually get angry.
I hope my post here can help move them towards doing proper testing again.
PS: I write so strongly here, because I actually like the tests from Phoronix a lot. I think we need rather more than less testing and their testsuite actually seems to do a good job - when given the right parameters - so seeing Phoronix distorting the tests to a point where they become almost useless (except as political tool against GCC) is a huge disappointment to me.
Josh Klint from Leadwerks confirmed that Phoronix misrepresented his post and wrote a followup-post [400]: » @ArneBab That really wasn't meant to be controversial. I was hoping to provide constructive feedback from the view of an Xcode / VS user.« » Slightly surprised my complaints about GDB are a hot topic. I can make just as many criticisms of other compilers and IDEs.« » The first 24 hours are the best for usability feedback. I figure if they notice a pattern some of those things will be improved.« » GDB Follwup [400] « — @Leadwerks [401], 2:04 AM - 11 Nov 13 [394], 2:10 AM - 11 Nov 13 [402] and @JoshKlint [403], 2:07 AM - 11 Nov 13 [404], 8:48 PM - 11 Nov 13 [405]. ↩
The first-impression criticism [395] from Josh Klint was addressed by a Phoronix reader by pointing to the frame command [406]. I do not blame Josh for not knowing all tricks: He wrote a fair account of his initial experience with GDB (and he said later that he wrote the post after less than 24 hours of using GDB, because he considers that the best time to provide feedback) and his experience can serve as constructive criticism to improve tutorials, documentation and the UI of GDB. Sadly his visibility and the possible impact of his work on free software made it possible for Phoronix to abuse a personal report as support for a general badmouthing of the tool. In contrast the full message of Josh Klint ended really positive: Although some annoyances and limitations have been discovered, overall I have found Linux to be a completely viable platform for application development. — Josh Klint, Leadwerks ↩
I know that rigging of tests is a strong claim. The actions of Michael Larabel deserve being called rigging for three main reasons: (1) Including compile-time data along with runtime performance without clear distinction between both, even though compile-time of the full code is mostly irrelevant when you use a proper build system and compile time and runtime are completely different classes of results, (2) including pointless tests between incomparable setups whose only use is to relativate any weakness of his favorite system and (3) blatantly lying in the summaries (as I show in this article). ↩
(written on ohloh [407] for Python)
Since we already have two good reviews from experienced programmers, I'll focus on the area I know about: Python as first language.
My experience:
Advantages of Python:
How it looks:
def hello(user): print("Hello " + user + "!") hello("Fan") # prints Hello Fan! on screen
As a bonus, there is the great open book How to Think Like a Computer Scientist [408] which teaches Python and is being used for teaching Python and Programming at universities.
So I can wholeheartedly recommend Python to beginners in programming, and as the other reviews on Ohloh show, it is also a great language for experienced programmers and seems to be a good language to accompany you in your whole coding life.
PS: Yes, I know about the double meaning of "first language" :)
I recently read the little schemer [409] and that got me thinking about recursion and loops.
After starting my programming life with Python, I normally use for-loops to solve problems. But actually they are an inferior mechanism when compared to recursion, if (and only if) the language provides proper syntactic support for that. Since that claim pretty much damns Python on a theoretical level (even though it is still a very good tool in practice and I still love it!), I want to share a simplified version of the code which made me realize this.
Let’s begin with how I would write that code in Python.
res = "" instring = False for letter in text: if letter = "\"": # special conditions for string handling go here # lots of special conditions # and more special conditions # which cannot easily be moved out, # because we cannot skip multiple letters # in one step instring = not instring if instring: res += letter continue # other cases
Did you spot the comment “special conditions go here”? That’s the point which damns for-loops: You cannot easily factor out these special conditions.1 In this example all the complexity is in the variable instring. But depending on the usecase, this could require lots of different states being tracked within the loop and cluttering up the namespace as well as entangling complexity from different parts of the loop.
This is how the same could be done with proper let-recursion:
; first get SRFI-71: multi-value let for syntactic support for what I ; want to do use-modules : srfi srfi-71 let process-text : res "" letter : string-take text 1 unprocessed : string-drop text 1 when : equal? letter "\"" let-values ; all the complexity of string-handling is neatly ; confined in the helper-function consume-string : (to-res next-letter still-unprocessed) : consume-string unprocessed process-text string-append res to-res . next-letter . still-unprocessed ; other cases
The basic code for recursion is a bit longer, because the new values in the next step of the processing are given explicitly. But it is almost trivial to shell out parts of the loop to another function. It just needs to return the next state of the recursion.
And that’s what consume-string does:
define : consume-string text let : res "" next-letter : string-take text 1 unprocessed : string-drop text 1 ; lots of special handling here values res next-letter unprocessed
To recite from the Zen of Python [410]:
Explicit is better than implicit.
It’s funny to see how Guile Scheme [25] allows me to follow that principle more thoroughly than Python.
(I love Python, but this is a case where Scheme simply wins - and I’m not afraid to admit that)
PS: Actually I found this technique when thinking about use-cases for multiple return-values of functions.
PPS: This example uses wisp-syntax [411] for the scheme-examples to avoid killing Pythonistas with parens.
While you cannot factor out parts of for loops easily, functions which pass around iterators get pretty close to the expressivity of tail recursion. They might even go a bit further and I already missed them for some scheme code where I needed to generate expressions step by step from a function which always returned an unspecified number of expressions per call. If Python continues to make it easier to use iterators, they could reduce the impact of the points I make in this article. ↩
| Anhang | Größe |
|---|---|
| 2014-03-05-Mi-recursion-wins.org [412] | 3.36 KB |
The python startup time always nagged me (17-30ms) and I just searched again for a way to reduce it, when I found this:
The Python-Launcher [413] caches GTK imports and forks new processes to reduce the startup time of python GUI programs.
Python-launcher does not solve my problem directly, but it points into an interesting direction: If you create a small daemon which you can contact via the shell to fork a new instance, you might be able to get rid of your startup time.
To get an example of the possibilities, download the python-launcher [414] and socat [415] and do the following:
PYTHONPATH="../lib.linux-x86_64-2.7/" python python-launcher-daemon &
echo pass > 1
for i in {1..100}; do
echo 1 | socat STDIN UNIX-CONNECT:/tmp/python-launcher-daemon.socket &
done
Todo: Adapt it to a given program and remove the GTK stuff. Note the & at the end: Closing the socket connection seems to be slow, so I just don’t wait for socat to finish. Breaks at somewhere over 200 simultaneous connections. Option: Use a datagram socket instead.
The essential trick is to just create a server which opens a socket. Then it reads all the data from the socket. Once it has the data, it forks like the following:
pid = os.fork()
if pid:
return
signal.signal(signal.SIGPIPE, signal.SIG_DFL)
signal.signal(signal.SIGCHLD, signal.SIG_DFL)
glob = dict(__name__="__main__")
print 'launching', program
execfile(program, glob, glob)
raise SystemExit
Running a program that way 100-times took just 0.23 seconds for me so the Python startup time of 17ms got reduced to 2.3ms.
You might have to switch from forking to just executing the code instead of forking if you want to be even faster and the code snippets are small. For example when running the same test without the fork and the signals, 100 executions of the same code took just 0.09s, cutting down the startup time to an impressing 0.9ms - with the cost of no longer running in parallel.
(That’s what I also do with emacsclient… My emacs takes ~30s to start (due to excessive use of additional libraries I added), but emacsclient -c shows up almost instantly.)
I tested the speed by just sending a file with the following snippet to the server:
import time
with open("2", "a") as f:
f.write(str(time.time()) + "\n")
Note: If your script only needs the included python libraries (batteries) and no custom-installed libs, you can also reduce the startuptime by avoiding site initialization:
python -S [script]
Without -S python -c '' takes 0.018s for me. With -S I am down to
time python -S -c '' → 0.004s.
Note that you might miss some installed packages that way. This is slower than the daemon method by up to factor 4 (4ms instead of 0.9), but still faster than the default way. Note that cold disk buffers can make the difference much bigger on the first run which is not relevant in this case but very much relevant in general for the impression of startup speed.
PS: I attached the python-launcher 0.1.0 in case its website goes down. License: GPL and MIT; included. This message was originally written at stackoverflow [416].
| Anhang | Größe |
|---|---|
| python-launcher-0.1.0.tar.gz [417] | 11.11 KB |
Switching from GPLv2 or later [418] to AGPL [419] is perfectly legal. But if it is not your own project, it is often considered rude.
This does not relicense the original code, it just sets the license of new code and of the project as a whole. The old code stays GPLv2+, but when it is combined with the new code under AGPLv3 (or later), the combined project will be under AGPLv3 (or later).
However switching from GPL2+ to AGPL3(+) without consensus of all other contributors is considered rude, because it could prevent some of the original authors from using future versions of the project. Their professional use of the project might depend on the loopholes in the copyleft of the GPL.
And the ones you will want most of all as users of your fork of a mostly discontinued project are the original authors, because that can mend the split between the two versions.
This question came up in a continuation of a widely used package whose development seemed to have stalled. The discussion was unfocussed, so I decided to write succinct information for all who might find themselves in a similar situation. I will not link to them, because I do not wish to re-ignite the discussion through an influx of rehashed arguments.
GNU info is lightyears ahead of man in terms of features, with sub-pages, clickable links, topic-spanning search, clean html- and latex-export and efficient interactive navigation.
But man pages are still the de-facto standard for getting quick information on a GNU/Linux system.
This guide intends to help you change that for your system. It needs GNU texinfo >= 6.1.
Update: If you prefer vi-keys, adjust the function below to call
info --vi-keysinstead of plaininfo. You could then call that functioniv☺
I see strong reasons for sticking to man pages instead of info: man pages provide what most people need right away (how to use this?) and they fail fast if the topic is not available.
Their advanced features are mostly hidden away (i.e. checking the
Linux programmers manual instead of checking installed programs
man 2 stat vs. man stat).
Different from that, the default error state of info is to show you
all the other info nodes in which you are really not interested at the
moment. And man basename gives you the commandline invocation of the
basename utility, while info basename gives you libc "5.8 Finding
Tokens in a String".
Also man is fast. And works on most terminals, while info fails at
dumb ones.
In short: man does what most users need right now, and if it can’t do that, it simply fails, so the user can try something else. That’s a huge UI advantage, but not due to an inherent limitation of GNU info. GNU Info can do the same, and even defer to man pages for stuff for which there is no info document. It just does not provide that conveniently by default.
GNU Info can provide the same useful interface as man. So let’s make it do that.
To keep all flexibility without needing to adjust the PATH, let’s make
a bash function. That function can go into ~/.bashrc, or
/etc/bash/bashrc.1 I chose the latter, because it provides the
function for all accounts on the system and keeps it separate from the
general setup.
The function will be called i: To get information about any thing,
just call i thing.
Let’s implement that:
function i() { INFOVERSIONLINE=$(info --version | head -n 1) INFOVERSION="${INFOVERSIONLINE##* }" INFOGT5=$(if test ${INFOVERSION%%.*} -gt 5; then echo true; else echo false; fi) # start with special cases which are quick to check for if test $# -lt 1; then # show info help notice info --help elif test $# -gt 1 && ! echo $1 | grep -q "[0-9]"; then # user sent complex request, but not with a section command. Just use info info "$@" elif test $# -gt 1 && echo $1 | grep -q "[0-9]"; then # user sent request for a section from the man pages, we must defer to man man "$@" elif test x"$1" = x"info"; then # for old versions of info, calling info --usage info fails to # provide info about calling info if test x"$INFOGT5" = x"true"; then info --usage info else info --usage -f info-stnd fi elif test x"$1" = x"man"; then # info --all -w ./man fails to find the man man page info man else # start with a fast but incomplete info lookup INFOPAGELOCATION="$(info --all -w ./"$@" | head -n 1)" INFOPAGELOCATION_PAGENAME="$(info --all -w "$1".info | head -n 1)" INFOPAGELOCATION_COREUTILS="$(info -w coreutils -n "$@")" # check for usage from fast info, if that fails check man and # if that also fails, just get the regular info page. if test x"${INFOPAGELOCATION}" = x"*manpages*" || test x"${INFOPAGELOCATION}" != x""; then info "$@"; # use info to read the known page, man or info elif test x"${INFOPAGELOCATION_COREUTILS}" != "x" && info -f "${INFOPAGELOCATION_COREUTILS}" -n "$@" | head -n 1 | grep -q -i "$@"; then # coreutils utility info -f "${INFOPAGELOCATION_COREUTILS}" -n "$@" elif test x"${INFOPAGELOCATION}" = x"" && test x"${INFOPAGELOCATION_PAGENAME}" = x""; then # unknown to quick search, try slow search or defer to man. # TODO: it would be nice if I could avoid this double search. if test x"$(info -w "$@")" = x"*manpages*"; then info "$@" else # defer to man, on error search for alternatives man "$@" || (echo nothing found, searching info ... && \ while echo $1 | grep -q '^[0-9]$'; do shift; done && \ info -k "$@" && false) fi elif test x"${INFOPAGELOCATION_PAGENAME}" != x""; then # search for alternatives (but avoid numbers) info --usage -f "${INFOPAGELOCATION_PAGENAME}" 2>/dev/null || man "$@" ||\ (echo searching info &&\ while echo $1 | grep -q '^[0-9]$'; do shift; done && \ info -k "$@" && false) else # try to get usage instructions, then try man, then # search for alternatives (but avoid numbers) info --usage -f "${INFOPAGELOCATION}" 2>/dev/null || man "$@" ||\ (echo searching info &&\ while echo $1 | grep -q '^[0-9]$'; do shift; done && \ info -k "$@" && false) fi # ensure that unsuccessful requests report an error status INFORETURNVALUE=$? unset INFOPAGELOCATION unset INFOPAGELOCATION_COREUTILS if test ${INFORETURNVALUE} -eq 0; then unset INFORETURNVALUE return 0 else unset INFORETURNVALUE return 1 fi fi }
Let’s see what that gives us.
{{{fun}}}
i info | head
echo ...
Next: Cursor Commands, Prev: Stand-alone Info, Up: Top
2 Invoking Info
***************
GNU Info accepts several options to control the initial node or nodes
being viewed, and to specify which directories to search for Info files.
Here is a template showing an invocation of GNU Info from the shell:
info [OPTION...] [MANUAL] [MENU-OR-INDEX-ITEM...]
...
{{{fun}}}
i grep | head | sed 's/\[[0-9]*m//g' # stripping simple colors
echo ...
Next: Regular Expressions, Prev: Introduction, Up: Top
2 Invoking ‘grep’
*****************
The general synopsis of the ‘grep’ command line is
grep OPTIONS PATTERN INPUT_FILE_NAMES
There can be zero or more OPTIONS. PATTERN will only be seen as such
...
Note: If there’s a menu at the bottom, you can jump right to it’s entries by hitting the m key.
Checking for i stat gives us the stat command:
{{{fun}}}
i stat | head
Next: sync invocation, Prev: du invocation, Up: Disk usage
14.3 ‘stat’: Report file or file system status
==============================================
‘stat’ displays information about the specified file(s). Synopsis:
stat [OPTION]… [FILE]…
With no option, ‘stat’ reports all information about the given files.
…while checking for i libc stat gives us the libc function:
{{{fun}}}
i libc stat | head
Next: Testing File Type, Prev: Attribute Meanings, Up: File Attributes 14.9.2 Reading the Attributes of a File --------------------------------------- To examine the attributes of files, use the functions 'stat', 'fstat' and 'lstat'. They return the attribute information in a 'struct stat' object. All three functions are declared in the header file 'sys/stat.h'.
i man cleanly calls info man.
{{{fun}}}
i man | head | sed "s,\x1B\[[0-9;]*[a-zA-Z],,g" # stripping colors
man(1) General Commands Manual man(1)
NAME
man - Formatieren und Anzeigen von Seiten des Online-Handbuches (man
pages)
manpath - Anzeigen des Benutzer-eigenen Suchpfades für Seiten des
Online-Handbuches (man pages)
i 2 stat cleanly defers to man 2 stat
{{{fun}}}
i 2 stat | head | sed "s,\x1B\[[0-9;]*[a-zA-Z],,g" # stripping colors
STAT(2) Linux Programmer's Manual STAT(2)
NAME
stat, fstat, lstat, fstatat - get file status
SYNOPSIS
#include <sys/types.h>
#include <sys/stat.h>
In case there is no info directly available, do a keyword search and propose sources.
{{{fun}}}
i em | head
echo ...
nothing found, searching info ... "(emacspeak)Speech System" -- speech system "(cpio)Copy-pass mode" -- copy files between filesystems "(tar)Basic tar" -- create, complementary notes "(tar)problems with exclude" -- exclude, potential problems with "(tar)Basic tar" -- extract, complementary notes "(tar)Incremental Dumps" -- extract, using with --listed-incremental "(tar)Option Summary" -- incremental, summary "(tar)Incremental Dumps" -- incremental, using with --list "(tar)Incremental Dumps" -- list, using with --incremental ...
i thing gives you info on some thing. It makes using info just as
convenient as using man.
Its usage even beats man in convenience, since it defers to man if needed, offers alternatives and provides named categories instead of having to remember the handbook numbers to find the right function.
And as developer you can use texinfo [420] to provide high quality documentation in many formats. You can even include a comprehensive tutorial in your documentation while still enabling your users to quickly reach the information they need.
We had this all along, except for a few nasty roadblocks. Here I did my best to eliminate these roadblocks.
Or it can go into /etc/bash/bashrc.d/info.sh (if you have a bashrc directory). That is the cleanest option.
| Anhang | Größe |
|---|---|
| 2016-09-12-Mo-replacing-man-with-info.org [421] | 10.46 KB |
I just discovered tabbing of everything in KDE:
(download [422])
Created with recordmydesktop [423], cut with kdenlive [424], encoded to ogg theora with ffmpeg2theora [425] (encoding command [426]).
Music: Beat into Submission [427] on Public Domain [428] by Tryad.
To embed the video on your own site you can simply use:
<video
src="http://draketo.de/files/screencast-tabbing-everywhere-kde.ogv"
controls=controls>
</video>
If you do so, please provide a backlink here.
License: cc by-sa [429], because that’s the license of the song. If you omit the audio, you can also use one of my usual free licenses [430] (or all of them, including the GPL). Here’s the raw recording [431] (=video source).
¹: Feel free to upload the video to youtube or similar. I license my stuff under free licenses to make it easy for everyone to use, change and spread them.
²: Others have shown this before, but I don’t mind that. I just love the feature, so I want to show it :)
³: The command wheel I use for calling programs is the pyRad [432].
| Anhang | Größe |
|---|---|
| screencast-tabbing-everywhere-kde.ogv [422] | 10.75 MB |
Creating a daemon with almost zero effort.
The example with the start-stop-daemon uses Gentoo OpenRC as root.
The simplest daemon we can create is a while loop:
echo '#!/bin/sh' > whiledaemon.sh echo 'while true; do true; done' >> whiledaemon.sh chmod +x whiledaemon.sh
Now we start it as daemon
start-stop-daemon --pidfile whiledaemon.pid \ --make-pidfile --background ./whiledaemon.sh
Top shows that it is running:
top | grep whiledaemon.sh
We stop it using the pidfile:
start-stop-daemon --pidfile whiledaemon.pid \ --stop ./whiledaemon.sh
That’s it.
Hint: To add cgroups support on a Gentoo [279] install, open /etc/rc.conf and uncomment
rc_controller_cgroups="YES"Then in the initscript you can set the other variables described below that line. Thanks for this hint goes to Luca Barbato [435]!
If you want to ensure that the daemon keeps running without checking a PID file (which might in some corner cases fail because a new process claims the same PID), we can use runsvdir [436] from runit.
Minimal examples for runit daemons - first as unpriviledged user, then as root.
Create a script which dies
echo '#!/usr/bin/env python\nfor i in range(100): a = i*i' >/tmp/foo.py chmod +x /tmp/foo.py
Create the daemon folder
mkdir -p ~/.local/run/runit_services/python ln -sf /tmp/foo.py ~/.local/run/runit_services/python/run
Run the daemon via runsvdir
runsvdir ~/.local/run/runit_services
Manage it with sv (part of runit)
# stop the running daemon SVDIR=~/.local/run/runit_services/ sv stop python # start the service (it shows as `run` in top) SVDIR=~/.local/run/runit_services/ sv start python
Minimal working example for setting up runit as root - like a sysadmin might do it.
echo '#!/usr/bin/env python\nfor i in range(100): a = i*i' >/tmp/foo.py && chmod +x /tmp/foo.py && mkdir -p /run/arne_service/python && printf '#!/bin/sh\nexec /tmp/foo.py' >/run/arne_service/python/run && chmod +x /run/arne_service/python/run && chown -R arne /run/arne_service && su - arne -c 'runsvdir /run/arne_service'
Or without bash indirection (giving up some flexibility we don’t need here)
echo '#!/usr/bin/env python\nfor i in range(100): a = i*i' >/tmp/foo.py && chmod +x /tmp/foo.py && mkdir -p /run/arne_service/python && ln -s /tmp/foo.py /run/arne_service/python/run && chown -R arne /run/arne_service && su - arne -c 'runsvdir /run/arne_service'
| Anhang | Größe |
|---|---|
| 2015-04-15-Mi-simple-daemon-openrc.org [434] | 2.92 KB |
| 2015-04-15-Mi-simple-daemon-openrc.pdf [433] | 152.99 KB |
Update: I nowadays think that voting down is useful, but only for protection against spam and intentional disruption of communication. Essentially a distributed function to report spam.
I don’t see a reason for negative reputation schemes — voting down is in my view a flawed concept.
The rest of this article is written for freetalk inside freenet [437], and also posted there with my nonanonymous ID.
That just allows for community censorship, which I see as incompatible with the goals of freenet.
Would it be possible to change that to use only positive votes and a threshhold?
Usecase:
In the current scheme (as I understand it), zwister wouldn’t see posts from Lilith.
In a pure positive scheme, zwister would see the posts. If zwister wants to avoid seeing the posts from Lilith, he has to untrust Alice or ask Alice to untrust Lilith. Add to that a personal (and not propagating) blocking option which allows me to “never see anything from Lilith again”.
Bob should not be able to interfere with me seeing the messages from Lilith, when Alice trusts Lilith.
If zwisters trust for Alice (0..1) multiplied with Alices trust for Lilith (0..1) is lower than zwisters threshhold, zwister doesn’t see the messages.
PS: somehow adapted from Credence [438], which would have brought community spam control to Gnutella, if Limewire had adopted it.
PPS: And adaption for news voting: You give positive votes on news which show up. Negative votes assign a private threshhold to the author of the news, so you then only see news from that author which enough people vote for.
Here's the simple steps to attach a GPL license to your source files (written after requests by DiggClone [439] and Bandnet [440]):
For your own project, just add the following text-notice to the header/first section of each of your source-files, commented out in whatever way your language uses:
----------------following is the notice-----------------
/*
* Your Project Name - -you slogan-
* Copyright (C) 2007 - 2007 Your Name
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
*/
----------------------------------------------
the "2007 - 2007" needs to be adjusted to "year when you gave it the license in the first place" - "current year".
Then put the file gpl.txt into the source-folder or a docs folder: http://www.gnu.org/licenses/gpl.txt [441]
If you are developing together with other people, you need their permission to put the project under the GPL.
------
Just for additional Info, I found this license comparision paper by sun: http://mediacast.sun.com/share/webmink/SunLicensingWhitePaper042006.pdf [442]
And comments to it: http://blogs.sun.com/webmink/entry/open_source_licensing_paper#comments [443]
It does look nice, but it misses one point:
GPL is trust: Contributors can trust, that their contributions will keep helping the community, and that the software they contribute to will keep being accessible for the community.
(That's why I decided some years ago to only support GPL projects. My contributions to one semi-closed project got lost, because the project wasn't free and the developer just decided not to offer them anymore, and I could only watch hundreds of hours of work disappear, and that hurt.)
Best wishes,
Arne
PS: If anything's missing, please write a comment!
heavily outdated page. See bitbucket.org/ArneBab [444] for many more projects…
Hi,
I created some projects with pyglet and some tools to facilitate 2D
game development (for me), and I though you might be interested.
They are avaible from the rpg-1d6 project on sourceforge:
-> https://sf.net/projects/rpg-1d6/ [445]
The download can be found at the sf.net download page:
-> https://sourceforge.net/project/showfiles.php?group_id=199744 [446]
a reply I wrote on quora [447].
Python is easy to learn and low ceremony. Both are pretty hard targets to hit. It also has great libraries for scientific work, for system scripting and for web development — and for most everything else. And it is pragmatic in a sense: It gets stuff done. And in a way which others can typically understand easily. Which is an even harder target to hit, especially with low ceremony languages. If you look for reasons, import this aka PEP 20 -- The Zen of Python [448] is a good start.
Python has rightfully been called “Pseudocode which actually runs”. There’s often no need for pseudocode if you can show some Python.
However it has its weaknesses. Many here already talked about performance. I won’t go there, because you can fix most of that with cython, pypy and time (as the javascript engines in Browsers show which often get 50% of the speed of optimized C). What irks me are some limitations in its syntax which I begun to hit more and more about two years ago.
List comprehensions make actual code more complicated than simple examples, because you have kind of a dual syntax to it. And there is some ceremony in tools which were added later. For example this is the template I nowadays use to start a Python project: a minimal Python script [449] — this could be part of the language so that I would not even need to put it into the script. But this is not how history works: It cannot break backwards compatibility (a fate which hits all useful and widespread programming languages). Also things like having to spell out the underscore names feel more and more strange to me. Therefore I started into Guile Scheme to see how different programming could be if I shed the constraints of Python. You can read my journey in py2guile: Going from Python to Guile Scheme - a natural progression [146] (a free ebook).
Also see my other Python-articles [450] on this site.
I recently started really learning Fortran (as opposed to just dabbling with existing code until it did what I wanted it to).
Here I document the surprises I found along the way.
If you want a quick start into Fortran, I’d suggest to begin with the tutorial Writing a commandline tool in Fortran [311] and then to come back here to get the corner cases right.
As reference: I come from Python, C++ and Lisp, and I actually started to like Fortran while learning it. So the horror-stories I heard while studying were mostly proven wrong. I uploaded the complete code as base60.f90 [451].
This is a code sample for calculating a base60 value from an integer.
The surprises are taken out of the program and marked with double angle brackets («surprise»). They are documented in the chapter Surprises.
program base60 ! first step: Base60 encode. ! reference: http://faruk.akgul.org/blog/tantek-celiks-newbase60-in-python-and-java/ ! 5000 should be 1PL implicit none <<declare-function-type-program>> <<function-test-calls>> end program base60
<<declare-function-type-function>> implicit none !!! preparation <<unchanged-argument>> <<parameter>> ! work variables integer :: n = 0 integer :: remainder = 0 ! result <<variable-declare-init>> ! actual algorithm if (number == 0) then <<return>> end if ! calculate the base60 string <<variable-reset>> n = number ! the input argument: that should be safe to use. ! catch number = 0 do while(n > 0) remainder = mod(n, 60) n = n/60 <<indizes-start-at-1>> ! write(*,*) number, remainder, n end do <<return-end>>
write(*,*) 0, trim(numtosxg(0)) write(*,*) 100000, trim(numtosxg(100000)) write(*,*) 1, trim(numtosxg(1)) write(*,*) 2, trim(numtosxg(2)) write(*,*) 60, trim(numtosxg(60)) write(*,*) 59, trim(numtosxg(59))
! I have to declare the return type of the function in the main program, too. character(len=1000) :: numtosxg
character(len=1000) function numtosxg( number )
Alternatively to declaring the function in its header, I can also declare its return type in the declaration block inside the function body:
function numtosxg (number) character(len=1000) :: numtosxg end function numtosxg
This even happens, when I initialize the variable when I declare it:
character(len=1000) :: res = ""
Due to that I have to begin the algorithm with resetting the required variable.
res = " " ! I have to explicitely set res to " ", otherwise it ! accumulates the prior results!
This provides a hint that initialization in a declaration inside a function is purely compile-time.
program accumulate implicit none integer :: acc write(*,*) acc(), acc(), acc() ! prints 1 2 3 end program accumulate integer function acc() implicit none integer :: ac = 0 ac = ac + 1 acc = ac end function acc
program accumulate implicit none integer :: acc write(*,*) acc(), acc(), acc() ! prints 1 1 1 end program accumulate integer function acc() implicit none integer :: ac ac = 0 ac = ac + 1 acc = ac end function acc
Defining a variable as parameter gives a constant, not an unchanged function argument:
! constants: marked as parameter: not function parameters, but ! algorithm parameters! character(len=61), parameter :: base60chars = "0123456789"& //"ABCDEFGHJKLMNPQRSTUVWXYZ_abcdefghijkmnopqrstuvwxyz"
An argument the function is not allowed to change is defined via intent(in):
! input: ensure that this is purely used as input. ! intent is only useful for function arguments. integer, intent(in) :: number
This feels surprisingly obvious, but it was surprising to me nontheless.
numtosxg = "0" return
The return statement is only needed when returning within a function. At the end of the function it is implied.
numtosxg = res end function numtosxg
For an algorithm like the example base60, where 0 is identified by the first character of a string, this requires adding 1 to the index.
! note that fortran indizes start at 1, not at 0. res = base60chars(remainder+1:remainder+1)//trim(res)
Also note that the indizes are inclusive. The following actually gets the single letter at index n+1:
base60chars(n+1:n+1)
In python on the other hand, the second argument of the array is exclusive, so to get the same result you would use [n:n+1]:
pythonarray[n:n+1]
It is necessary to get rid of trailing blanks (whitespace) from the last char to the end of the declared memory space, otherwise there will be huge gaps in combined strings - or you will get missing characters.
program test character(len=5) :: res write(*,*) res ! undefined. In the last run it gave me null-bytes, but ! that is not guaranteed. res = "0" write(*,*) res ! 0 res = trim(res)//"a" write(*,*) res ! 0a res = res//"a" write(*,*) res ! 0a: trailing characters are silently removed. ! who else expected to see 0aa? write(res, '(a, "a")') trim(res) ! without trim, this gives an error! ! *happy* write(*,*) res end program test
Hint from Alexey: use trim(adjustl(…)) to get rid of whitespace on the left and the right side of the string. Trim only removes trailing blanks.
| Anhang | Größe |
|---|---|
| surprises.org [454] | 8.42 KB |
| accumulate.f90 [455] | 226 Bytes |
| accumulate-not.f90 [456] | 231 Bytes |
| base60-surprises.f90 [457] | 1.6 KB |
| trim.f90 [458] | 501 Bytes |
| surprises.pdf [459] | 206.83 KB |
| surprises.html [460] | 22.47 KB |
| base60.f90 [451] | 2.79 KB |
TCO: Reducing the algorithmic complexity of recursion.
Debug build: Add overhead to a program to trace errors.
Debug without TCO: Obliterate any possibility of fixing recursion bugs.“Never develop with optimizations which the debug mode of the compiler of the future maintainer of your code does not use.”° [461]
UPDATE: GCC [462] 4.8 gives us -Og -foptimize-sibling-calls which generates nice-backtraces [463], and I had a few quite embarrassing errors in my C - thanks to AKF for the catch!
Tail Call Optimization (TCO) makes this
def foo(n): print(n) return foo(n+1)
foo(1)
behave like this
def foo(n): print(n) return n+1
n = 1 while True: n = foo(n)
I recently told a colleague how neat tail call optimization in scheme is (along with macros, but that is a topic for another day…).
Then I decided to actually test it (being mainly not a schemer but a pythonista - though very impressed by the possibilities of scheme).
So I implemented a very simple recursive function which I could watch to check the Tail Call behaviour. I tested scheme (via guile), python (obviously) and C++ (which proved to provide a surprise).
(define (foo n) (display n) (newline) (foo (1+ n))) (foo 1)
def foo(n): print n return foo(n+1) foo(1)
The C++ code needed a bit more work (thanks to AKF for making it less ugly/horrible!):
#include <stdio.h> int recurse(int n) { printf("%i\n", n); return recurse(n+1); } int main() { return recurse(1); }
Additionally to the code I added 4 different ways to build the code: Standard optimization (-O2), Debug (-g), Optimized Debug (-g -O2), and only slightly optimized (-O1).
all : C2 Cg Cg2 C1 # optimized C2 : tailcallc.c g++ -O2 tailcallc.c -o C2 # debug build Cg : tailcallc.c g++ -g tailcallc.c -o Cg # optimized debug build Cg2 : tailcallc.c g++ -g -O2 tailcallc.c -o Cg2 # only slightly optimized C1 : tailcallc.c g++ -O1 tailcallc.c -o C1
So now, let’s actually check the results. Since I’m interested in tail call optimization, I check the memory consumption of each run. If we have proper tail call optimization, the required memory will stay the same over time, if not, the function stack will get bigger and bigger till the program crashes.
Scheme gives the obvious result. It starts counting numbers and keeps doing so. After 10 seconds it’s at 1.6 million, consuming 1.7 MiB of memory - and never changing the memory consumption.
Python is no surprise either: it counts to 999 and then dies with the following traceback:
Traceback (most recent call last): File "tailcallpython.py", line 6, in <module> foo(1) File "tailcallpython.py", line 4, in foo return foo(n+1) … repeat about 997 times … RuntimeError: maximum recursion depth exceeded
Python has an arbitrary limit on recursion which keeps people from using tail calls in algorithms.
C/C++ is a bit trickier.
First let’s see the results for the optimized run:
g++ -O2 C.c -o C2 ./C2
Interestingly that runs just like the scheme one: After 10s it’s at 800,000 and consumes just 144KiB of memory. And that memory consumption stays stable.
So, cool! C/C++ has tail call optimization. Let’s write much recursive tail call using code!
Or so I thought. Then I did the debug run.
g++ -g C.c -o Cg ./Cg
It starts counting just like the optimized version. Then, after about 5 seconds and counting to about 260,000, it dies with a segmentation fault.
And here’s a capture of its memory consumption while it was still running (thanks to KDEs process monitor):
Private
7228 KB [stack] 56 KB [heap] 40 KB /usr/lib64/gcc/x86_64-pc-linux-gnu/4.7.2/libstdc++.so.6.0.17 24 KB /lib64/libc-2.15.so 12 KB /home/arne/.emacs.d/private/journal/Cg
Shared
352 KB /usr/lib64/gcc/x86_64-pc-linux-gnu/4.7.2/libstdc++.so.6.0.17 252 KB /lib64/libc-2.15.so 108 KB /lib64/ld-2.15.so 60 KB /lib64/libm-2.15.so 16 KB /usr/lib64/gcc/x86_64-pc-linux-gnu/4.7.2/libgcc_s.so.1
That’s 7 MiB after less than 5 seconds runtime - all of it in the stack, since that has to remember all the recursive function calls when there is no tail call optimization.
So we now have a program which runs just fine when optimized but dies almost instantly when run in debug mode.
But at least we have nice gdb traces for the start:
recurse (n=43) at C.c:5
5 printf("%i\n", n);
43
6 return recurse(n+1);
So, is all lost? Luckily not: We can actually specify optimization with debugging information.
g++ -g -O2 C.c -o Cg2 ./Cg2
When doing so, the optimized debug build chugs along just like the optimized build without debugging information. At least that’s true for GCC.
But our debug trace now looks like this:
5 printf("%i\n", n);
printf (__fmt=0x40069c "%i\n") at /usr/include/bits/stdio2.h:105
105 return __printf_chk (__USE_FORTIFY_LEVEL - 1, __fmt, __va_arg_pack ());
5
6 return recurse(n+1);
That’s not so nice, but at least we can debug with tail call optimization.
We can also improve on this (thanks to AKF [464] for that hint!): We just need to enable tail call optimization separately:
g++ -g -O1 -foptimize-sibling-calls C.c -o Cgtco ./CgBut this still gives ugly backtraces (if I leave out -O1, it does not do TCO). So let’s turn to GCC 4.8 and use -Og.
g++ -g -Og -foptimize-sibling-calls C.c -o Cgtco ./CgtcoAnd we have nice backtraces!
recurse (n=n@entry=1) at C.c:4
4 {
5 printf("%i\n", n);
1
6 return recurse(n+1);
5 printf("%i\n", n);
2
6 return recurse(n+1);
Can we invert the question? Is all well, now?
Actually not…
If we activate minor optimization, we get the same unoptimized behaviour again.
g++ -O1 C.c -o C1 ./C1
It counts to about 260,000 and then dies from a stack overflow. And that is pretty bad™, because it means that a programmer cannot trust his code to work when he does not know all the optimization strategies which will be used with his code.
And he has no way to define in his code, that it requires TCO to work.
Tail Call Optimization (TCO) turns an operation with a memory requirement of O(N)1 into one with a memory requirement of O(1).
It is a nice tool to reduce the complexity of code, but it is only safe in languages which explicitely require tail call optimization - like Scheme.
And from this we can find a conclusion for compilers:
C/C++ compilers should always use tail call optimization, including debug builds, because otherwise C/C++ programmers should never use that feature, because it can make it impossible to use certain optimization settings in any code which includes their code.
And as a finishing note, I’d like to quote (very loosely) what my colleague told me from some of his real-life debugging experience:
“We run our project on an AIX ibm-supercomputer. We had spotted a problem in optimized runs, so we activated the debugger to trace the bug. But when we activated debug flags, a host of new problems appeared which were not present in optimized runs. We tried to isolate the problems, but they only appeared if we ran the full project. When we told the IBM coders about that, they asked us to provide a simple testcase… The problems likely happened due to some crazy optimizations - in our code or in the compiler.”
So the problem of undebuggable code due to a dependency of the program on optimization changes is not limited to tail call optimization. But TCO is a really nice way to show it :)
Let’s use that to make the statement above more general:
C/C++ compilers should always do those kinds of optimizations which lead to changes in the algorithmic cost of programs.
Or from a pessimistic side:
You should only rely on language features, which are also available in debug mode - and you should never develop your program with optimization turned on.
And by that measure, C/C++ does not have Tail Call Optimization - at least until all mainstream compilers include TCO in their default options. Which is a pretty bleak result after the excitement I felt when I realized that optimizations can actually give C/C++ code the behavior of Tail Call Optimization.
Never develop with optimizations which the debug mode of the compiler of the future maintainer of your code does not use. — AB [465] ⇒ Never develop with optimizations which are not required by the language standard.
Note, though, that GCC 4.8 added the -Og option [466], which improves the debugging a lot (Phoronix wrote about plans for that last september [467]). It still does not include -foptimize-sibling-calls in -Og, but that might be only a matter of time… I hope it is.
1 : O(1) and O(N) describe the algorithmic cost of an algorithm. If it is O(N), then the cost rises linearly with the size of the problem (N is the size, for example printing 20,000 consecutive numbers). If it is O(1), the cost is stable regardless of the size of the problem.
systemd [468] is a new way to start a Linux-system with the expressed goal of rethinking all of init. These are my top 5 gripes with it. (»skip the updates«) [469]
Update (2019): I now use GNU Guix [470] with shepherd [471]. That’s one more better option than systemd. In that it joins OpenRC [472] and many others [473].
Update (2016-09-28): Systemd is an exploit kit just waiting to be activated. And once it is active, only those who wrote it will be able to defuse it — and check whether it is defused. And it is starting: How to crash systemd in one tweet? [474] Alternatives? Use OpenRC [475] for system services. That’s simple and fast and full-featured with minimal fuss. Use runit [476] for process supervision of user-services and system-services alike.
Update (2014-12-11): One more deconstruction of the strategies around systemd: systemd: Assumptions, Bullying, Consent [477]. It shows that the attitude which forms the root of the dangers of systemd is even visible in its very source code.
Update (2014-11-19): The Debian General Resolution [478] resulted in “We do not need a general resolution to decide systemd”. The vote page provides detailed results and statistics [479]. Ian Jackson resigned from the Technical Committee [480]: “And, speaking personally, I am exhausted.”
Update (2014-10-16): There is now a vote on a General Resolution [481] in Debian for preserving the ability to switch init systems. It is linked under “Are there better solutions […]?” on the site Shall we fork Debian™? :^| [482].
Update (2014-10-07): Lennart hetzt [483] (german) describes the rhetoric tricks used by Lennart Poettering to make people forget that he is a major part of the communication problems we’re facing at times - and to hide valid technical, practical, pragmatical, political und strategical criticism [484] of Systemd.
Update (2014-09-24): boycott systemd calls for action with 12 reasons against systemd [485]: “We do recognize the need for a new init system in the 21st century, but systemd is not it.”
Update (2014-04-03): And now we have Julian Assange warning about NSA control over Debian [486], Theodore Ts’o, maintainer of ext4, complaining about incomprehensible systemd [487], and Linus Torvalds (you know him, right?) rant against disrupting behavior from systemd developers [488], going as far as refusing to merge anything from the developers in question into Linux. Should I say “I said so”? Maybe not. After all, I came pretty late. Others saw this trend 2 years before I even knew about systemd. Can we really assume that there won’t be intentional disruption [489]? Maybe I should look for solutions. It could be a good idea to start having community-paid developers [490].
Update (2014-02-18): An email to the mailing list of the technical committee of debian summarized the strategic implications of systemd-adoption for Debian and RedHat [491]. It was called conspiracy theory right away, but the gains for RedHat are obvious: RedHat would be dumb not to try this. And only a fool trusts a company. Even the best company has to put money before ethics [492].
Update (2013-11-20): Further [493] reading [494] shows [495] that [496] people [497] have been giving arguments from my list since 2011, and they got answers in the range of “anything short of systemd is dumb”, “this cannot work” (while OpenRC [472] clearly shows that it works well), requests for implementation details without justification [498] and insults [499] and further insults [500]; but the arguments stayed valid for the last 2 years. That does not look like systemd has a friendly community - or is healthy for distributions adopting it. Also an OpenRC developer wrote the best rebuttal of systemd propaganda I read so far: “Alternativlos”: Systemd propaganda [501] (note, though, that I am biased against systemd due to problems I had in the past with udev kernel-dependencies)
Losing Control: systemd does so many crucial things itself that the developers of distributions lose their control over the init process: If systemd developers decide to change something, the distributions might actually have to fork systemd and keep the fork up-to-date, and this requires rare skills and lots of resources (due to the pace of systemd). See the Gentoo eudev-Project [502] for a case where this had to happen so the distribution could keep providing features its users rely on. Systemd nowadays incorporates udev. Go reason how systemd devs will act.1 Why losing control is a bad idea: Strategy Letter V: Commodities [503]
No scripts (as if you can know beforehand all the things the init system will need to do in each distribution). Nowadays any system should be user-extendable to avoid bottlenecks for development. This essentially boils down to providing a scripting language. Using the language which almost every system administrator knows is a very sane choice for that - and means making it possible to use Shell-Scripts to extend the init-system. Scripts mean that the distribution will never be in a position where it is blocked because it absolutely can’t provide a given fringe feature. And as the experiment with paludis in Gentoo shows [504], an implementation in C isn’t magically faster than one in a scripting language and can actually be much slower (just compare paludis to pkgcore), because the execution time of the language only very rarely is the real bottleneck - and you can easily shell out that part to a faster language with negligible time loss,2 especially in shell-scripts (pun partially intended). While systemd can be told to run a shell script, this requires a mental context switch and the script cannot tie into all the machinery inside systemd. If there’s a bug in systemd, you need to fix systemd, if you need more than systemd provides out of the box, you need either a script or you have to patch systemd, and otherwise you write in a completely different language (so most people won’t have the skills to go beyond the fences of the ground defined by the systemd developers as proper for users). Why killing scripts is a bad idea: Bloatware and the 80/20 Myth [505]
Linux-specific3 (are you serious??). This makes the distribution an add-on to the kernel instead of the distribution being a focus point of many different development efforts. This is a second point where distributions become commodities, and as for systemd itself, this is against the interest of the distributions. On the other hand, enabling the use of many different kernels strengthens the Distribution - even if currently only few people are using them. Why being Linux-only is a bad idea for distributions: Strategy Letter V: Commodities [503]
Requiring an up-to-date kernel. This problem already gives me lots of headaches for my OLPC due to udev (from the same people as systemd… which is one of the reasons why I hope that Gentoo-devs will succeed with eudev [502]), since it is not always easy to go to a newer kernel when you’re on a fringe platform (I’m currently fighting with that). An init system should not require some special kernel version just to boot… Why those hard dependencies are a bad idea: Bloatware and the 80/20 Myth [505] AND Strategy Letter V: Commodities [503]
Requiring D-Bus. D-Bus was already broken a few times for me, and losing not just some KDE functionality but instead making my system unbootable is unacceptable. It’s bad enough that so much stuff relies on udev.4
In my understanding, we need more services which can survive without the others, so the system gets resilient against failures in a given part. As the system gets more and more complex, this constantly gets more important: Less interdependencies, and the services which are crucial to get my system in a debuggable state should be small and simple - and should not require many changes to implement new features.
Having multiple tools to solve the same problem looks like wasted resources, but actually this extends the range of problems which can be solved with our systems and avoids bottlenecks and single points of failure (either tools or communities), so it makes us resilient. Also it encourages standard-formats to minimize the cost of maintaining several systems side-by-side.
You can see how systemd manages to violate all these principles…
This does not mean, that the features provided by systemd are useless. It says that the way they are embedded in systemd with its heavy dependencies is detrimental to a healthy distribution.
Note: I am neither a developer of systemd, nor of upstart, sysvinit or OpenRC. I am just a humble user of distributions, but I can recognize impending horrible fallout when I see it.
References:
I’ll finish this with a quote from 30 myths about systemd [507], written by the systemd developers themselves:
We try to get rid of many of the more pointless differences of the various distributions in various areas of the core OS. As part of that we sometimes adopt schemes that were previously used by only one of the distributions and push it to a level where it's the default of systemd, trying to gently push everybody towards the same set of basic configuration.
— Lennart Poettering, main developer of systemd
I could not show much clearer why distributions should be very wary about systemd than Lennart Poettering does here in the post where he tries to refute myths about systemd.
PS: I’m definitely biased against systemd, after having some horrifying experiences with kernel-dependencies in udev. Resilience looks different. And I already modified some init scripts to adjust my systems behavior so it better fits my usecase. Now go and call me part of a fringe group which wants to add “pointless differences” to the system. If you force Gentoo devs to issue a warning in the style of “you MUST activate feature X in your kernel, else your system will become unbootable”, this should be a big red flag to you that you’re doing something wrong. If you do that twice, this is a big red flag to users not to trust your software. And regaining that trust requires reestablishing a long record of solid work. Which I do not see at the moment. Also do read Bloatware and the 80/20 Myth [505] (if you didn’t do that by now): It might be true that 80% of the users only use 20% of the features, but they do not use the same 20%.
Update 2014: Actually there is no need to guess how the systemd developers will act: They showed (again) that they will keep breaking systems of their users: “udev now silently fails to do anything useful if devtmpfs is missing, almost as if resilience was a disease” — bonsaikitten, Gentoo developer, 2014-01, long after udev was subsumed into systemd. ↩
Running a program in a subshell increases the runtime by just six milliseconds. I measured that when testing ways to run GNU Guile modules as scripts [508]. So you have to start almost 100 subshells during bootup to lose half a second of runtime. Note that OpenRC can boot a system and power down again in under 0.7 seconds [509] and the minimal boot-to-login just takes 250 ms [510]. There is no need for systemd to get a faster boot. ↩
The systemd proponents in the debian initsystem discussion explicitly stated [511] that they don’t want to port systemd to other kernels. ↩
And D-Bus is slow, slow, slow when your system is under heavy memory and IO-pressure, as my systems tend to be (I’m a Gentoo [279] user. I often compile a new version of all KDE-components or of Firefox while I do regular work on the computer). From dbus I’m used to reaction times up to several seconds… ↩
I wanted to name Transcom Regions [512] in my plots by passing their names to the command-line tool, but I only had their region-number and a lookup dictionary in Python. To avoid tampering with the tool, I needed to translate the dictionary to a bash function, and thanks to the case statement [513] it was much simpler than I had expected.
This is the original dictionary:
#: Names of transcom regions transcomregionnames = { 1: "NAM Boreal", 2: "NAM Temperate", 3: "South American tropical", # and so forth }
This is how lookup works in Python:
region = 2 name = transcomregionnames[region]
The solution in bash is a simple mechanic translation:
function regionname () { number="$1" case $number in 1) echo "NAM Boreal";; 2) echo "NAM Temperate";; 3) echo "South American tropical";; # and so forth esac }
And the lookup is easier than anything I hoped for:
region=2 name=$(regionname $region)
This is how it looks in my actual code:
for region in {1..22} ; do ./plotstation.py -c /home/arne/sun-work/ct-tccon/ct-tccon-2015-5x7-use-obspack-no-tccon-nc/ -C "GA: in-situ ground and aircraft" -c /home/arne/sun-work/ct-tccon/ct-tccon-2015-5x7-use-obspack-use-tccon-noassimeu/ -C "TneGA: non-European TCCON and GA" -c /home/arne/sun-work/ct-tccon/ct-tccon-2015-5x7-use-obspack-no-tccon-no-aircraft-doesitbreaktoo/ -C "G: in-situ ground" --regionfluxtimeseries $region --toaverage 5 --exclude-validation --colorscheme paulforabp --linewidth 4 --font-size 36 --start 2009-12-03 --stop 2012-12-02 --title "Effect of assimilating non-EU TCCON, $(regionname ${region})" -o ~/flux-GA-vs-TneGA-vs-G-region-${region}.pdf; done
For your convenience, here’s my entire transcom naming function:
function regionname () { number="$1" case $number in 1) echo "NAM Boreal" ;; 2) echo "NAM Temperate";; 3) echo "South American tropical";; 4) echo "South American temperate";; 5) echo "Northern Africa";; 6) echo "Southern Africa";; 7) echo "Eurasian Boreal";; 8) echo "Eurasian Temperate";; 9) echo "Tropical Asia";; 10) echo "Australia";; 11) echo "Europe";; 12) echo "North Pacific Temperate";; 13) echo "West Pacific Tropics";; 14) echo "East Pacific Tropics";; 15) echo "South Pacific Temperate";; 16) echo "Northern Ocean";; 17) echo "North Atlantic Temperate";; 18) echo "Atlantic Tropics";; 19) echo "South Atlantic Temperate";; 20) echo "Southern Ocean";; 21) echo "Indian Tropical";; 22) echo "South Indian Temperate";; esac }
Happy Hacking!
After the last round of polishing, I decided to publish my theme under AGPLv3 [514]. Reason: If you use AGPL code and people access it over a network, you have to offer them the code. Which I hereby do ;)
That’s the only way to make sure that website code stays free.
It’s still for Drupal 5, because I didn’t get around to port it, and it has some ugly hacks, but it should be fully functional.
Just untar it in any Drupal [515] 5 install.
tar xjf weltenwald-theme-2010-08-05_r1.tar.bz2
Maybe I’ll get around to properly package it in the future…
Until then, feel free to do so yourself :)
And should I change the theme without posting a new layout here, just drop me a line and I’ll upload a new version — as required by AGPL. And should you have some problem, or if something should be missing, please drop me a line, too.
No screenshot, because a live version kicks a screenshot any day ;)
(in case it isn’t clear: Weltenwald is the theme I use on this site)
| Anhang | Größe |
|---|---|
| weltenwald-theme-2010-08-05_r1.tar.bz2 [516] | 877.74 KB |
My answer to the question about the best language on Quora [517]. If you continue reading from here, please stick with me to the end. Ready to read to the end? Enjoy the ride!
My current answer is: Scheme [25] ☺ It gives me a large degree of freedom to explore ways to program which were much harder hard to explore in Python, C++ and Java. That’s why I’m currently switching from Python to Scheme.1
But depending on my current step on the road to improve my skills2 and the development group and project, that answer might have been any other language — C, C++, Java, Python, Fortran, R, Ruby, Haskell, Go, Rust, Clojure, ….
Therefore this answer is as subjective as most other answers, because we have no context on your personal situation nor on the people with whom you’ll work and from whom you can learn or the requirements of the next project you want to tackle.
Put another way:
The only correct answer is “it depends”.
The other answers in this thread [518] should help you find the right answer for you.
Going from Python to Guile Scheme - a natural progression [154] ↩
Apprenticeship Patterns [519] — Guidance for the Aspiring Software Craftsman ↩
You might have read in some (almost ancient) papers, that a network like Gnutella can't scale. So I want to show you, why the current Version of Gnutella does scale, and does it well.
In earlier versions, up to v0.4, Gnutella was a a pure broadcast network. That means, that every search request did reach every participant, so the number of search requests hitting each node was for an optimal network exactly equal to the number of requests, made by nodes who were in the network. And you can see easily why that can't scale.
But that was only true for Gnutella 0.4.
In the current incarnation of Gnutella (Gnutella 0.6), Gnutella is no longer a pure Broadcast network. Instead, only the smallest percentage of the traffic is done via broadcast.
If you want to read about the methods used to realize this, please have a look at the GnuFU guide (english [520], german [521]).
Here I want to limit it to the statement, that the first two hops of a search request are governed via Dynamic Querying, which stops the request as soon as it has enough sources (this stops a search as soon as it gets about 250 results), and that the last two hops are governed via the Query Routing Protocol, which ensures, that a search request reaches only those hosts, which can actually have the file (which is only about 5% of the nodes).
So in todays reality, Gnutella is a quite structured and very flexible network.
To scale it, Ultrapeers can increase their number of connections from their current 32 upwards, which makes Dynamic Querying (DQ) and the Query Routing Protocol (QRP) even more effective.
In the case of DQ most queries for popular files will still provide enough results after the same number of clients have been contacted, so increasing the number of connections won't change the network traffic at all which is caused by the first two steps.
In the case of QRP, queries wil still only reach the hosts, which can have the file, and if Ultrapeers are connected to more nodes at the same time (by increasing the number of connections), it will provide more results for each connection, so DQ will stop even earlier than with fewer connections per Ultrapeer.
So Gnutella is now far from a broadcast model, and the act of increasing the size of the Gnutella Network can even increase its efficiency for popular files.
For rare files, QRP kicks in with full force, and even though DQ will likely check all other nodes for content, QRP will make sure that only those nodes are reached, which can have the content, which might be only 0.1% of the net or even far less.
Here, increasing the number of nodes per Ultrapeer means that nodes with rare files are in effect closer to you than before, so Gnutella also gets more efficient when you increase the network size, when rare file searches are your major concern.
So you can see, that Gnutella has become a network, which scales extremly well for keyword searches, and due to that it can also very efficiently be used to search for metadata and similar concepts.
The only thing which Gnutella can't do well are searches for strings which aren't seperate words (for example file-hashes), because that kills QRP, so they will likely not reach (m)any hosts. For these types of searches, the Gnutella developers work on a DHT (Distributed Hash Table), which will only be used, if the string can't be split into seperate words, and that DHT will most likely be Kademlia, which is also proven to work quite well.
And with that, the only problem which remains in need of fixing is spam, because that inhibits DQ when you do a rare search, but I am sure that the devs will also find a way to stop spamming, and even with spam, Gnutella is quite effective and consumes very little bandwidth, when you are acting as a leaf, and only moderate bandwidth when you are acting as ultrapeer.
Some figures as finishing touch:
Have fun with Gnutella!
- ArneBab 08:14, 15. Nov 2006 (CET)
PS: This guide ignores, that requests must travel through intermediate nodes. But since those nodes make up only about 3% of the network and only 3% of those nodes will be reached by a (QRP-routed) rare file request, it seems safe to ignore these 0.1% of the network in the calculations for the sake of making it easier to follow them mentally (QRP takes care of that).
At the Institute we use both Python 2 and Python 3. While researching the current differences (Python 3.5, compared to Python 2.7), I found two beautiful articles by Brett Cannon, the current manager of Python, and summarized them for my work group.
The articles:
The relevant points for us1 are the following:
Why Python 3 was necessary:
Why use 3 (relevant for us, e.G. for new projects):
The effect of these points is much larger than this short text suggests: avoid surprises, avoid awkward workarounds, and easier debugging.
I have summarized them because I can not expect scientists (or other people who only use Python) to read the full articles, just to decide what they do when they get the channce to tackle a new project. ↩
Example for print():
nums = [1, 2, 3]
with open("data.csv", "a") as f:
print(*nums, sep=";", file=f) ↩
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. — Brian Kernighan
In the article Hyperfocus and balance [524], Arc Riley from PySoy [525] talks about trying to get to the Hyperfocus state without endangering his health. Since I have similar needs, I am developing some strategies for that myself (though not for my health, but because my wife and children can’t be expected to let me work 8h without any interruptions in my free time).
Different from Arc, I try to change my programming habits instead of changing myself to fit to the requirements of my habits.1
Let’s begin with Programming while you feel great.
The guideline I learned from writing PnP roleplaying games [526] is to keep the number of things to know at 7 or less at each point (according to Miller, 1956 [527]; though the current best guess of the limitation for average humans is only 4 objects [528]!). For a function of code I would convert that as follows:
Only 4 things left for the code of your function. (three if you use both class attributes/global values and function arguments. Two, if you have complex custom data-structures with peculiar names or access-methods which you have to understand for doing anything. One if you also have to remember the commands of an unfamiliar2 editor or VCS tool. See how fast this approaches zero even when starting with 7 things?)
Add an if-switch, for-loop or similar and you have only 3 things left.
You need those for what the function should actually do, so better put further complexities into subfunctions.
Also ensure that each of the things you work with is easy enough. If you get the things you use down to 7 by writing functions with 20 arguments, you don’t win anything. Just the resources you could use in the function will blow your mind when you try to change the function a few months later. This goes for every part of your program: The number of functions, the number of function arguments, the number of variables, the lines of code per function and even the number of hierarchy levels you use to reduce the other things you need to keep in mind at any given time.
But if you want to be able to hack that code while you feel dumb (compared to those streaks of genius when you can actually hold the whole structure of your program in your head and forsee every effect of a given change before actually doing it), you need to make sure that you don’t have to take all 7 things into account.
Tune it down for the times when you feel dumb by starting with 5 things.3 After substracting one for the location, for the task and for the resources, you are left with only two things:
Two things for your function. Some Logic and calling stuff are 2 things.
If it is an if-switch, let it be just an if-switch calling other functions.4 Yes, it may feel much easier to do it directly here, when you are fully embedded in your code and feel great, but it will bite you when you are down. Which is exactly when you won’t want to be bitten by your own code.
Programming is a constant battle against complexity. Stumble from the sweet spot of your program into any direction, and complexity raises its ugly head. But finding the sweet spot requires constant vigilance, as it shifts with the size and structure of your program and your development group.
To find a practical way of achieving this, Django [529]’s concept of loose coupling and tight cohesion [530] (more detailed [531]) helped me most, because it reduces the interdependencies.
The effects of any given change should be contained in the part of the code you work in - and in one type of code.
As web framework, Django seperates the templates, the URI definitions, the program code and the database access from each other. (see how these are already 4 categories, hitting the limit of our mind again?)
For a game on the other hand, you might want to seperate story, game logic, presentation (what you see on the screen) and input/user actions. Also people who write a scenario or level should only have to work in one type of code, neatly confined in one file or a small set of files which reside in the same place.
And for a scientific program, data input, task definition, processing and data output might be separated.
Remember that this separation does not only mean that you put those parts of the code into different files, but that they are loosely coupled:5
They only use lean and clearly defined interfaces and don’t need to know much about each other.
This strategy does not only make your program easier to adapt (because the parts you need to change for implementing a given feature are smaller). If you apply it not only to the bigger structure, but to every part of the program, it’s main advantage is that any part of the code can be understood without having to understand other parts.
And you can still understand and hack your code, when your child is sick, your wife is overworked, you slept 3 hours the night before - and can only work for half an hour straight, because it’s evening and you don’t want to be a creep (but this change has to be finished nontheless).
Note that finding a design which accomplishes this is far more complex than it sounds. If people can read your code and say “oh, that’s easy. I can hack that” (and manage to do so), then you did it right.
Designing a simple structure to solve a complex task is far harder than designing a complex structure to solve that task.
And being able to hack your program while you feel dumb (and maybe even hold it in your head [532]) is worth investing some of your genius-time6 into your design (and repeating that whenever your code grows too hairy).
PS (7 years later): This only applies to the version of your code that stays in your codebase. During short-term experiments these rules do not apply, because there you still have the newly written code in your head. But take pains to clean it up before it takes on a life of its own. The last point for that is when you realize that you’re no longer sure how it works (then you know that you already missed the point of refactoring, but you can at least save your colleagues and your future self from stumbling even worse than you do at that moment). That way you also always have some leeway in short-term complexity that you can use during future experimentation. Also don’t make your code too simple: If you find that you’re bored while coding or that you spend more time fighting the structures you built than solving the actual problems, you took these principles too far, because you’re no longer getting full benefits from your brain. Well chosen local complexity reduces global complexity and the required work per change.
Where I got bitten badly by my high-performance coding habits is the keyboard layout evolution program [533]. I did not catch my error when the structure grew too complex (while adding stuff), and now that I do not have as much uninterrupted time as before, I cannot work on it efficiently anymore. I’m glad that this happened with a mostly finished project on whoose evolution no ones future depended. Still it is sad that this will keep me from turning it into a realtime visual layout optimizer. I can still work on its existing functionality (I kept improving it for the most importang task: the cost calculation), but adding new functionality is a huge pain. ↩
This limit only applies to unfamiliar things: things you did not yet learn well enough that they work automatically. Once you know a tool well enough that you don’t have to think about it anymore, it no longer counts against the 7 thing limit, since you don’t need to remember it.7 That’s strong support for writing conventional code — or at least code you’ll still write similarly a decade later — and using tools which can accompany you for a long time. ↩
See how I actually don’t get below 5 here? A good TODO list which shows you the task so you can forget it while coding might get you down to 4. But don’t bet on it. Not knowing where you are or where you want to go are recipes for desaster… And if you make your functions too small, the collection of functions gets more complex, or the object hierarchy too deep, adding complexity at other places and making it harder to change the structure (refactor) when requirements change. Well, no one said creating well-structured programs would be easy. You need to find the right compromise for you. ↩
Keeping functions simple does not mean that they must be extremely short. If you have a library which provides many tools that get used for things like labelling axes in a plot, and you don’t get much repetition between different functions, then having a function of 20 to 30 lines can be simpler than building an abstraction which only works at the current state of the code but will likely break when you add the next function. This is inherent, function-local complexity: you cannot reduce it with structure. Therefore the sweet spot of simplicity for some tasks is using medium-sized functions. If you find yourself repeating exactly the same code multiple times, however, you likely missed the sweet spot and should investigate shortening the functions by extracting the common tasks, or restructuring the function to separate semantically different tasks. ↩
In all your structures, do keep program performance in mind. If your structure imposes high performance penalties, you will have to break it more and more as you push it beyond the limits you deemed reasonable at the beginning. And then it adds complexity instead of reducing it. When programming, you always have two audiences. One are humans: your program must be easy to understand and change. If it is not, it will rot. The other is the machine: your program must be sufficiently efficient to execute. If it is not, that will bite you when you push it where it was never meant to go. And you will. If it grows somewhat successful and you get any competition, even if it is much worse, you cannot afford a rewrite. The full rewrite is the number one strategic mistake you should never make [534]. So while you keep one eye on easy structures for humans, keep the other eye on performance for the machine. ↩
How to find your genius time? That’s a tautology: Your genius time is when you can hold your program in your mind. If I could tell you when your genius time occurs, or even how to trigger it, I could make lots of money by consulting about every tech company in existence. A good starting point is reading about “flow”, known in many other creative activities (some [535] starting [536] points [537]). Reaching the flow often includes spending time outside the flow, so best write programs you can still hack when you feel dumb.8 ↩
This is reasoning from experience. I think the actual reason why people can juggle large familiar structures is more likely that they have an established mental model which allows them to use multiple dimensions and cut the amount of bits you need for referring to the thing.9 See the Absolute Judgments of Multidimensional Stimuli section, the recoding section and the difference between chunks and bits in George A. Miller (1956) [527]. This is part of writing programs you can still hack when you feel dumb — but one which only helps those who use the same structures and one which binds you to your established coding style. ↩
And in all this reduction of local complexity, keep in mind that there is no silver bullet (Brooks, 1986) [538]. Just take care that you design your code against the limits of the humans who work with it, and only in the second place against the limits of the tools you use — you can change the tools, but you cannot easily change the humans; often you cannot change the humans at all. In the best case you can make your tools fit and expand the limits of humans. But remember also that your code must run well enough on the machine. And you often do not know what "well enough" means. I know that this is not a simple answer. If that irks you, keep in mind that there is no silver bullet (Brooks, 1986) [538], and this text isn’t one either. It’s just a step on the way — I hope it is useful to you. ↩
Aside from being able to remember the full mental model, it is often enough to remember something close enough and then find the correct answer with assisted guessing. A typical example is narrowing down auto-completion candidates by matching on likely names until something feels right. This is how good auto-completion — or rather: guided interactive code inspection — massively expands the size of models we can work with efficiently. It depends on easily guessable naming, typically aided by experience, and it benefits from tools which can limit or order the potential candidates by the context. With good tool-support it suffices to have a general feeling about the direction to take for doing something. The guidelines in this article should help you with guessing, and should help your tool with limiting candidates to plausible choices and with ordering them by context. ↩
Here I want to show you how to write a commandline tool in Fortran. Because Fortran is much better than its reputation — most of all in syntax. I needed a long time to understand that — to get over my predjudices — and I hope I can help you save some of that time.1
This provides a quick-start into Fortran. After finishing it, I suggest having a look at Fortran surprises [310] to avoid stumbling over differences between Fortran and many other languages.
Code to be executed when the program runs is enclosed in program and end program:
program hello use iso_fortran_env write (output_unit,*) "Hello World!" write (output_unit,*) 'Hello Single Quote!' end program hello
Call this fortran-hello.f90 (.f is for the old Fortran 77).
The fastest free compiler is gfortran [545].
gfortran -std=gnu -O3 fortran-hello.f90 -o fortran-hello ./fortran-hello
Hello World! Hello Single Quote!
That’s it. This is your first commandline tool.
Most commandline tools accept arguments. Fortran-developers long resisted this and preferred explicit configuration files, but with 2003 argument parsing entered the standard. The tool for this is get_command_argument.
program cli implicit none ! no implicit declaration: all variables must be declared character(1000) :: arg call get_command_argument(1, arg) ! result is stored in arg, see ! https://gcc.gnu.org/onlinedocs/gfortran/GET_005fCOMMAND_005fARGUMENT.html if (len_trim(arg) == 0) then ! no argument given write (*,*) "Call me --world!" else if (trim(arg) == "--world") then call get_command_argument(2, arg) if (len_trim(arg) == 0) then arg = "again!" end if write (*,*) "Hello ", trim(arg) ! trim reduces the fixed-size array to non-blank letters end if end if end program
gfortran -std=gnu -O3 fortran-commandline.f90 -o fortran-helloworld ./fortran-helloworld ./fortran-helloworld --world World ./fortran-helloworld --world
Call me --world! Hello World Hello again!
The following restructures the program into modules. If you used any OO tool, you know what this does. use X, only : a, b, c gets a, b and c from module x.
Note that you have to declare all variables used in the function at the top of the function.
module hello implicit none character(100),parameter :: prefix = "Hello" ! parameters are constants public :: parse_args, prefix contains function parse_args() result ( res ) implicit none character(1000) :: res call get_command_argument(1, res) if (trim(res) == "--world") then call get_command_argument(2, res) if (len_trim(res) == 0) then res = "again!" end if end if end function parse_args end module hello program helloworld use hello, only : parse_args, prefix implicit none character(1000) :: world world = parse_args() write (*,*) trim(prefix), " ", trim(world) end program helloworld
gfortran -std=gnu -O3 fortran-modules.f90 -o fortran-modules ./fortran-modules --world World
Hello World
You can also declare functions as pure (free from side effects). I did not yet check whether the compiler enforces that already, but if it does not do it now, you can be sure that this will be added. Fortran compilers are pretty good at enforcing what you tell them. Do see the fortran surprises [310] for a few hints on how to tell them what you want.
Fortran is fast, really fast. But if you come from C, you need to retrain a bit: The inner loop is the first part of the reference, while with C it is the last part.
The following tests the speed difference when looping over the outer or the inner part. You can get a factor 3-5 difference by having the tight inner loop go over the inner part of the multidimensional array.
Note the L1 cache comments: If you want to get really fast with any language, you cannot ignore the capabilities of your hardware.
Also note that this code works completely naturally on multidimensional arrays.
! Thanks to http://infohost.nmt.edu/tcc/help/lang/fortran/time.html program cheaplooptest integer :: i,j,k,s integer, parameter :: n=150 ! 50 breaks 32KB L1 cache, 150 breaks 256KB L2 cache integer,dimension(n,n,n) :: x, y real etime real elapsed(2) real total1, total2, total3, total4 y(:,:,:) = 0 x(:,:,:) = 1 total1 = etime(elapsed) print *, "start time ", total1 ! first index as outer loop do s=1,n do i=1,n do j=1,n y(i,j,:) = y(i,j,:) + x(i,j,:) end do end do end do total2 = etime(elapsed) print *, "time for outer loop", total2 - total1 ! first index as inner loop is much cheaper (difference depends on n) do s=1,n do k=1,n do j=1,n y(:,j,k) = y(:,j,k) + x(:,j,k) end do end do end do total3 = etime(elapsed) print *, "time for inner loop", total3-total2 ! plain copy is slightly faster still do s=1,n y = y + x end do total4 = etime(elapsed) print *, "time for simple loop", total4-total3 end program cheaplooptest
gfortran -std=gnu -O3 fortran-faster.f90 -o fortran-faster ./fortran-faster
start time 2.33319998E-02 time for outer loop 19.0533314 time for inner loop 0.799999237 time for simple loop 0.729999542
This now seriously looks like Python, but faster by factor 5 to 20, if you do it right (avoid the outer loop).
Just to make it completely clear: The following is how the final test code looks (without the additional looping which make it slow enough to time it).
program cleanloop integer, parameter :: n=150 ! 50 breaks 32KB L1 cache, 150 breaks 256KB L2 cache integer,dimension(n,n,n) :: x, y y(:,:,:) = 0 x(:,:,:) = 1 y = y + x end program cleanloop
That’s it. If you want to work with any multidimensional stuff like matrices, that’s in most cases exactly what you want. And fast.
The previous tools were partial solutions. The following is a complete solution, including numerical work (which is where Fortran really shines). And setting the numerical precision. I’m sharing it in total, so you can see everything I needed to do to get it working well.
This implements newbase60 by tantek [26].
It could be even nicer, if I could find an elegant way to add complex numbers to the task :)
module base60conv implicit none ! if you use this here, the module must come before the program in gfortran ! constants: marked as parameter: not function parameters, but ! algorithm parameters! character(len=61), parameter :: base60chars = "0123456789"& //"ABCDEFGHJKLMNPQRSTUVWXYZ_abcdefghijkmnopqrstuvwxyz" integer, parameter :: longlong = selected_int_kind(32) ! length up to 32 in base10, int(16) integer(longlong), parameter :: sixty = 60 public :: base60chars, numtosxg, sxgtonum, longlong private ! rest is private contains function numtosxg( number ) result ( res ) implicit none !!! preparation ! input: ensure that this is purely used as input. ! intent is only useful for function arguments. integer(longlong), intent(in) :: number ! work variables integer(longlong) :: n integer(longlong) :: remainder ! result character(len=1000) :: res ! do not initialize variables when ! declaring them: That only initializes ! at compile time not at every function ! call and thus invites nasty errors ! which are hard to find. actual ! algorithm if (number == 0) then res = "0" return end if ! calculate the base60 string res = "" ! I have to explicitely set res to "", otherwise it ! accumulates the prior results! n = number ! the input argument: that should be safe to use. ! catch number = 0 do while(n > 0) ! in the first loop, remainder is initialized here. remainder = mod(n, sixty) n = n/sixty ! note that fortran indizes start at 1, not at 0. res = base60chars(remainder+1:remainder+1)//trim(res) ! write(*,*) number, remainder, n end do ! numtosxg = res end function numtosxg function sxgtonum( base60string ) result ( number ) implicit none ! Turn a base60 string into the equivalent integer (number) character(len=*), intent(in) :: base60string integer :: i ! running index integer :: idx, badchar ! found index of char in string integer(longlong) :: number ! integer,dimension(len_trim(base60string)) :: numbers ! for later openmp badchar = verify(base60string, base60chars) if (badchar /= 0) then ! one not write(*,"(a,i0,a,a)") "# bad char at position ", badchar, ": ", base60string(badchar:badchar) stop 1 ! with OS-dependent error code 1 end if number = 0 do i=1, len_trim(base60string) number = number * 60 idx = index(base60chars, base60string(i:i), .FALSE.) ! not backwards number = number + (idx-1) end do ! sxgtonum = number end function sxgtonum end module base60conv program base60 ! first step: Base60 encode. ! reference: http://faruk.akgul.org/blog/tantek-celiks-newbase60-in-python-and-java/ ! 5000 should be 1PL use base60conv implicit none integer(longlong) :: tests(14) = (/ 5000, 0, 100000, 1, 2, 60, & 61, 59, 5, 100000000, 256, 65536, 215000, 16777216 /) integer :: i, badchar ! index for the for loop integer(longlong) :: n ! the current test to run integer(longlong) :: number ! program arguments character(1000) :: arg call get_command_argument(1, arg) ! modern fortran 2003! if (len_trim(arg) == 0) then ! run tests ! I have to declare the return type of the function in the main program, too. ! character(len=1000) :: numtosxg ! integer :: sxgtonum ! test the functions. do i=1,size(tests) n = tests(i) write(*,"(i12,a,a,i12)") n, " ", trim(numtosxg(n)), sxgtonum(trim(numtosxg(n))) end do else if (trim(arg) == "-r") then call get_command_argument(2, arg) badchar = verify(arg, " 0123456789") if (badchar /= 0) then write(*,"(a,i0,a,a)") "# bad char at position ", badchar, ": ", arg(badchar:badchar) stop 1 ! with OS-dependent error code 1 end if read (arg, *) number ! read from arg, write to number write (*,*) trim(numtosxg(number)) else write (*,*) sxgtonum(arg) end if end if end program base60
gfortran -std=gnu -O3 fortran-base60.f90 -o fortran-base60 ./fortran-base60 P ./fortran-base60 h ./fortran-base60 D ./fortran-base60 PhD factor $(./fortran-base60 PhD) # yes, it’s prime! :) ./fortran-base60 -r 85333 ./fortran-base60 "!" || echo $? echo "^ with error code on invalid input :)"
23 42 13 85333 85333: 85333 PhD # bad char at position 1: ! 1 ^ with error code on invalid input :)
Fortran done right looks pretty clean. It does have its warts, but not more than all the other languages which are stable enough that the program you write today will still run in 10 years to come. And it is fast. And free.
Why I’m writing this? To save you a few years of lost time I spent adjusting my mistaken distaste for a pretty nice language which got a bad reputation because it once was the language everyone had to learn to get anything done (with sufficient performance). And its code did once look pretty bad, but that’s long become ancient history — except for the tools which were so unbelievably good that they are still in use 40 years later.
You can ask "what makes a programming language cool?". One easily overlooked point is: Making your programs still run three decades later. That doesn’t look fancy and it doesn’t look modern, but it brings a lot of value.
And if you use it where it is strong, Fortran is almost as easy to write as Python, but a lot faster (in terms of CPU requirement for the whole task) with much lower resource consumption (in terms of memory usage and startup time). Should you now ask "what about multiprocessing?", then have a look at OpenMP [546].
After I finished my Diploma, I thought of Fortran as "this horribly unreadable 70th language". I thought it should be removed and that it only lived on due to pure inertia. I thought that its only deeper use were to provide the libraries to make numeric Python faster. Then I actually had to use it. In the beginning I mocked it and didn’t understand why anyone would choose Fortran over C. What I saw was mostly Fortran 77. The first thing I wrote was "Fortran surprises [310]" — all the strange things you can stumble over. But bit by bit I realized the similarities with Python. That well-written Fortran actually did not look that different from Python — and much cleaner than C. That it gets stuff done. This year Fortran turns 60 (heise reported in German [547]). And I understand why it is still used. And thanks to being an ISO standard it is likely that it will stick with us and keep working for many more decades. ↩
| Anhang | Größe |
|---|---|
| 2017-04-10-Mo-fortran-commandline-tool.pdf [548] | 172.84 KB |
| 2017-04-10-Mo-fortran-commandline-tool.org [549] | 14.01 KB |
Update: The basic bug shown here is now fixed in Firefox [550]. Read on to see whether the fix works for you. Keep in mind that there are much stronger attacks than the one shown here. Use private mode to reduce the amount of data your Browser keeps. What’s not there cannot be claimed.
After the example of making-the-web, I was quite intrigued by the ease of sniffing the history via simple CSS tricks.
So I decided to test, how small I get a Python program which can sniff the history via CSS - without requiring any scripting ability on the browser-side.
I first produced fully commented code (see server.py [552]) and then stripped it down to just 64 lines (server-stripped.py [553]), to make it really crystal clear, that making your browser vulnerable to this exploit is a damn bad idea. I hope this will help get Firefox fixed quickly.
If you see http://blubber.blau as found, you're safe. If you don't see any links as found, you're likely to be safe. In any other case, everyone in the web can grab your history - if given enough time (a few minutes) or enough iframes (which check your history in parallel). This doesn't use Javascript.
It currently only checks for the 1000 or so most visited websites and doesn't keep any logs in files (all info is in memory and wiped on every restart), since I don't really want to create a full fledged history ripper but rather show how easy it would be to create one.
Besides: It does not need to be run in an iframe. Any Python-powered site could just run this test as regular part of the site while you browse it (and wonder why your browser has so much to do for a simple site, but since we’re already used to high load due to Javascript, who is going to care?). So don’t feel safe, just because there are no iframes. To feel and be safe, use one of the solutions from What the Internet knows about you [554].
Konqueror seems to be immune: It also (pre-)loads the "visited"-images from not visited links, so every page is seen as visited - which is the only way to avoid spreading my history around on the web and still providing “visited” image-hints in the browser!
Firefox 4.0.1 seems to be immune, too: It does not show any :visited-images, so the server does not get any requests.
So please don't let your browser load anything depending on the :visited state of a link tag! It shouldn't load anything based on internal information, because that always publicizes private information - and you don't know who will read it!
In short: Don't keep repeating Ennesbys Mistake:
Mistake:  [555]
[555]
Effects:  [556]
[556]
(comic strips not hosted here and not free licensed → copyright: Howard V. Tayler [557])
And to the Firefox developers: Please remove the optimization of only loading required css data based on the visited info! I already said so in a bug report, and since the bug isn't fixed, this is my way to put a bit of weight behind it. Please stop putting your users privacy at risk.
Usage:
To get more info, just use ./server.py --help.
Since the URL in a bibtex [558] entry is typically just duplicate information when the entry has a DOI, I want to hide it.1
Here’s how:
diff -r 5b78f551d0a0 plainnatnoturl.bst --- a/plainnatnoturl.bst Tue Apr 04 10:45:08 2017 +0200 +++ b/plainnatnoturl.bst Tue Apr 04 10:52:25 2017 +0200 @@ -1,5 +1,7 @@ -%% File: `plainnat.bst' -%% A modification of `plain.bst' for use with natbib package +%% File: `plainnatnoturl.bst' +%% A modification of `plain.bst' and `plainnat.bst' for use with natbib package +%% +%% From /usr/share/texmf-dist/bibtex/bst/natbib/plainnat.bst %% %% Copyright 1993-2007 Patrick W Daly %% Max-Planck-Institut f\"ur Sonnensystemforschung @@ -285,7 +288,11 @@ FUNCTION {format.url} { url empty$ { "" } - { new.block "URL \url{" url * "}" * } + { doi empty$ + { new.block "URL \url{" url * "}" * } + { "" } + if$ + } if$ }
Just put this next to your .tex file, add a header linking the doi
\newcommand*{\doi}[1]{\href{http://dx.doi.org/#1}{doi: #1}}
and use the bibliography referencing plainnatnoturl.bst
\bibliographystyle{plainnatnoturl} \bibliography{YOURBIBFILE}
That’s it. Thanks to toliveira [559] from tex.stackexchange!
Also I’m scraping at my page limit and cutting a line for roughly every second entry helps a lot :)
Today a bug in complex number handling surfaced in guile [25] which only appeared on OSX.
This is a short note just to make sure that the bug is reported somewhere.
Test-code (written mostly by Mark Weaver who also analyzed the bug - I only ran the code on a few platforms I happened to have access to):
// test.c // compile with gcc -O0 -o test test.c -lm // or with icc -O0 -o test test.c -lm #include <complex.h> #include <stdio.h> int main (int argc, char **argv) { double complex z = conj (1.0); double complex result; if (argc == 1) z = conj (0.0); result = cexp (z); printf ("cexp (%f + %f i) => %f + %f i\n", creal (z), cimag (z), creal (result), cimag (result)); result = conj(result); printf ("conj(cexp (%f + %f i)) => %f + %f i\n", creal (z), cimag (z), creal (result), cimag (result)); return 0; }
As by the C-11 standard [560] (pages 561 and 216) this should return:
cexp (0.000000 + -0.000000 i) => 1.000000 + -0.000000 i
conj(cexp (0.000000 + -0.000000 i)) => 1.000000 + 0.000000 i
Page 561:
— cexp(conj(z)) = conj(cexp(z)).
Page 216:
The conj functions compute the complex conjugate of z, by reversing the sign of its imaginary part.
On OSX it returns (compiled with GCC):
TODO: Check the second line!
cexp (0.000000 + -0.000000 i) => 1.000000 + 0.000000 i
With the intel compiler it returns:
cexp (0.000000 + 0.000000 i) => 1.000000 + 0.000000 i
conj(cexp (0.000000 + 0.000000 i)) => 1.000000 + 0.000000 i
In short: On OSX cexp seems broken. With the intel compiler conj seems broken.
icc --version # => icc (ICC) 13.1.3 20130607 # => Copyright (C) 1985-2013 Intel Corporation. All rights reserved.
The OSX compiler is GCC 4.8.2 from MacPorts.
[taylanub] ArneBab: You might want to add that compiler optimizations can result in cexp() calls where there are none (which is how this bug surfaced in our case).
[mark_weaver] cexp(z) = e^z = e^(a+bi) = e^a * e^(bi) = e^a * (cos(b) + i*sin(b))
[mark_weaver] for real 'b', e^(bi) is a point on the unit circle on the complex plane.
[mark_weaver] so cexp(bi) can be used to compute cos(b) and sin(b) simultaneously, and probably faster than calling 'sin' and 'cos' separately.
Over the years I found a few things which in my opinion are essential for any Python script:
Everything in this setup is low-overhead and available from Python 2.6 to 3.x, so you can use it to start any kind of project.
# encoding: utf-8 """Minimal setup for a Python script. No project should start without this. """ import argparse # for Python <2.6 use optparse # setup sane logging. It tells you why, where and when something was # logged, so you can jump to the source line right away. import logging logging.basicConfig(level=logging.WARNING, format=' [%(levelname)-7s] (%(asctime)s) %(filename)s::%(lineno)d %(message)s', datefmt='%Y-%m-%d %H:%M:%S') def main(): """The main entry point.""" pass # output test results as base60 number (for aesthetics) def numtosxg(n): CHARACTERS = ('0123456789' 'ABCDEFGHJKLMNPQRSTUVWXYZ' '_' 'abcdefghijkmnopqrstuvwxyz') s = '' if not isinstance(n, int) or n == 0: return '0' while n > 0: n, i = divmod(n, 60) s = CHARACTERS[i] + s return s def _test(): """ run doctests, can include setup. Complex example: >>> import sys >>> handlers = logging.getLogger().handlers # to stdout >>> logging.getLogger().handlers = [] >>> logging.getLogger().addHandler( ... logging.StreamHandler(stream=sys.stdout)) >>> logging.warn("test logging") test logging >>> logging.getLogger().handlers = handlers """ from doctest import testmod tests = testmod() if not tests.failed: return "^_^ ({})".format(numtosxg(tests.attempted)) else: return ":( "*tests.failed # keep argument setup and parsing together parser = argparse.ArgumentParser(description=__doc__.splitlines()[0]) parser.add_argument("arguments", metavar="args", nargs="*", help="Commmandline arguments") parser.add_argument("--debug", action="store_true", help="Set log level to debug") parser.add_argument("--info", action="store_true", help="Set log level to info") parser.add_argument("--quiet", action="store_true", help="Set log level to error") parser.add_argument("--test", action="store_true", help="Run tests") # add a commandline switch to increase the log-level when running this # script standalone. --test should run the tests. if __name__ == "__main__": args = parser.parse_args() if args.debug: logging.getLogger().setLevel(logging.DEBUG) elif args.info: logging.getLogger().setLevel(logging.INFO) elif args.quiet: logging.getLogger().setLevel(logging.ERROR) if args.test: print(_test()) else: main()
Arrrrrr! Ye be replacin' th' walk th' plank alt-tab wi' th' keelhaulin' pirate wheel, matey! — Lacrocivious
pyRad is a wheel type command interface for KDE [208]1, designed to appear below your mouse pointer at a gesture.
install | setup | usage and screenshots | download and sources

easy_install pyRadKDE in any shell.pyrad.py. Visual icon selection requires the kdialog program (a standard part of KDE).
For a "live" version, just clone the pyrad Mercurial repo [563] and let KDE run "path/to/repo/pyrad.py" at startup. You can stop a running pyrad via pyrad.py --quit. pyrad.py --help gives usage instructions.
emerge -a kde-misc/pyrad/usr/bin/pyrad.py. Then add it as script to your autostart (systemsettings→advanced→autostart). You can now use Alt-F6 and Meta-F6 to call it. Add the mouse gesture in systemsettings (systemsettings→shortcuts) to call D-Bus: Program: org.kde.pyRad ; Object: /MainApplication ; Function: newInstance (you might have to enable gestures in the settings, too - in the shortcuts-window you should find a settings button).
Alternately set the gesture to call the command dbus-send --type=method_call --dest=org.kde.pyRad /MainApplication org.kde.KUniqueApplication.newInstance.
Customize the menu by editing the file "$HOME/.pyradrc" or middle-clicking (add) and right-clicking (edit) items.
To call pyRad and see the command wheel, you simply use the gesture or key you assigned.
Then you can activate an action with a single left click. Actions can be grouped into folders. To open a folder, you also simply left-click it.
Also you can click the keyboard key shown at the beginning of the tooltip to activate an action (hover the mouse over an icon to see the tooltip).
To make the wheel disappear or leave a folder, click the center or hit the key 0. To just make it disappear, hit escape.
For editing an action, just right click it, and you’ll see the edit dialog.

Each item has an icon (either an icon name from KDE or the path to an icon) and an action. The action is simply the command you would call in the shell (only simple commands, though, no real shell scripting or glob).
To add a new action, simply middle-click the action before it. The wheel goes clockwise, with the first item being at the bottom. To add a new first item, middle-click the center.
To add a new folder (or turn an item into a folder), simply click on the folder button, say OK and then click it to add actions in there.
See it in action:
 [565]
[565]
pyRad is available from
PS: The name is a play on ‘python’, ‘Rad’ (german for wheel) and pirate :-)
PPS: KDE, K Desktop Environment and the KDE Logo are trademarks of KDE e.V.
PPPS: License is GPL+ [430] as with almost everything on this site.Arrrrrr! Ye be replacin' th' walk th' plank alt-tab wi' th' keelhaulin' pirate wheel, matey! Arrrrr! → http://draketo.de/light/english/pyrad
 [208] ↩
[208] ↩
| Anhang | Größe |
|---|---|
| pyrad-0.4.3-screenshot.png [568] | 26.67 KB |
| pyrad-0.4.3-screenshot-edit-action.png [569] | 36.28 KB |
| pyrad-0.4.3-screenshot-edit-folder.png [570] | 39.18 KB |
| pyrad-0.4.3-screenshot2.png [571] | 29.03 KB |
| pyrad-0.4.3-screenshot3.png [572] | 27.59 KB |
| powered_by_kde_horizontal_190.png [573] | 11.96 KB |
| pyrad-0.4.3-fullscreen.png [565] | 913.3 KB |
| pyrad-0.4.3-fullscreen-400x320.png [574] | 143.69 KB |
| pyrad-0.4.4-screenshot-edit-action.png [575] | 40.94 KB |
My wheel type command interface pyRad [432] just got included [576] in the official Gentoo [279] portage-tree [577]!
So now you can install it in Gentoo with a simple emerge kde-misc/pyrad.
[432]
Many thanks go to the maintainer Andreas K. Hüttel (dilfridge) and to jokey and Tommy[D] from the Gentoo sunrise [578] project (wiki [579]) for providing their user-overlay and helping users with creating ebuilds as well as Arfrever, neurogeek, floppym from the Gentoo Python-Herd [580] for helping me to clean up the ebuild and convert it to EAPI 3!
These are the notes to a short tutorial I gave to my working group as part of our groundwork group meetings. Some parts here require GNU Bash [581].
echo "foobar"
echo foobar
echo echo # second echo not executed but printed!
echo foobar | xargs echo # same output as echo foobar
echo foo > test.txt # pipe into file, replacing the content echo bar >> test.txt # append to file # warning: cat test.txt > test.txt # defined as generating an empty file!
echo foobar | sed s/foo.*/foo/ | xargs echo # same output as echo foo
echo foo | grep bar # empty echo foobar | grep oba # foobar, oba higlighted
foo=1 # no spaces around the equal sign! echo ${foo} # "$foo" == "1", "$foobar" == "", "${foo}bar" == "1bar"
echo $(echo foobar) # equivalent to echo foobar | xargs echo
for i in a b c; do echo $i done # ; can replace a linebreak for i in a b c; do echo $i; done
for i in {1..5}; do # 1 2 3 4 5 echo $i done
while true; do break; done # break: stop # continue: start the loop again
foo=1 echo "${foo}" # 1 echo '${foo}' # ${foo} <- literal string for i in "a b c"; do # quoted: one argument echo ${i}; done # => a b c for i in a b c; do # unquoted: whitespace is separator! echo ${i}; done # a # b # c
# string equality a="foo" b="bar" if [[ x"${a}" == x"${b}" ]] ; then echo a else echo b fi
# other tests if test -z ""; then echo empty fi if [ -z "" ]; then echo same check fi if [ ! -z "not empty" ]; then echo inverse check fi if test ! -z "not empty"; then echo inverse check with test fi if test 5 -ge 2; then echo 5 is greater or equal 2 fi
also check test 1 -eq 1, and info test.
#!/usr/bin/env bash echo "Hello World"
chmod +x hello.sh ./hello.sh
echo 1 echo $? # 0: success grep 1 /dev/null # fails echo $? # 1: failure exit 0 # exit a script with success value (no further processing of the script) exit 1 # exit with failure (anything but 0 is a failure)
# info about this script version="shell option parsing example 0.1" # check for the kind of getopt getopt -T > /dev/null if [ $? -eq 4 ]; then # GNU enhanced getopt is available eval set -- `getopt --name $(basename $0) --long help,verbose,version,output: --options hvo: -- "$@"` else # Original getopt is available eval set -- `getopt hvo: "$@"` fi # # actually parse the options # PROGNAME=`basename $0` # ARGS=`getopt --name "$PROGNAME" --long help,verbose,version,output: --options hvo: -- "$@"` # if [ $? -ne 0 ]; then # exit 1 # fi # eval set -- $ARGS # default options HELP=no verbose=no VERSION=no OUTPUT=no # check, if the default wisp exists and can be executed. If not, fall # back to wisp.py (which might be in PATH). if [ ! -x $WISP ]; then WISP="wisp.py" fi while [ $# -gt 0 ]; do case "$1" in -h | --help) HELP=yes;; -o | --output) OUTPUT="$2"; shift;; -v | --verbose) VERBOSE=yes;; --version) VERSION=yes;; --) shift; break;; esac shift done # all other arguments stay in $@ <<using-options>>
# Provide help output if [[ $HELP == "yes" ]]; then echo "$0 [-h] [-v] [-o FILE] [- | filename] Show commandline option parsing. -h | --help) This help output. -o | --output) Save the executed wisp code to this file. -v | --verbose) Provide verbose output. --version) Print the version string of this script. " exit 0 fi if [[ x"$VERSION" == x"yes" ]]; then echo "$version" exit 0 # script ends here fi if [[ ! x"$OUTPUT" == x"no" ]]; then echo writing to $OUTPUT fi # just output all other arguments if [ $# -gt 0 ]; then echo $@ fi
prog [OPTIONAL_FLAG] [OPTIONAL_ARGUMENT VALUE] REQUIRED_ARGUMENT... # ... means that you can specify something multiple times # short and long options prog [-h | --help] [-v | --verbose] [--version] [-f FILE | --file FILE] # concatenated short options hg help [-ec] [THEMA] # hg help -e -c == -ec
prog --help # provide help output. Often also -h prog --version # version of the program. Often also -v prog --verbose # often to give more detailed information. Also --debug
By convention and the minimal GNU standards
echo 1 ; echo 2 ; echo 3 # sequential echo 1 & echo 2 & echo 3 # backgrounding: possibly parallel grep foo test.txt && echo foo is in test.txt # conditional: Only if grep is successful grep foo test.txt || echo foo is not in test.txt # conditional: on failure
echo $((1+2)) # 3 a=2 b=3 echo $((a*b)) # 6 echo $((a**$(echo 3))) # 8
man [command]
info [topic] info [topic subtopic] # emacs: C-h i
more convenient info:
function i() { if [[ "$1" == "info" ]]; then info --usage -f info-stnd else # check for usage from fast info, if that fails check man and if that also fails, just get the regular info page. info --usage -f "$@" 2>/dev/null || man "$@" || info "$@" fi }
I needed to convert a huge batch of mediawiki-files to html (had a 2010-03 copy of the now dead limewire wiki lying around). With a tip from RoanKattouw in #mediawiki@freenode.net I created a simple python script [582] to convert arbitrary files from mediawiki syntax to html.
Usage:
This script is neither written for speed or anything (do you know how slow a webrequest is, compared to even horribly inefficient code? …): The only optimization is for programming convenience — the advantage of that is that it’s just 47 lines of code :)
It also isn’t perfect: it breaks at some pages (and informs you about that).
It requires yaml [583] and Python 3.x [94].
#!/usr/bin/env python3
"""Simply turn all input files to html.
No errorchecking, so keep backups.
It uses the mediawiki webapi,
so you need to be online.
Copyright: 2010 © Arne Babenhauserheide
License: You can use this under the GPLv3 or later,
if you add the appropriate license files
→ http://gnu.org/licenses/gpl.html
"""
from urllib.request import urlopen
from urllib.parse import quote
from urllib.error import HTTPError, URLError
from time import sleep
from random import random
from yaml import load
from sys import argv
mediawiki_files = argv[1:]
def wikitext_to_html(text):
"""parse text in mediawiki markup to html."""
url = "http://en.wikipedia.org/w/api.php?action=parse&format=yaml&text=" + quote(text, safe="") + " "
f = urlopen(url)
y = f.read()
f.close()
text = load(y)["parse"]["text"]["*"]
return text
for mf in mediawiki_files:
with open(mf) as f:
text = f.read()
HTML_HEADER = "<html><head><title>" + mf + "</title></head><body>"
HTML_FOOTER = "</body></html>"
try:
text = wikitext_to_html(text)
with open(mf, "w") as f:
f.write(HTML_HEADER)
f.write(text)
f.write(HTML_FOOTER)
except HTTPError:
print("Error converting file", mf)
except URLError:
print("Server doesn’t like us :(", mf)
sleep(10*random())
# add a random wait, so the api server doesn’t kick us
sleep(3*random())
| Anhang | Größe |
|---|---|
| parse_wikipedia_files_to_html.py.txt [582] | 1.47 KB |
Links:
[1] http://www.gnu.org/philosophy/free-sw.html
[2] https://www.draketo.de/english/politics
[3] https://www.draketo.de/english/emacs
[4] https://www.draketo.de/english/freenet
[5] https://www.draketo.de/english/mercurial
[6] https://www.draketo.de/licht/freie-software
[7] https://www.draketo.de/software/wisp
[8] http://www.draketo.de/proj/wisp/why-wisp.html
[9] https://hg.sr.ht/~arnebab/wisp
[10] https://gnu.org/s/guix
[11] https://aur.archlinux.org/packages/guile-wisp-hg
[12] https://hg.sr.ht/~arnebab/wisp/browse/examples
[13] https://hg.sr.ht/~arnebab/wisp/browse/tests
[14] https://twitter.com/dustyweb/status/646788662361849856
[15] https://identi.ca/cwebber/note/qG9yHAqJTseD_YLSDsUbjg
[16] http://dustycloud.org/blog/wisp-lisp-alternative/
[17] https://fosdem.org/2019/schedule/event/guixinfra/
[18] https://hg.sr.ht/~arnebab/wisp/browse/examples/with.w?rev=3447d48e85620c639131c0e1b47308503df5eb81#L15
[19] https://www.draketo.de/files/wisp-1.0.3.tar_.gz
[20] https://hg.sr.ht/~arnebab/wispserve
[21] https://hg.sr.ht/~arnebab/conf
[22] https://archive.fosdem.org/2017/schedule/event/naturalscriptwritingguile/
[23] https://hg.sr.ht/~arnebab/wisp/browse/examples/doctests.w?rev=ba80bf370de0#L7
[24] https://hg.sr.ht/~arnebab/wisp/browse/NEWS
[25] http://gnu.org/s/guile
[26] http://ttk.me/w/NewBase60
[27] https://webchat.freenode.net/?randomnick=1&channels=%23guile&uio=d4
[28] https://www.draketo.de/english/wisp#sec-2
[29] https://marmalade-repo.org/packages/wisp-mode
[30] http://sph.mn/computer/guides/c.html
[31] http://sph.mn/computer/guides/c/c-indent.html
[32] https://github.com/sph-mn/sph-sc
[33] https://www.draketo.de/proj/wisp/index.html
[34] https://bitbucket.org/ArneBab/site
[35] https://bitbucket.org/ArneBab/wisp/
[36] https://www.draketo.de/proj/hgsite/index.html
[37] https://bitbucket.org/ArneBab/wisp/downloads/wisp-1.0.tar.gz
[38] https://fosdem.org/2019/schedule/event/experiencewithwisp/
[39] http://readable.sourceforge.net/
[40] http://www.draketo.de/proj/with-guise-and-guile/wisp-project.html
[41] https://www.draketo.de/proj/with-guise-and-guile/wisp-tutorial.html
[42] https://bitbucket.org/ArneBab/wisp/src/v1.0/NEWS
[43] https://www.draketo.de/light/english/wisp-lisp-indentation-preprocessor#sec-2
[44] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.9.1.tar.gz
[45] https://bitbucket.org/ArneBab/wisp/src/v0.9.9.1/NEWS
[46] https://www.draketo.de/light/english/wisp-lisp-indentation-preprocessor#sec-3
[47] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.9.tar.gz
[48] https://bitbucket.org/ArneBab/wisp/src/v0.9.9/NEWS
[49] http://www.draketo.de/proj/with-guise-and-guile/wisp-tutorial.html
[50] https://www.draketo.de/proj/with-guise-and-guile/index.html
[51] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.8.tar.gz
[52] https://bitbucket.org/ArneBab/wisp/src/v0.9.8/NEWS
[53] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.7.tar.gz
[54] https://bitbucket.org/ArneBab/wisp/src/v0.9.7/NEWS
[55] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.6.tar.gz
[56] http://www.draketo.de/proj/with-guise-and-guile/
[57] https://bitbucket.org/ArneBab/wisp/src/v0.9.6/NEWS
[58] https://www.archlinux.de/
[59] https://wiki.archlinux.org/index.php/Arch_User_Repository#Installing_packages
[60] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.2.tar.gz
[61] https://bitbucket.org/ArneBab/wisp/src/v0.9.2/examples/duel.w
[62] https://bitbucket.org/ArneBab/wisp/src/v0.9.2/examples/benchmark.w
[63] https://bitbucket.org/ArneBab/wisp/src/v0.9.2/NEWS
[64] https://www.gnu.org/software/guile/news/gnu-guile-220-released.html
[65] http://lists.gnu.org/archive/html/guile-devel/2017-03/msg00059.html
[66] https://fosdem.org/2017/schedule/event/naturalscriptwritingguile/
[67] https://fosdem.org/2017/schedule/track/gnu_guile/
[68] https://video.fosdem.org/2017/K.4.601/naturalscriptwritingguile.vp8.webm
[69] https://fosdem.org/2017/schedule/event/naturalscriptwritingguile/attachments/slides/1653/export/events/attachments/naturalscriptwritingguile/slides/1653/2017_01_30_Mo_natural_script_writing_guile.pdf
[70] https://fosdem.org/2017/schedule/event/naturalscriptwritingguile/attachments/slides/1654/export/events/attachments/naturalscriptwritingguile/slides/1654/2017_01_30_Mo_natural_script_writing_guile.org
[71] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.1.tar.gz
[72] https://bitbucket.org/ArneBab/wisp/src/v0.9.1/NEWS
[73] https://fosdem.org/2016/schedule/event/guilewisp/
[74] https://fosdem.org/2016/schedule/track/gnu_guile/
[75] https://twitter.com/hashtag/lisp?src=hash
[76] https://twitter.com/hashtag/python?src=hash
[77] https://twitter.com/ArneBab
[78] https://twitter.com/hashtag/fosdem?src=hash
[79] https://t.co/TaGhIGruIU
[80] https://twitter.com/JANieuwenhuizen/status/693376287730171904
[81] https://fosdem.org/2016/schedule/event/guilewisp/attachments/slides/911/export/events/attachments/guilewisp/slides/911/fosdem2016_arne_babenhauserheide_wisp.pdf
[82] https://fosdem.org/2016/schedule/event/guilewisp/attachments/other/912/export/events/attachments/guilewisp/other/912/fosdem2016_arne_babenhauserheide_wisp.org
[83] http://gnu.org/s/guix
[84] http://git.savannah.gnu.org/cgit/guix.git/tree/gnu/packages/guile.scm?id=c2e87caaa6b7efb9c18c46fd4f9d4370f68c8db7#n734
[85] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.9.0.tar.gz
[86] http://lists.gnu.org/archive/html/guix-devel/2015-10/msg00114.html
[87] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.6.tar.gz
[88] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/evolve.w
[89] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/newbase60.w
[90] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/cli.w
[91] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/cholesky.w
[92] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/closure.w
[93] https://bitbucket.org/ArneBab/wisp/src/v0.8.6/examples/hoist-in-loop.w
[94] http://python.org
[95] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.3.tar.gz
[96] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.2.tar.gz
[97] https://bitbucket.org/ArneBab/wisp/src/v0.8.2/examples
[98] http://srfi.schemers.org/srfi-119/srfi-119.html
[99] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.1.tar.gz
[100] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.8.0.tar.gz
[101] https://bitbucket.org/ArneBab/wisp/src/v0.8.0/NEWS
[102] http://schemers.org/
[103] https://bitbucket.org/ArneBab/wisp/downloads/wisp-0.6.6.tar.gz
[104] https://bitbucket.org/ArneBab/wisp/src/d62499d0d9b876e44c4717c0aed8c7ad98b7f8af/NEWS?at=default
[105] http://github.com/krisajenkins/wispjs-mode
[106] http://marmalade-repo.org/packages/wisp-mode/0.1.5
[107] http://marmalade-repo.org/packages/wisp/0.1.4
[108] https://bitbucket.org/ArneBab/wisp/get/v0.5.tar.bz2
[109] https://bitbucket.org/ArneBab/wisp/commits/0509e9e3418789ef307ae49b7dd862380c5c5bf8
[110] https://bitbucket.org/ArneBab/wisp/get/v0.3.1.tar.bz2
[111] https://www.draketo.de/proj/wisp/src/eef180617d24bad925b0e85769b8e851fb57f2dc/Changelog.html
[112] http://srfi.schemers.org/srfi-49/srfi-49.html
[113] https://bitbucket.org/ArneBab/wisp/src/5dfd8644882d181d61c479b0f82be0e644ca9fd6/examples/enter-three-witches.w#lines-210
[114] http://sourceforge.net/mailarchive/forum.php?thread_name=4161580.FVPfGjZCMV@fluss&forum_name=readable-discuss
[115] http://sourceforge.net/mailarchive/message.php?msg_id=30511834
[116] http://bitbucket.org/ArneBab/wisp
[117] https://bitbucket.org/ArneBab/wisp/get/v0.2.tar.bz2
[118] http://srfi.schemers.org/srfi-110/srfi-110.html#wisp
[119] http://ftp.fau.de/fosdem/2017/K.4.601/naturalscriptwritingguile.vp8.webm
[120] https://live.fosdem.org/watch/k4601
[121] https://hg.sr.ht/~arnebab/dryads-wake
[122] https://dryads-wake.1w6.org
[123] https://hg.sr.ht/~arnebab/ews
[124] https://www.draketo.de/english/wisp/fosdem2017-stream
[125] http://draketo.de/english/wisp
[126] https://pypi.python.org/pypi/TextRPG/
[127] http://shakespeare.mit.edu/macbeth/macbeth.1.1.html
[128] https://www.gnu.org/software/guile/manual/html_node/Syntax-Case.html
[129] https://bitbucket.org/ArneBab/textrpg/src/tip/branching_story.py
[130] https://en.wikipedia.org/wiki/Shakespeare_(programming_language)
[131] https://www.draketo.de/english/wisp
[132] https://www.reddit.com/r/programming/comments/3ku1uk/programming_languages_allow_expressing_ideas_in/cv14ph7
[133] https://www.draketo.de/files/2015-09-12-Sa-Guile-scheme-wisp-for-low-ceremony-languages_0.org
[134] https://www.draketo.de/files/enter-three-witches.w
[135] https://www.epubli.com/shop/going-from-python-to-guile-scheme-9783737568401
[136] http://draketo.de/proj/py2guile
[137] http://draketo.de/proj/py2guile/py2guile.pdf
[138] https://hg.sr.ht/~arnebab/py2guile
[139] https://www.draketo.de/software/programming-scheme
[140] http://youtu.be/u1sVfGEBKWQ
[141] http://www.gnucash.org/
[142] https://lilypond.org/
[143] http://c2.com/cgi/wiki?GreenspunsTenthRuleOfProgramming
[144] http://freedomdefined.org
[145] http://gnu.org/l/gpl
[146] https://www.draketo.de/py2guile
[147] https://www.epubli.de/shop/buch/47692
[148] https://www.hyphanet.org
[149] http://127.0.0.1:8888/CHK@JZBNnKzunLtyYGA6GJ2HyqUgGo~pVzszPvzyfLRLp6k,jI6YaGFUfqytvIDatXOY8WT3aXHJ9tFMbo3ACayczRM,AAMC--8/py2guile.epub
[150] http://localhost:8888/CHK@Nso0TrK6nWeWoCaNpUV2XPrDMO5IwMCDE1DDNWm2NAs,gBo6HPBo02C9TMTA0hHxuxs1p0tBzWELhn-uR7x7zjc,AAMC--8/py2guile.mobi
[151] http://localhost:8888/CHK@thG7xQ9xQ0wA-Z9kcQB4pKgcUIWUcgBymnORfXbnZGA,O7dUHg2ycWznmRdfLG14m35w0~qrjx9cuZBnS3exBhg,AAMC--8/py2guile.pdf
[152] http://127.0.0.1:8888/CHK@PtreU3X0X19mWyeNL2MBwS11vpgEAtFryt2imsHPJbY,i8aZuoFePpXdgTWooj-57f1uVOdNvczhSACuvTnAdyw,AAMC--8/py2guile-0.9.0-fn.tar.gz
[153] https://selenic.com/pipermail/mercurial/2016-January/049210.html
[154] http://draketo.de/py2guile
[155] https://plus.google.com/u/0/105415590548476995777/posts/Rsv1zEZYQiM
[156] https://www.quora.com/Is-it-true-that-Python-is-a-dying-language/answer/Arne-Babenhauserheide?srid=zIZz&share=ea54a346
[157] https://plus.google.com/u/0/105415590548476995777/posts/XJbhXeQtUc2
[158] https://www.python.org/dev/peps/pep-0481/
[159] http://www.snarky.ca/how-i-stay-happy-making-open-source-software
[160] http://www.snarky.ca/the-history-behind-the-decision-to-move-python-to-github
[161] http://www.gentoo.org/proj/en/glep/glep-0023.html#accept-license
[162] http://draketo.de/stichwort/gentoo
[163] http://pkgcore.org
[164] http://mczyzewski.com/post/keeping-your-gentoo-clean
[165] http://www.pkgcore.org
[166] http://www.pkgcore.org/trac/pkgcore/report/1
[167] https://www.draketo.de/filme/frei/hurd-codeswarm-1991-2010-no-it-aint-forever3.ogv
[168] http://www.youtube.com/watch?v=1YFUY6g5dJ8
[169] http://getfirefox.com
[170] http://draketo.de/proj/shared_codeswarm/
[171] http://hurd.gnu.org
[172] http://www.seantwright.com/
[173] http://www.jamendo.com/de/album/68089
[174] http://blog.flameeyes.eu/2011/05/15/just-accept-it-truth-hurds
[175] http://www.gnu.org/software/hurd/hurd/status.html
[176] http://www.gnu.org/software/hurd/#index4h1
[177] https://www.draketo.de/node/447#incorporated
[178] https://www.draketo.de/node/447#translators
[179] https://www.draketo.de/node/447#network-transparency
[180] https://www.draketo.de/node/447#unionmount
[181] https://www.draketo.de/node/447#start-as-needed
[182] https://www.draketo.de/node/447#capabilities
[183] https://www.draketo.de/node/447#virtualization
[184] https://www.draketo.de/node/447#lowlevel-hacking
[185] https://www.draketo.de/node/447#memory-management
[186] https://www.draketo.de/node/447#summary
[187] http://fuse.sourceforge.net/
[188] http://www.gnu.org/software/hurd/hurd/documentation/translators.html
[189] http://netbsd-soc.sourceforge.net/projects/hurdt/
[190] http://flattr.com/thing/273582/Some-technical-advantages-of-the-Hurd
[191] http://kilobug.free.fr/hurd/pres-en/abstract/html/
[192] http://www.gnu.org/software/hurd/community/weblogs/ArneBab/niches_for_the_hurd.html
[193] http://www.gnu.org/software/hurd/hurd/documentation.html
[194] http://www.bddebian.com/~hurd-web/community/weblogs/ArneBab/technical-advantages-of-the-hurd/
[195] https://gnu.org/l/agpl
[196] https://gnu.org/l/gpl
[197] https://www.quora.com/Software-Engineering-What-is-the-truth-of-10x-programmers/answer/Arne-Babenhauserheide?prompt_topic_bio=1
[198] https://www.draketo.de/light/english/free-software/write-programs-you-can-hack-while-you-feel-dumb
[199] http://lists.ibiblio.org/pipermail/cc-licenses/2015-October/007699.html
[200] http://creativecommons.org/weblog/entry/46186
[201] http://www.fsf.org/blogs/licensing/creative-commons-by-sa-4-0-declared-one-way-compatible-with-gnu-gpl-version-3
[202] http://blender.org
[203] http://reprap.org/
[204] http://wikipedia.org
[205] http://ryzom.com/
[206] http://wesnoth.org
[207] http://1w6.org/english/flyerbook-rules
[208] http://kde.org
[209] http://mercurial.selenic.com
[210] https://www.draketo.de/light/english/communicate-your-project#why
[211] https://www.draketo.de/light/english/communicate-your-project#bab-com
[212] https://www.draketo.de/light/english/communicate-your-project#good
[213] https://www.draketo.de/light/english/communicate-your-project#communicate
[214] https://www.draketo.de/light/english/communicate-your-project#target
[215] https://www.draketo.de/light/english/communicate-your-project#questions
[216] https://www.draketo.de/light/english/communicate-your-project#wishes
[217] https://www.draketo.de/light/english/communicate-your-project#answers
[218] https://www.draketo.de/light/english/communicate-your-project#further
[219] https://www.draketo.de/light/english/communicate-your-project#mission
[220] https://www.draketo.de/light/english/communicate-your-project#summary
[221] http://www.gnu.org/software/guile/
[222] http://wingolog.org/archives/2013/01/07/an-opinionated-guide-to-scheme-implementations
[223] http://www.gnu.org/software/guile/manual/guile.html#Programming-in-C
[224] http://phyast.pitt.edu/~micheles/scheme/
[225] http://www.gnu.org/prep/standards/standards.html#Source-Language
[226] http://www.nongnu.org/geiser/
[227] http://en.wikipedia.org/w/index.php?title=GNU_Guile&oldid=564014065
[228] http://en.wikipedia.org/wiki/GNU_Guile
[229] http://www.gnu.org/software/hurd/community/weblogs/antrik/hurd-mission-statement.html
[230] http://www.gnu.org/software/guile/manual/html_node/Guile-and-the-GNU-Project.html
[231] https://www.gnu.org/prep/standards/standards.html#NEWS-File
[232] https://www.gnu.org/prep/standards/standards.html
[233] https://metacpan.org/pod/distribution/CPAN-Changes/lib/CPAN/Changes/Spec.pod
[234] https://gnu.org/s/wget/
[235] https://github.com/ArneBab/lib-pyFreenet-staging/blob/py3/copyweb
[236] https://www.draketo.de/english/download-web-page-with-all-prerequisites#options
[237] https://www.draketo.de/english/download-web-page-with-all-prerequisites#getting
[238] https://gnu.org/s/wget
[239] http://gnuwin32.sourceforge.net/packages/wget.htm
[240] http://eternallybored.org/misc/wget/
[241] http://www.cybershade.us/winwget/
[242] http://www.mingw.org/wiki/MSYS
[243] https://www.cygwin.com/
[244] http://www.finkproject.org/
[245] http://brew.sh/
[246] http://www.macports.org/
[247] http://osxdaily.com/2012/05/22/install-wget-mac-os-x/
[248] http://dirk-weise.de/2009/02/wget-fur-mac-os-x-installieren/
[249] https://bitbucket.org/ArneBab/conf/
[250] http://stackoverflow.com/a/28466267/7666
[251] http://stackoverflow.com/questions/402377/using-getopts-in-bash-shell-script-to-get-long-and-short-command-line-options/28466267#28466267
[252] https://creativecommons.org/licenses/by-sa/4.0/
[253] http://www.draketo.de/english/free-software/by-sa-gpl
[254] https://www.draketo.de/light/english/install-gnu-guix-03
[255] https://www.gnu.org/software/guix/manual/en/guix.html#Binary-Installation
[256] http://www.gnu.org/software/guix/manual/guix.html#Build-Environment-Setup
[257] http://www.gnu.org/software/guix/manual/guix.html#Application-Setup
[258] http://emacswiki.org/emacs/GuileEmacs
[259] https://www.gnupg.org/gph/en/manual/x135.html
[260] https://addons.mozilla.org/de/thunderbird/addon/enigmail/
[261] http://gpg4win.org/download.html
[262] https://gpgtools.org/
[263] https://www.gnupg.org/download/
[264] https://www.draketo.de/software/makefile-to-autotools
[265] https://web.archive.org/web/20190411070135/http://www.freesoftwaremagazine.com/books/autotools_a_guide_to_autoconf_automake_libtool
[266] http://www.flameeyes.eu/autotools-mythbuster/
[267] http://www.gnu.org/savannah-checkouts/gnu/autoconf/manual/autoconf-2.69/html_node/index.html
[268] http://www.gnu.org/software/automake/manual/html_node/
[269] http://gnu.org/s/pyconfigure
[270] https://en.wikipedia.org/wiki/Cargo_cult_programming
[271] http://en.wikipedia.org/wiki/Unix_Shell
[272] http://www.gnu.org/software/make/
[273] https://www.draketo.de/files/2013-03-05-Di-make-to-autotools.org
[274] https://www.draketo.de/files/2013-12-11-Mi-quodlibet-broken_2.pdf
[275] https://www.draketo.de/files/2013-12-11-Mi-quodlibet-broken_2.org
[276] http://code.google.com/p/quodlibet/
[277] http://packages.gentoo.org/package/media-sound/quodlibet
[278] http://code.google.com/p/quodlibet/issues/detail?id=1304#c4
[279] http://gentoo.org
[280] https://www.draketo.de/english/quod-libet-bug-solution-process#sec-3
[281] http://forums.gentoo.org/viewtopic-t-977278-highlight-pygobject.html
[282] http://dot.kde.org/2013/09/25/frameworks-5
[283] http://code.google.com/p/quodlibet/issues/detail?id=1304
[284] http://code.google.com/p/quodlibet/issues/detail?id=1304#c1
[285] https://bugs.gentoo.org/show_bug.cgi?id=493472#c13
[286] http://code.google.com/p/quodlibet/issues/list
[287] http://bugs.gentoo.org
[288] http://www.chiark.greenend.org.uk/~sgtatham/bugs.html
[289] https://www.draketo.de/files/2013-12-11-quod-libet-broken.png
[290] https://www.draketo.de/files/2013-12-11-quod-libet-broken-clearlooks.png
[291] https://www.draketo.de/files/2013-12-11-quod-libet-broken-plugins.png
[292] https://www.draketo.de/files/2013-12-11-quod-libet-fixed.png
[293] https://www.draketo.de/files/2016-06-08-hurd-howto-140-chars.png
[294] http://www.gnu.org/software/hurd/community/weblogs/ArneBab/technical-advantages-of-the-hurd.html
[295] https://people.debian.org/~sthibault/hurd-i386/README
[296] http://www.gnu.org/software/hurd/hurd/running/qemu.html
[297] http://www.gnu.org/software/hurd/contributing.html#index4h2
[298] http://qemu.org
[299] https://www.draketo.de/files/2016-06-08-hurd-howto-140-combined.png
[300] https://www.draketo.de/files/2016-06-08-hurd-howto-140-combined.xcf
[301] https://www.draketo.de/files/hurd-test-2017.webm
[302] http://lists.ibiblio.org/pipermail/cc-licenses/2014-May/007579.html
[303] http://1w6.org/releases/wuerfel.png
[304] http://1w6.org/deutsch/anhang/artwork/cover
[305] http://1w6.org/releases/
[306] http://1w6.org/releases/cover-tim-2.6.0.xcf
[307] http://draketo.de/light/english/free-software/makefile-to-autotools#sec-2
[308] http://mercurial.selenic.com/wiki/LargefilesExtension
[309] https://www.draketo.de/light/english/fortran-surprises#sec-3-3
[310] https://www.draketo.de/light/english/fortran-surprises
[311] https://www.draketo.de/english/free-software/fortran
[312] https://www.draketo.de/files/2013-09-04-Mi-guix-install_5.org
[313] https://www.draketo.de/files/2013-09-04-Mi-guix-install_4.pdf
[314] http://gnu.org
[315] http://audio-video.gnu.org/video/ghm2013/Ludovic_Courtes-GNU_Guix_the_computing_freedom_deployment_tool_.webm
[316] https://www.gnu.org/ghm/2013/paris/
[317] http://thejh.net/misc/website-terminal-copy-paste
[318] http://stevelosh.com/blog/2013/09/teach-dont-tell/#first-contact
[319] http://stevelosh.com/blog/2013/09/teach-dont-tell/#the-black-triangle
[320] http://hydra.gnu.org
[321] http://draketo.de/light/english/me-gentoo-about-convenient-choice
[322] http://www.gnu.org/software/emacs/
[323] http://orgmode.org
[324] http://validator.w3.org/check?uri=referer
[325] http://sourceforge.net/projects/tm5/
[326] http://www.scc.kit.edu/dienste/hc3.php
[327] https://www.draketo.de/light/english/install-scipy-pynio-cluster-intel#fn.1
[328] http://draketo.de/dateien/scipy-pynio-deps
[329] http://draketo.de/dateien/scipy-pynio-deps/PyNIO-1.4.1.tar.gz
[330] http://draketo.de/dateien/scipy-pynio-deps/SuiteSparse.tar.gz
[331] http://www.cise.ufl.edu/research/sparse/SuiteSparse/current/
[332] http://draketo.de/dateien/scipy-pynio-deps/atlas3.6.0.tar
[333] http://draketo.de/dateien/scipy-pynio-deps/basemap-1.0.1.tar
[334] http://draketo.de/dateien/scipy-pynio-deps/cblas.tar
[335] http://draketo.de/dateien/scipy-pynio-deps/curl-7.21.7.tar.bz2
[336] http://draketo.de/dateien/scipy-pynio-deps/geos-3.3.2.tar.bz2
[337] http://draketo.de/dateien/scipy-pynio-deps/git-1.7.6.1.tar.bz2
[338] http://draketo.de/dateien/scipy-pynio-deps/hdf-4.2.7.tar.bz2
[339] http://draketo.de/dateien/scipy-pynio-deps/hdf5-1.8.7.tar.bz2
[340] http://draketo.de/dateien/scipy-pynio-deps/lapacke.tar
[341] http://draketo.de/dateien/scipy-pynio-deps/libgemm-20000228.tar.bz2
[342] http://draketo.de/dateien/scipy-pynio-deps/matplotlib-1.0.1.tar
[343] http://draketo.de/dateien/scipy-pynio-deps/matplotlib-1.1.0.tar.gz
[344] http://draketo.de/dateien/scipy-pynio-deps/netCDF4-0.9.7.tar
[345] http://draketo.de/dateien/scipy-pynio-deps/netcdf-4.1.3.tar.gz
[346] http://draketo.de/dateien/scipy-pynio-deps/numpy-1.6.1.tar
[347] http://draketo.de/dateien/scipy-pynio-deps/pyhdf-0.8.3.tar.gz
[348] http://draketo.de/dateien/scipy-pynio-deps/scipy-0.9.0.tar
[349] http://draketo.de/dateien/scipy-pynio-deps/scons-2.0.1.tar.gz
[350] http://www.gnu.org/distros/free-distros.html
[351] http://draketo.de/dateien/scipy-pynio-deps/zoneinfo-2010g.tar.gz
[352] https://xkcd.com/208/
[353] http://www.imk-asf.kit.edu/mitarbeiter_110.php
[354] http://www.imk-asf.kit.edu/english/763.php
[355] http://openindiana.org/
[356] http://draketo.de/dateien/scipy-pynio-deps/SuiteSparse-umfpack.diff
[357] http://draketo.de/dateien/scipy-pynio-deps/SuiteSparse.diff
[358] http://draketo.de/dateien/scipy-pynio-deps/hdf-fix-configure.ac.diff
[359] http://draketo.de/dateien/scipy-pynio-deps/lapacke-ifort.diff
[360] http://draketo.de/dateien/scipy-pynio-deps/matplotlib-add-icc-support.diff
[361] http://draketo.de/dateien/scipy-pynio-deps/netcdf-patch1.diff
[362] http://draketo.de/dateien/scipy-pynio-deps/netcdf-patch2.diff
[363] http://draketo.de/dateien/scipy-pynio-deps/numpy-icc.diff
[364] http://draketo.de/dateien/scipy-pynio-deps/numpy-icpc.diff
[365] http://draketo.de/dateien/scipy-pynio-deps/numpy-ifort.diff
[366] http://draketo.de/dateien/scipy-pynio-deps/pynio-fix-no-grib.diff
[367] http://draketo.de/dateien/scipy-pynio-deps/scipy-qhull-icc.diff
[368] http://draketo.de/dateien/scipy-pynio-deps/scipy-qhull-icc2.diff
[369] http://draketo.de/dateien/scipy-pynio-deps/scipy-spatial-lifcore.diff
[370] https://www.draketo.de/files/2013-09-26-Do-installing-scipy-and-matplotlib-on-a-bare-cluster-with-the-intel-compiler.org
[371] https://www.youtube.com/watch?v=FR754e5xIwg
[372] https://www.youtube.com/watch?v=9IxE2UQqJCw
[373] https://www.infoq.com/news/2023/07/linkedin-protocol-buffers-restli/
[374] https://www.linkedin.com/blog/engineering/infrastructure/linkedin-integrates-protocol-buffers-with-rest-li-for-improved-m
[375] https://flatbuffers.dev/
[376] https://capnproto.org/otherlang.html
[377] https://yoric.github.io/post/binary-ast-newsletter-1/
[378] http://seriot.ch/parsing_json.php#41
[379] http://docs.scipy.org/doc/numpy/reference/c-api.dtype.html
[380] http://keyj.s2000.ws/?p=356
[381] http://identi.ca/conversation/25438506
[382] http://identi.ca
[383] http://theora.org
[384] http://bigbuckbunny.org
[385] http://www.bigbuckbunny.org/index.php/about/
[386] https://www.draketo.de/files/bbb-400bps.ogg
[387] http://www.mozilla-europe.org/en/firefox/
[388] https://www.draketo.de/files/bbb-400bps_0.264
[389] http://identi.ca/notice/25557640
[390] https://www.draketo.de/files/encode_0.sh
[391] http://www.phoronix.com/scan.php?page=article&item=llvm_clang33_fx8350&num=1
[392] http://phoronix.com/forums/showthread.php?80125-GCC-vs-LLVM-Clang-On-AMD-s-FX-8350-Vishera&p=328159#post328159
[393] http://www.phoronix.com/scan.php?page=news_item&px=MTUwODQ
[394] https://twitter.com/Leadwerks/status/399704102151540736
[395] http://www.kickstarter.com/projects/1937035674/leadwerks-build-linux-games-on-linux/posts/650985?at=BAh7B0kiCHVpZAY6BkVUaQNZNBdJIgtleHBpcnkGOwBUSSIYMjAxMy0xMi0wNCAyMDowNToxNQY7AFQ%3D--ba60e9f772205879833875829b4b2df0aaef5df1&ref=backer_project_update
[396] http://www.phoronix.com/scan.php?page=article&item=amd_6800k_compilers&num=1
[397] http://www.phoronix.com/scan.php?page=article&item=intel_haswell_llvm33&num=1
[398] http://openbenchmarking.org/result/1304249-UT-LLVMCLANG22#overview_table
[399] http://phoronix.com/forums/member.php?26107-Nobu
[400] http://www.kickstarter.com/projects/1937035674/leadwerks-build-linux-games-on-linux/posts/658785
[401] https://twitter.com/Leadwerks
[402] https://twitter.com/Leadwerks/status/399705618027511808
[403] https://twitter.com/JoshKlint
[404] https://twitter.com/JoshKlint/status/399705005269069824
[405] https://twitter.com/JoshKlint/status/399987021454004224
[406] http://sourceware.org/gdb/onlinedocs/gdb/Frames.html
[407] http://www.ohloh.net/projects/26?p=Python
[408] http://www.greenteapress.com/thinkpython/
[409] http://mitpress.mit.edu/books/little-schemer
[410] http://legacy.python.org/dev/peps/pep-0020/
[411] https://www.draketo.de/light/english/wisp-lisp-indentation-preprocessor
[412] https://www.draketo.de/files/2014-03-05-Mi-recursion-wins.org
[413] http://blogs.gnome.org/johan/2007/01/18/introducing-python-launcher/
[414] http://www.gnome.org/~johan/python-launcher-0.1.0.tar.gz
[415] http://www.socat.org
[416] http://stackoverflow.com/questions/6485848/avoid-python-setup-time/10894340#10894340
[417] https://www.draketo.de/files/python-launcher-0.1.0.tar.gz
[418] https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
[419] https://www.gnu.org/licenses/agpl-3.0.html
[420] https://www.gnu.org/software/texinfo/manual/texinfo/texinfo.html#Overview
[421] https://www.draketo.de/files/2016-09-12-Mo-replacing-man-with-info_1.org
[422] https://www.draketo.de/files/screencast-tabbing-everywhere-kde.ogv
[423] http://recordmydesktop.sourceforge.net/
[424] http://www.kdenlive.org/
[425] http://v2v.cc/~j/ffmpeg2theora/
[426] http://draketo.de/light/english/screencast-tabbing-everything-kde#comment-350
[427] https://www.draketo.de/dateien/kde/07-beat-into-submission-solo.ogg
[428] http://www.jamendo.com/de/album/1003/
[429] http://creativecommons.org/licenses/by-sa/2.5/
[430] https://www.draketo.de/licenses
[431] https://www.draketo.de/dateien/kde/screencast-tabbing-everywhere-kde-raw.ogv
[432] https://www.draketo.de/light/english/pyrad
[433] https://www.draketo.de/files/2015-04-15-Mi-simple-daemon-openrc_2.pdf
[434] https://www.draketo.de/files/2015-04-15-Mi-simple-daemon-openrc_2.org
[435] https://plus.google.com/u/0/+LucaBarbato/posts
[436] http://smarden.org/runit/runsvdir.8.html
[437] http://freenetproject.org
[438] http://credence-p2p.org
[439] http://www.talkingpixels.org/diggclone/index.php
[440] http://www.bandnet.org
[441] http://www.gnu.org/licenses/gpl.txt
[442] http://mediacast.sun.com/share/webmink/SunLicensingWhitePaper042006.pdf
[443] http://blogs.sun.com/webmink/entry/open_source_licensing_paper#comments
[444] http://bitbucket.org/ArneBab
[445] https://sf.net/projects/rpg-1d6/
[446] https://sourceforge.net/project/showfiles.php?group_id=199744
[447] https://www.quora.com/Is-Python-the-best-programming-language-Why/answer/Arne-Babenhauserheide
[448] https://www.python.org/dev/peps/pep-0020/
[449] http://www.draketo.de/english/free-software/minimal-python-script
[450] https://www.draketo.de/stichwort/python
[451] https://www.draketo.de/files/base60.f90
[452] http://faruk.akgul.org/blog/tantek-celiks-newbase60-in-python-and-java/
[453] http://tantek.pbworks.com/w/page/19402946/NewBase60
[454] https://www.draketo.de/files/surprises.org
[455] https://www.draketo.de/files/accumulate.f90
[456] https://www.draketo.de/files/accumulate-not.f90
[457] https://www.draketo.de/files/base60-surprises.f90
[458] https://www.draketo.de/files/trim.f90
[459] https://www.draketo.de/files/surprises.pdf
[460] https://www.draketo.de/files/surprises.html
[461] https://www.draketo.de/light/english/free-software/tco-debug#golden-rule
[462] http://gnu.org/s/gcc
[463] https://www.draketo.de/light/english/free-software/tco-debug#nice-backtraces
[464] http://akfoerster.de/
[465] https://www.draketo.de/zitate#golden-rule
[466] http://gcc.gnu.org/gcc-4.8/changes.html
[467] http://www.phoronix.com/scan.php?page=news_item&px=MTE3NDg
[468] http://freedesktop.org/wiki/Software/systemd/
[469] https://www.draketo.de/light/english/top-5-systemd-troubles#control
[470] https://guix.gnu.org/
[471] https://www.gnu.org/software/shepherd/
[472] https://wiki.gentoo.org/wiki/OpenRC
[473] https://wiki.gentoo.org/wiki/Comparison_of_init_systems
[474] https://www.agwa.name/blog/post/how_to_crash_systemd_in_one_tweet
[475] https://wiki.gentoo.org/wiki/Project:OpenRC
[476] https://wiki.gentoo.org/wiki/Runit#OpenRC_supervision_service
[477] https://web.archive.org/web/20170630231146/http://news.dieweltistgarnichtso.net/posts/systemd-assumptions-bullying-consent.html
[478] https://www.debian.org/vote/2014/vote_003
[479] https://vote.debian.org/~secretary/gr_initcoupling/
[480] https://lists.debian.org/debian-ctte/2014/11/msg00091.html
[481] https://lists.debian.org/debian-vote/2014/10/msg00001.html
[482] http://www.debianfork.org/
[483] https://www.draketo.de/politik/poettering-hetzt
[484] https://www.draketo.de/politik/poettering-hetzt#fn:technische-kritik
[485] http://boycottsystemd.org/
[486] http://igurublog.wordpress.com/2014/04/08/julian-assange-debian-is-owned-by-the-nsa/
[487] http://igurublog.wordpress.com/2014/04/03/tso-and-linus-and-the-impotent-rage-against-systemd/
[488] https://lkml.org/lkml/2014/4/2/420
[489] https://firstlook.org/theintercept/2014/02/24/jtrig-manipulation/
[490] http://forums.gentoo.org/viewtopic-t-984580.html
[491] https://lists.debian.org/debian-ctte/2014/02/msg00461.html
[492] https://www.draketo.de/english/comments/light/never-trust-a-company
[493] http://lwn.net/Articles/513224/
[494] http://lists.debian.org/debian-devel/2012/04/msg00751.html
[495] http://lists.debian.org/debian-devel/2012/04/msg00768.html
[496] http://lists.debian.org/debian-devel/2012/04/msg00649.html
[497] http://lists.debian.org/debian-devel/2013/11/msg00113.html
[498] http://lists.debian.org/debian-devel/2012/04/msg00638.html
[499] http://lists.debian.org/debian-devel/2011/07/msg00281.html
[500] http://lists.debian.org/debian-devel/2012/04/msg00654.html
[501] http://gentooexperimental.org/~patrick/weblog/archives/2013-10.html#e2013-10-29T13_39_32.txt
[502] http://www.gentoo.org/proj/en/eudev/
[503] http://www.joelonsoftware.com/articles/StrategyLetterV.html
[504] http://forums.gentoo.org/viewtopic-p-7409132.html#7409132
[505] http://www.joelonsoftware.com/articles/fog0000000020.html
[506] http://wiki.gentoo.org/wiki/Comparison_of_init_systems
[507] http://0pointer.de/blog/projects/the-biggest-myths
[508] https://www.draketo.de/proj/py2guile/#sec-2-2-3-2-1
[509] http://gentooexperimental.org/~patrick/weblog/archives/2013-10.html#e2013-10-09T08_32_52.txt
[510] http://gentooexperimental.org/~patrick/weblog/archives/2013-10.html#e2013-10-09T09_33_21.txt
[511] https://wiki.debian.org/Debate/initsystem/systemd#Portability
[512] http://transcom.project.asu.edu/transcom03_protocol_basisMap.php
[513] http://tldp.org/LDP/Bash-Beginners-Guide/html/sect_07_03.html
[514] http://www.gnu.org/licenses/agpl-3.0.html
[515] http://drupal.org
[516] https://www.draketo.de/files/weltenwald-theme-2010-08-05_r1.tar.bz2
[517] https://www.quora.com/Which-language-is-best-C-C++-Python-or-Java/answer/Arne-Babenhauserheide?prompt_topic_bio=1
[518] https://www.quora.com/Which-language-is-best-C-C++-Python-or-Java
[519] http://chimera.labs.oreilly.com/books/1234000001813/index.html
[520] http://en.gnufu.net
[521] http://de.gnufu.net
[522] http://snarky.ca/why-python-3-exists
[523] http://snarky.ca/how-to-pitch-python-3-to-management
[524] http://blog.pysoy.org/
[525] http://pysoy.org
[526] http://1w6.org
[527] http://psychclassics.yorku.ca/Miller/
[528] http://newsoffice.mit.edu/2011/miller-memory-0623
[529] https://www.djangoproject.com/
[530] https://docs.djangoproject.com/en/dev/misc/design-philosophies/#loose-coupling
[531] http://www.djangobook.com/en/1.0/chapter01/#s-the-mvc-design-pattern
[532] http://paulgraham.com/head.html
[533] https://bitbucket.org/ArneBab/evolve-keyboard-layout/overview
[534] https://www.joelonsoftware.com/2000/04/06/things-you-should-never-do-part-i/
[535] http://daringtolivefully.com/how-to-enter-the-flow-state
[536] https://www.ted.com/talks/matt_killingsworth_want_to_be_happier_stay_in_the_moment/
[537] http://sachachua.com/blog/2010/11/limiting-flow-lifeworkwork-lifebalancegeek/
[538] http://worrydream.com/refs/Brooks-NoSilverBullet.pdf
[539] http://www.draketo.de/english/free-software/fortran#orgheadline1
[540] http://www.draketo.de/english/free-software/fortran#orgheadline2
[541] http://www.draketo.de/english/free-software/fortran#orgheadline3
[542] http://www.draketo.de/english/free-software/fortran#orgheadline4
[543] http://www.draketo.de/english/free-software/fortran#orgheadline5
[544] http://www.draketo.de/english/free-software/fortran#orgheadline6
[545] https://gcc.gnu.org/fortran/
[546] http://www.openmp.org/
[547] https://www.heise.de/developer/artikel/Fortran-im-Wandel-der-Zeit-3677272.html
[548] https://www.draketo.de/files/2017-04-10-Mo-fortran-commandline-tool.pdf
[549] https://www.draketo.de/files/2017-04-10-Mo-fortran-commandline-tool.org
[550] https://bugzilla.mozilla.org/show_bug.cgi?id=147777
[551] http://startpanic.com/
[552] http://bitbucket.org/ArneBab/babsniff_history_css/src/tip/server.py
[553] http://bitbucket.org/ArneBab/babsniff_history_css/src/tip/server_stripped.py
[554] http://www.whattheinternetknowsaboutyou.com/docs/solutions.html
[555] http://www.schlockmercenary.com/d/20071201.html
[556] http://www.schlockmercenary.com/d/20071206.html
[557] http://www.schlockmercenary.com/schlock_author.html
[558] http://www.tug.org/pracjourn/2006-4/fenn/
[559] http://tex.stackexchange.com/a/255023/53957
[560] http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf
[561] http://python.org/download/
[562] http://www.riverbankcomputing.co.uk/software/pykde/intro
[563] http://bitbucket.org/ArneBab/pyrad
[564] http://kubuntu.org
[565] https://www.draketo.de/files/pyrad-0.4.3-fullscreen.png
[566] http://kde-apps.org/content/show.php/pyRad?content=117428
[567] http://pypi.python.org/pypi/pyRadKDE/
[568] https://www.draketo.de/files/pyrad-0.4.3-screenshot.png
[569] https://www.draketo.de/files/pyrad-0.4.3-screenshot-edit-action.png
[570] https://www.draketo.de/files/pyrad-0.4.3-screenshot-edit-folder.png
[571] https://www.draketo.de/files/pyrad-0.4.3-screenshot2.png
[572] https://www.draketo.de/files/pyrad-0.4.3-screenshot3.png
[573] https://www.draketo.de/files/powered_by_kde_horizontal_190.png
[574] https://www.draketo.de/files/pyrad-0.4.3-fullscreen-400x320.png
[575] https://www.draketo.de/files/pyrad-0.4.4-screenshot-edit-action.png
[576] https://bugs.gentoo.org/298675
[577] http://packages.gentoo.org/package/kde-misc/pyrad
[578] http://www.gentoo.org/proj/en/sunrise/
[579] http://overlays.gentoo.org/proj/sunrise
[580] http://www.gentoo.org/proj/en/Python/
[581] http://gnu.org/s/bash
[582] https://www.draketo.de/files/parse_wikipedia_files_to_html.py.txt
[583] http://yaml.org

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}