Hier finden sich Skripte, Ideen und vieles andere aus meinem Physik Studium.
Aus meiner Doktorarbeit gibt es hier leider wenig, weil in dem KIT-Doktoranden-Vertrag explizite, strafbewehrte Geheimhaltungsklauseln stehen: Ich muss vor jeder Veröffentlichung von Sachen, die direkt Teil meiner Arbeit sind, eine Erlaubnis von der Monopol-Abteilung (IP) einholen. Deswegen gibt es v.a. technisches, in Freie Software [1] und Free Software [2], das ich nur als Werkzeug nutze, das aber nicht Teil meiner eigentlichen Arbeit ist.
Update 2016: Die Endfassung meiner Doktorarbeit gibt es in der KIT-Bibliothek: Inverse modelling of carbon dioxide surface fluxes - estimating uncertainties due to model design and observational constraints - Arne Babenhauserheide [3] - dank der in den letzten Jahren geänderten Veröffentlichungsrichtlinien unter Open Access Lizenz!
Dank Open Access kann ich allerdings darüber schreiben, sobald daraus eine wissenschaftliche Veröffentlichung hervorgeht. Daher bin ich den Leuten vom IMK-ASF [4] sehr dankbar, dass hier fast nur in Open Access Journalen veröffentlicht wird.
Links 2007:
Ein paar Lieder zu Physik u.ä. finden sich unter stichwort/filk [9].
Ich habe gerade in der Taz wieder viele Kommentare [10] gelesen, in denen der Einfluss der Menschen auf das Klima bestritten wurde. Daher möchte ich hier einen der neueren, wenn auch weniger rigoros publizierten Belege nennen: Berkeley Earth [11].
Den Wissenschaftlern von Berkeley Earth waren die traditionellen Modelle zu unklar, und die Methoden zu wenig durchsichtig. Deswegen haben sie sich selbst dran gemacht, die existierenden Daten zu sichten und die verschiedensten möglichen Ursachen als Auslöser zu prüfen.
Das Ergebnis: Die Landtemperatur erhöht sich seit 50 Jahren um durchschnittlich 0,9°C pro 50 Jahre. In den 200 Jahren vorher waren es nur etwa 0,15°C pro 50 Jahre. Und für die letzten 250 Jahre lassen sich die Temperaturschwankungen alleine mit Vulkanausbrüchen und der CO₂-Konzentration in der Atmosphäre sehr gut rekonstruieren (die Vulkanausbrüche verringern die Landtemperatur durch Aerosole in der Atmosphäre).
Ihre Ergebnisse stimmen hervorragend mit den traditionellen Modellen von NOAA [12], NASA [13] und CRU [14] überein.
→ Results Summary [15] (Videos [16])
Dabei sind hauptsächlich Menschen verantwortlich für den steigenden CO₂-Gehalt in der Atmosphäre, da die Natur im Gleichgewicht ein Nullsummenspiel spielt (im Sommer wird das aufgenommen, was im Winter abgegeben wird, und am Tag wird aufgenommen, was in der Nacht abgegeben wird).
Menschen fügen diesem Kreislauf CO₂ aus der Erdkruste hinzu, einer Quelle, die sonst nicht zugänglich ist, und in die die Natur das CO₂ nicht auf der gleichen Zeitskala zurückbringen kann. Daher wird es erstmal auf die bestehenden Reservoirs Ozean, Land und Atmosphäre verteilt. Bis das von uns in den letzten 50 Jahren abgegebene zusätzliche CO₂ auf natürlichem Weg wieder in der Erdkruste landet, wird es weit über 10.000 Jahre dauern. Und so viel Zeit haben wir einfach nicht…
→ Größenordnungen im Kohlenstoff-Kreislauf [17]
[18]
The carbon cycle, a short overview (pdf) [18]
PS: Brände fließen über die Global Fire Emission Database (GFED) [19] in die Modelle ein. Für den CO₂-Gehalt der Atmosphäre auf der Zeitskala von Jahrzehnten sind natürliche Brände weniger wichtig, da sie nur Kohlenstoff von der Biosphäre (v.a. Pflanzen) in die Atmosphäre umverteilen, den die Pflanzen in den nächsten Jahren wieder aufnehmen, während sich auf der verbrannten Fläche wieder Pflanzen ansiedeln. Bei von Menschen brandgerodeten und durch bodenzerstörende Anbaubmethoden verödeten Flächen ist das anders.
 I did a 10 minute talk about the basics of the carbon cycle. Since I think that it worked out quite well, I’m publishing the slides here under the GPL [20] (=licensed free and copyleft).
I did a 10 minute talk about the basics of the carbon cycle. Since I think that it worked out quite well, I’m publishing the slides here under the GPL [20] (=licensed free and copyleft). Ich habe einen 10 Minuten Vortrag zu den grundlegenden Mechanismen des Kohlenstoffkreislaufs gehalten. Da er meiner Meinung nach gut geworden ist, veröffentliche ich ihn hier unter der GPL [21] (=frei und copyleft lizensiert).
Ich habe einen 10 Minuten Vortrag zu den grundlegenden Mechanismen des Kohlenstoffkreislaufs gehalten. Da er meiner Meinung nach gut geworden ist, veröffentliche ich ihn hier unter der GPL [21] (=frei und copyleft lizensiert).
The carbon cycle, a short overview (pdf) [18]
If you want to use it, you can directly work on my source files:Falls ihr ihn nutzen wollt, könnt ihr direkt meine Quelldateien verwenden:
Remember: GPL means: name previous authors, publish your source files and put what you create with it under the GPL, too.Denk daran: GPL heißt: Nennt die Vorautoren, veröffentlicht eure Quellen und stellt damit erstelltes auch unter die GPL.
Die Bilder stammen aus Battle for Wesnoth [25] ↩
| Anhang | Größe |
|---|---|
| carbon-cycle-free.pdf [18] | 312.37 KB |
| carbon-cycle-free.odp [22] | 387.22 KB |
| cc-bilder.zip [24] | 353.7 KB |
| cc-preview.png [26] | 20.26 KB |
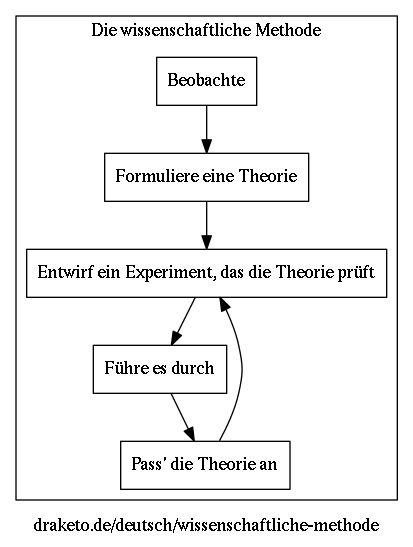
(0) Beobachte (1) Formuliere eine Theorie (2) Entwirf ein Experiment, das die Theorie prüft (3) Führe es durch (4) Pass die Theorie an → (2)
 [27]
[27]
Hintergründe und Weiterführendes gibt es z.B. bei Spektrum der Wissenschaft: Die wissenschaftliche Methode [28]
Englische Fassung: The scientific method in a dent/tweet (140 characters) [29]
PS: bei Nichtfalsifizierbarem funktioniert Punkt (2) nicht (prüfen), so dass hoffentlich klar ist, dass dafür eine komplexere Methode nötig ist.
| Anhang | Größe |
|---|---|
| wissenschaftliche-methode.dot [30] | 619 Bytes |
| wissenschaftliche-methode.png [31] | 11.26 KB |
| wissenschaftliche-methode.dot [27] | 620 Bytes |
| wissenschaftliche-methode.png [32] | 11.26 KB |
Ich habe mein Studium mit dem festen Vorsatz begonnen, genau so viel zu machen, wie ich kann, und damit möglichst effizient zu studieren.
Und das hieß auch: Niemals mehr als 3 große Vorlesungen gleichzeitig hören.
Meine erste Migräne, viel Stress und einiges an verbogenen Nerven haben mir deutlich gezeigt, dass ich mich daran hätte halten sollen.
Also habe ich jetzt endlich einen realistischen Studienplan entworfen, nach dem ich mich hätte richten sollen, und der mit Bachlor zwar etwas veraltet sein mag, neuen Studierenden aber vielleicht trotzdem noch hilft.
Einen weiteren Schritt auf dem Weg findet ihr in meinem Lied Studier im Rhythmus [33].
-> Hier das Info-Vordiplom
-> Vordiplom in theoretischer Physik
-> In der Vorlesungsfreien Zeit: Anfängerpraktikum 1
-> Mathe Vordiplom
-> Experimentalphysik-Vordiplom
-> Vordiplom fertig.
-> Diplomprüfung Theoretische Physik
-> Diplomprüfung Nebenfach
-> Diplomprüfung Wahlpflichtfach vor Ende des Semesters
-> Diplomprüfung Experimentalphysik vor Ende des Semesters
(Begründung: Wenn eine fehlschlägt, kann man sie als nicht existent werten und ohne Nachteile wiederholen).
-> Diplom abgeschlossen.
Das ist ein altes Datei-Blog, das ich geschrieben habe, bevor ich das Blog hier sinnvoll nutzen konnte.
Es handelt von dem Versuch zur Fouriertransformation des AP2 (Physikalisches Anfängerpraktikum 2) der Uni Heidelberg und wurde geschrieben, während ich in den letzten Stunden des Auswertens war...
Ich habe den Originaltext komplett mit Tippfehlern und allem übernommen (nur Zeilenumbrüche korrigiert), da ich denke, dass sie ein Teil des Fourier-Erlebnisses sind... ;)
Viel Spaß beim Lesen! :)
#Blog über Versuch 233:Fouriersynthese des Physikalischen Praktikums IIA der Uni-Heidelberg.
Jetzt komme ich endlich zum Bloggen.
Status:
- Bisheriger Aufwand: 8h Vorbereitung +3h Durchführung + 14,5h Aufgabe 1 + 6h Aufgabe 2 + 4h Mathematik von Aufgabe 3 mit wxMaxima umsetzen, alles in allem bisher 35 Stunden arbeit und immernoch eineinhalb Aufgaben vor mir.
Woher ich mir die Zeit nehme, dieses Blog zu schreiben?
es ist halb drei nachts, morgen muss die Auswertung fertig und abgegeben sein und ich warte auf die Plots von wxMaxima.
Waren das Zeiten, als Programme noch auf Lochkarten kamen. Damals dauerte es eine Nacht, bis das Programm durch war. Heute sind mir schon 5 min Wartezeit auf recht lange Funktionen zu viel.
Aber ich wollte erzählen, wie ich Fourier überlebt... ich meine natürlich, wie ich Fourier gelöst habe.
Eigentlich sind die Aufgaben nicht ganz so übel, wie ich erwartet hätte, wenn ich gleich zu Anfang verstanden hätte, wie sie gehen und es nicht so eine verfluchte Arbeit wäre, Dinge verständlich und klar zu dokumentieren. Die reine Schreibarbeit bei Aufgabe 1 war 6 Stunden. Bei Aufgabe 2 waren es dann "nur noch" eineinhalb Stunden.
Aber da ich gerade bei Aufgabe drei bin:
- Ich benutze wxMaxima, weil es frei und GPL-lizensiert ist.
- Ich habe ein Gentoo-Linux auf meinem iMac, weil mir Apple zu nervig geworden
ist (nach einer Lebenszeit als MacUser, Infos: http://bah.draketo.de [34] ).
- Um wxMaxima die 3 berechnen zu lassen, nehmt einfach cdie folgenden
Schritte:
-----
define(numerische_lsg_n1(y),sum((sin(2*m/20*%pi/104*104/2)/(2*m/20*%pi/104*104/2))*cos(2*m/20*%pi/104*y),m,1,20*1))
define(numerische_lsg_n2(y),sum((sin(2*m/20*%pi/104*104/2)/(2*m/20*%pi/104*104/2))*cos(2*m/20*%pi/104*y),m,1,20*2))
...
plot2d([104*%pi*numerische_lsg_n1(x)^2], [x,-104,104], [plot_format, gnuplot], [gnuplot_preamble, "set grid"], [nticks,100])$
...
-----
Nullstellen müsst ihr hier leider graphisch suchen. Wenn ihr was besseres findet, nutzt das. Newton hat mich verlassen *schnüff* :)
Um das mittlere Maximum auszublenden, fang das addieren einfach nach dem ersten Max erst an (statt startwert 1, startwert 20*1).
Nebenbei dazu: Ich hatte keine Lust, aber als ich dann plötzlich gesehen habe, dass es ganz einfach ist, habe ich es halt doch gemacht.
2. Aufguss Grüntee steht an. Der erste zog nur 30s (30 mal Teebeutel ins Wasser und wieder raus), der nächste braucht wohl eine Minute. Der dritte wird
dann wohl bitter... naja, die Nacht muss noch jung gehalten werden. Eigentlich wollte ich dieses Blog schon bei Aufgabe 1 anfangen :)
---
Wenn euch übrigens Maxima abstürzen sollte, könnt ihr es mit einem einfachen pkill -9 lisp.run abschießen. Dann hört der lisp.run Prozess auf jegliche Systemkapazität zu fressen (was übrigens die Reaktionsgeschwindigkeit des Systems seltsamerweise kaum beeinträchtigt, um es anders zu sagen: Ich habe es nie bemerkt).
---
Das war's.
Computerteil für *argl* Was sind das für Spitzen beim ausblenden des zentralen Maximums!!!
Wie auch immer. Computerteil für Aufgabe 3 abgeschlossen. jetzt wird nur noch Mit Papier, Stift und Taschenrechner gearbeitet.
Sobald mein Mitbewohner aus der Falle gekommen ist und ich seinen Drucker wieder benutzen kann.
---
Also komme ich zur 4 (in meiner internen Zählung übrigens die 5. Mein KWord hat die Überschriftenzählung mit 1 angefangen und ich wollte in der handschriftlichen Vorbereitung die Zählung der Überschriften nicht ändern *gg* .
Die Mathematik der 4 lässt sich in fast derselben Art lösen.
Einfach Formel ersetzen.
Version für Doppelspalt:
define(numerische_lsg_doppel_n1(y),sum((cos(2*m/20*%pi/116*283/2)/(2*m/20*%pi/116*116/2))*sin(2*m/20*%pi/116*116/2)*cos(2*m/20*%pi/116*y),m,1,20*1))
Zum Plotten:
plot2d([2*116/%pi*numerische_lsg_doppel_n1(x)^2], [x,-300,300], [plot_format, gnuplot], [gnuplot_preamble, "set grid"], [nticks,100])$
Und passt auf, dass ihr auch ..._n1(x)^2 nehmt und nicht ..._n1(y)^2. Im letzteren Fall läuft euch nämlich Maxima aka lisp.run amok, heißt, ihr dürft es abschießen und in der History von wxMaxima zurückgehen, definitionen wiederholen.
Jetzt das ganze mal allgemeiner:
define(numerische_lsg_doppel_n1(y),sum((cos(2*m/20*%pi/d*g/2)/(2*m/20*%pi/d*d/2))*sin(2*m/20*%pi/d*d/2)*cos(2*m/20*%pi/d*y),m,1,20*1)
plot2d([2*116/%pi*numerische_lsg_doppel_n1(x)^2], [x,-300,300], [plot_format, gnuplot], [gnuplot_preamble, "set grid"], [nticks,100])$
---
2006-03-06 04:41:27: Jetzt sind auch alle Rechnungen und Entwürfe für die 3 abgeschlossen. Noch knapp eine Stunde zum sorgfältigen Dokumentieren. aber das mache ich, nachdem ich die 4 gerechnet habe.
Ach ja: Das graphische Auslesen habe ich jetzt mit Geodreieck am Bildschirm gemacht :)
Zum Glück kann man bei den Plots zumindest ein halbwegs laufendes Raster einblenden (ist aktiviert in dem Code, "set grid").
---
2006-03-06 04:45:59: Hiermit sind auch die Bilder des Doppelspaltes abgespeichert (vorher lagen sie "nur" als angezeigte Plots vor, jetzt habe ich sie mit "import ", dem Bildschirmfoto-Befehl von imagemagick, abgespeichert. Für die Dokumentation ziehe ich sie noch in Scribus und gebe ihnen Titel und Lizenztag (cc Arne Babenhauserheide
- http://draketo.de [35]
- Lizenz: att-nc-sa
---
Bei der 4 habe ich natürlichgerade völlig unsinnigerweise in meiner Freude das es geht unwichtige Bilder erzeugt. Ich brauche sie nicht für die Auswertung.
Egal. Hat Spaß gemacht :)
Jetzt habe ich gerade den Teiler der Funktion auf 500 erhöht, um eine feinere Auslösung schmaler Spalte zu haben. So kann ich wirklich in die Funktionen schauen. Merkt man, dass ich etwas müde bin? :)
Natürlich verhackstücke ich mir damit jegliche Intensitätsmessungen. es gibt nur noch qualitative Betrachtungen, aber den Wert für n kann ich damit finden.
500 war eine blöde Wahl. Ich geh auf 200. Mehr als 100 Teile stellt wxMaxima nicht dar, also kann ich mit 500 nicht mit hoch genugem n ( >0.2 ) Plotten.
Ich hoffe ich erinnere mich an die Plots. erst 200n05, dann 200n04, dann 200n03, 200n025,200n02... Laaangsam! zum Glück habe ich Musik im Hintergrund, die dank mpd nur 1% Prozessorlast verursacht.
Zwischen 025 und 03, da irgendwo habe ich den Übergang von 2 Hubbeln auf einen, auf nur noch die Spaltfunktion.0.275 ist nahe dran! 0.27 näher!Und näher kann ich mit dieser Einstellung nicht.
YAPP! DONE! DIE!
Teein... sag jemand was über legale Drogen ;)
---
2006-03-06 05:39:18: Die Notizen zur 4 sind auch fertig. Wenn nicht noch irgendwas fehlt.
"Morgen" wird mein Mitbewohner nochmal gelöchert, das heißt: Sobald er halbwegs aufgestanden ist.
Verdammt, ich muss noch vorbereitung fertig machen. 2 schon geplante Seiten _schön_ schreiben. In meinem Zustand. Pfft.
Körper verlangt Leben... argl...
In dem zustand sollte man vielleicht nicht unbedingt Subway to Sally hören.
*egg* (aka *evil giggle*, wobei ja eigentlich *evil gamemasters grin*. Dann also: *eggg* aka *evil gamemasters giggle*! :) )
Wir haben ein Problem, für das wir eine Näherung kennen, die aber nur für Abschnitte gilt, die klein gegenüber dem Gesamtproblem sind.1
Also teilen wir das Problem in unendlich viele, unendlich kleine Teile, die jeweils garantiert viel kleiner sind, als das Gesamtproblem. Auf die Art wissen wir, dass wir jeden einzelnen Teil linear nähern dürfen (da x² nun unendlich viel kleiner ist als x, verschwindet es völlig, also ist nur x wichtig, der lineare Teil des Problems).2
Dann addieren wir die Teile und erhalten so eine neue, exakte Gleichung. Sie ist zwar an unendlich vielen Punkten genähert, aber der durch das ignorieren von x² entstehende Fehler ist nun unendlich klein:
Gesamtfehler durch Näherung
≈ Einzelfehler • Anzahl Abschnitte
= ∞⁻² • ∞ = ∞⁻¹ = 0
PS: Keine Gewähr.
Mein erstes Papier ist seit dem 25. März 2015 in Interaktiver Diskussion und seit 1. September 2015 veröffentlicht:
Comparing the CarbonTracker and TM5-4DVar data assimilation systems for CO₂ surface flux inversions [37]
— A. Babenhauserheide, S. Basu, S. Houweling, W. Peters and A. Butz
 [38]
[38]
(alle Bilder, die ich hier nutze, sind Open Access,1 genauer gesagt: unter cc by [39] lizensiert: A. Babenhauserheide. Bitte nennt die Autoren und verlinkt das Papier [40], wenn ihr sie verwendet.)
Zusammen mit den Co-Autoren habe ich zwei Inverse Modelle verglichen, mit denen die CO₂ Quellen und Senken in der Biosphäre (wie verrottende Blätter und Kohlenstoffaufnahme in Wäldern) optimiert werden, um konsistent mit Messungen der CO₂ Konzentration in der Atmosphäre zu sein.
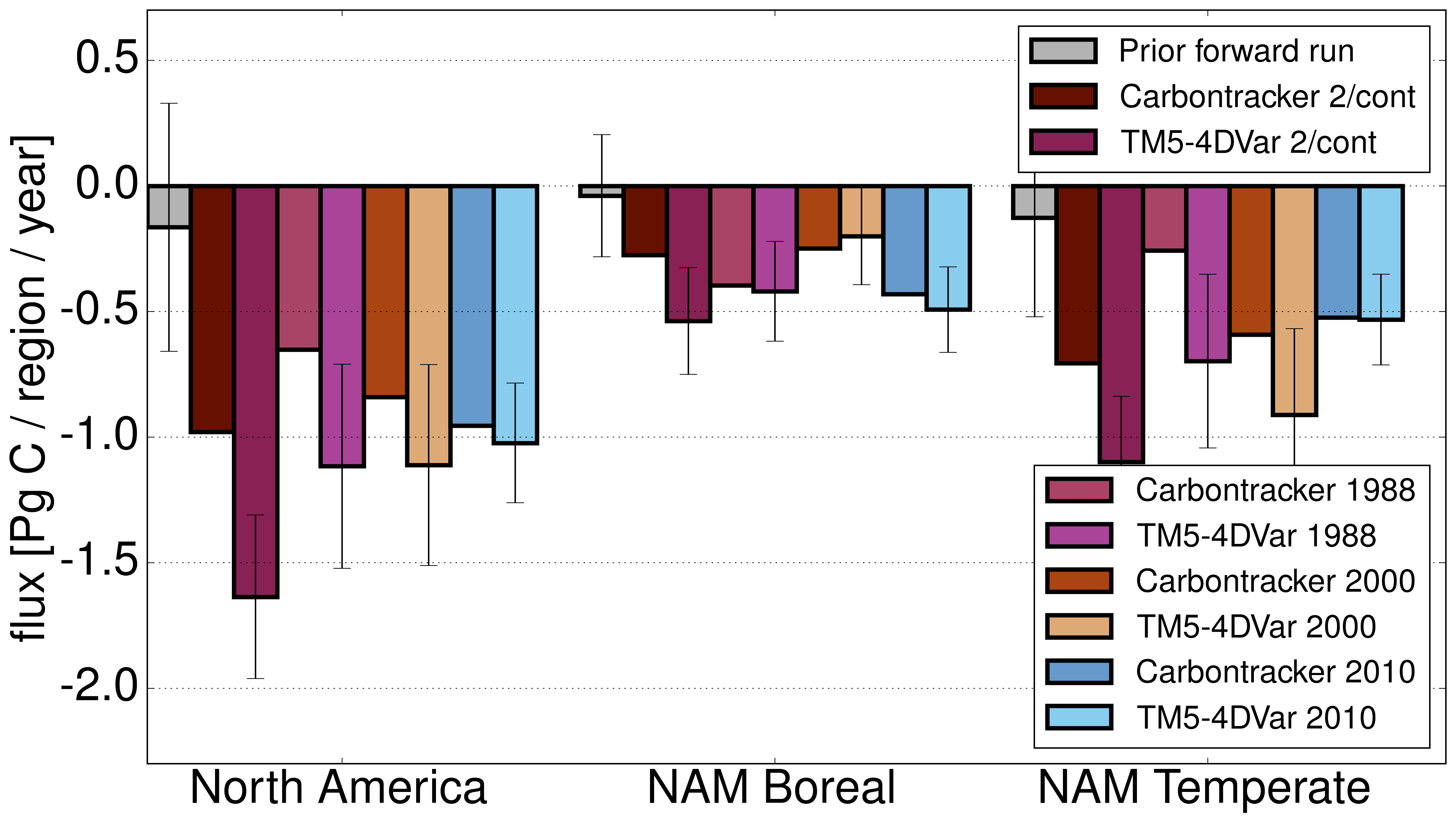
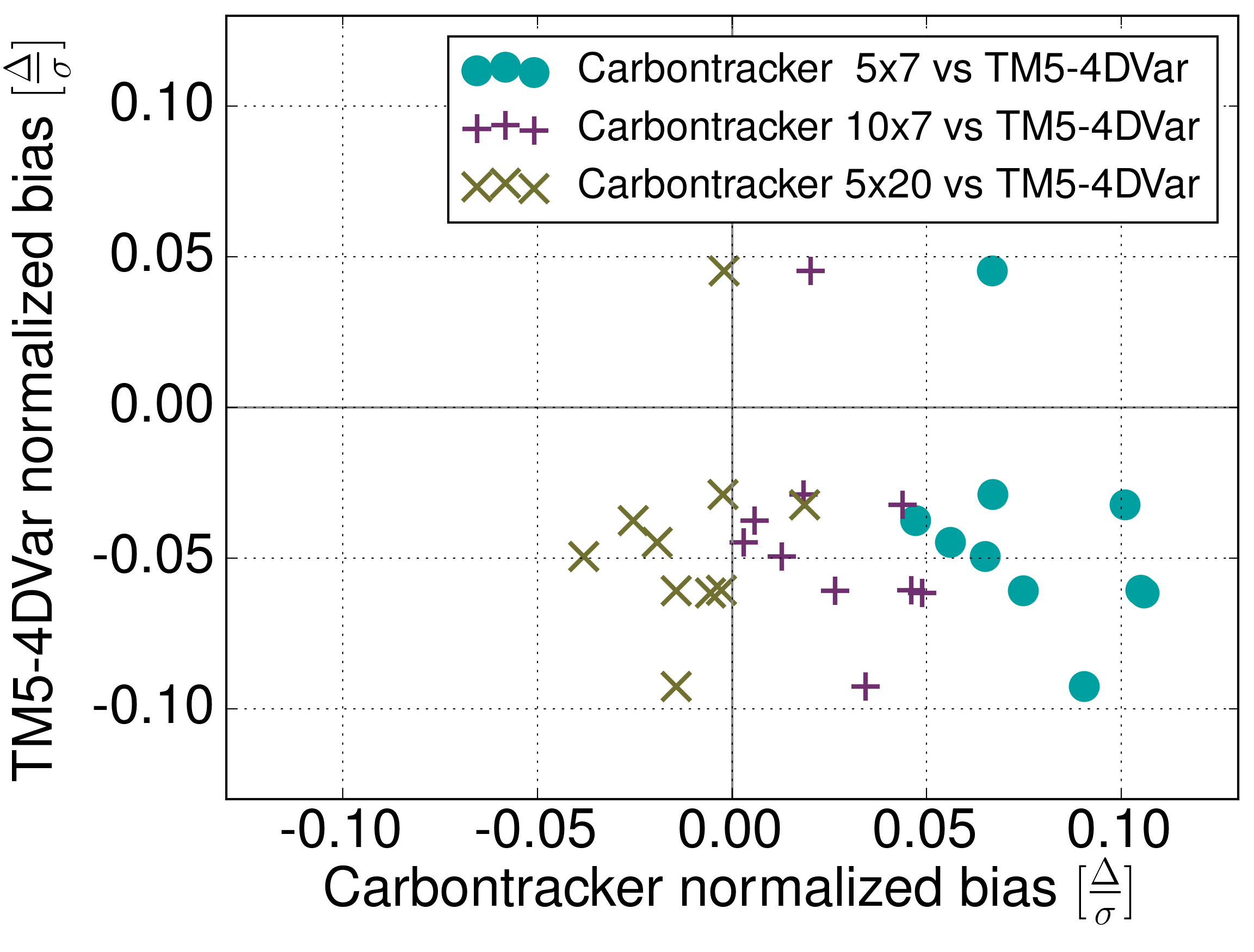
Wir konnten zeigen, dass die Modelle im Rahmen der Validierungsmöglichkeiten gleich gut sind, die Mindestunsicherheit abschätzen, die bei dem genutzten Messnetzwerk (Stationen von 2010) für Quellen und Senken durch Annahmen im Inversen Modell bewirkt wird (auf kontinentaler Skala im Durchschnitt bei 0.25 PgC/a — in der Größenordnung der halben jährlichen Europäischen Flüsse), und zeigen, dass bei steigender Beobachtungsdichte der Unterschied zwischen beiden Modelles sinkt, so dass ein dichteres Messnetzwerk es ermöglichen würde, robuste Flüsse auf Subkontinentaler Skala zu erhalten.
Verkürzt:
 [41]
[41]
Außerdem konnten wir einige interessante Aspekte der Flüsse in der Antarktis und in Asien untersuchen.
Die Ergebnisse klingen erstmal nach wenig, waren aber drei Jahre Arbeit: Beide Modelle zum Laufen bringen, dafür sorgen, dass alle Eingabeparameter und Eingabedaten hinreichend gleich sind, und relevante, statistisch robuste Vergleiche zu finden. Und debuggen, debuggen, debuggen :)
Von der Aussage „wir haben Ergebnisse“
bis hin zu „unsere Ergebnisse sind wissenschaftlich tragfähig“
ist es ein weiter Weg: Wir haben ein Jahr lang immer und immer wieder neue Vergleiche und Analysen laufen lassen, geprüft und diskutiert, bis wir ein Ergebnis hatten, mit dem wir zufrieden waren. Es war viel Arbeit, aber sie war es wert.
Und damit zurück zum Papier.
Die beiden verglichenen Modelle sind Carbontracker [42] und TM5-4DVar [43].
Carbontracker ist das etablierte Modell des Earth Science Research Lab [12] von NOAA. Es liefert operative2 CO₂ Flüsse (Quellen und Senken) und wird durch einem internationalen Team von Wissenschaftlern weiterentwickelt. Wouter Peters [44] aus den Niederlanden ist dabei eine der treibenden Kräfte und war Erstautor des ursprünglichen Papiers zu Carbontracker:
An atmospheric perspective on North American carbon dioxide exchange: CarbonTracker [45]
— Wouter Peters, Andrew R. Jacobson , Colm Sweeney , Arlyn E. Andrews, Thomas J. Conway, Kenneth Masarie, John B. Miller, Lori M. P. Bruhwiler, Gabrielle Pétron , Adam I. Hirsch , Douglas E. J. Worthy, Guido R. van der Werf, James T. Randerson , Paul O. Wennberg, Maarten C. Krol , and Pieter P. Tans
TM5-4DVar ist ein eng mit dem Transport Model 5 (TM5) [46] verzahntes inverses Modell, das bis vor ein paar Jahren hauptsächlich in den Niederlanden entwickelt wurde, von wo aus Sander Houweling [47] weiterhin als einer der Hauptentwickler agiert. Der Erstautor des Papiers, das wir zu TM5-4DVar referenziert haben ist Sourish Basu, der uns viel mit dem Aufsetzen und verstehen des Modells geholfen hat:
Global CO₂ fluxes estimated from GOSAT retrievals of total column CO₂ [48]
— S. Basu, S. Guerlet, A. Butz, S. Houweling, O. Hasekamp, I. Aben, P. Krummel, P. Steele, R. Langenfelds, M. Torn, S. Biraud, B. Stephens, A. Andrews, and D. Worthy
Das Papier fängt wie üblich mit der Einleitung an: Warum ist das hier wirklich wichtig. Die Kurzform der Antwort ist: Weil die globalen Modelle für Quellen und Senken von CO₂ viel besser werden müssen, wenn wir erkennen wollen, wie die Biosphäre auf den Klimawandel reagiert. Wenn wir das nicht können, haben wir kaum eine Chance einzugreifen, wenn sich das ändert. Aktuell nehmen Ozeane und Biosphäre etwa 50% des CO₂ auf, das wir in die Atmosphäre pumpen. Würde das wegfallen, würden die CO₂ Konzentrationen doppelt so schnell steigen wie bisher. Und aktuell könnten wir nur sagen, dass sich etwas ändert, aber nicht wo.
Danach kommt die minimale Menge an Mathematik, um die Modelle zu verstehen (Dank für eine deutlich kompaktere Darstellung geht an André, meinen Gruppenleiter), gefolgt von der Beschreibung des Aufbaus: Welche Daten nutzen wir, wie bereiten wir sie auf, aus welchen Modellen kommen sie, welche Modelle sind Teil unserer Prozessierungskette und was für Experimente machen wir.
Und dann kommen wir zu den Ergebnissen.
Um das etwas spannender zu machen, habe ich sie im up-goer five text editor beschrieben [49]:
We let think-boxes dream two dreams starting from the same ideas how much animal-breath we can find in the air at less than one hundred places in the world and where animal-breath could go to and where it could come from.
The dreams of the think-boxes search for better ideas where animal-breath could come from and where it could go to.
To find out how good the dreams fit the real world we look how different they are from places where we know how much animal breath is in the air which we did not tell the think-boxes about when they started to dream.
Then we look where the dreams are different to get an idea how close they are to the real world. This idea is not the real world but it tells us how different the real world can be from the dreams.
We find that the dreams are so close to each other that we can not say which one is better.
We also find that we do not know whether the old world is a place where animal-breath goes to or where it comes from.
But we see that when we would have as many places which look at animal-breath at every place in the world as in the new world, then we could know about the old world, too. And to find out for smaller places whether animal-breath goes there or whether it comes from there, we only need to start more places where we watch animal-breath.
Twenty new places should allow understanding the old world well enough that we would see it when its woods would take up only half as much animal breath as the year before.
And that is what I did for three years: Finding out how well we know where animal-breath comes from and goes to.
Und um das abzurunden, gleich noch den Grund, warum ich das eigentlich mache:
This is what I do for work:
I tell think-boxes how to find out where animal-breath which we can see in the air comes from and goes to.
That animal-breath warms our world because it holds warming light down which the ground sends up away. It does not only come from animals, but also from burning things which we bring out from the ground where they had rested.
We can see how much of that animal-breath is in the air at the moment, but only on the ground at very few places or from high up with much wrong-being.
To find out where it comes from, I tell the think-boxes to dream many different dreams. They dream where the animal-breath could come from and how much of it we would see if the dream were true at the places in the world at which we know how much there really is. Then they change the dreams to make how much animal-breath the dreams see fit better what we see in the real world.
And when the dreams agree with what we see in the real world, we think that what the dreams say where the animal-breath comes from and goes to is close to where it comes from in the real world.
And that is what I want to find out: I try to learn where animal-breath comes from and where it goes.
Das war’s ☺
Ich hoffe, euch hat meine Beschreibung meines Papiers gefallen!
Was ich hier geschrieben habe ist nur eine Annäherung an das Papier und ganz sicher keine offizielle Übersetzung. Wer sich über irgendetwas hier wundert und damit ins Internet rennt, ohne vorher das Papier zu lesen, der oder die ist doof ☺
Damit sollte auch klar sein, wie ernst ich solche Beschwerden nehmen würde.
Dank Open Access darf ich jetzt auch endlich darüber schreiben, was ich die letzten zwei Jahre gemacht habe. In meinem Arbeitsvertrag steht nämlich „Klappe halten“, und erst die Lizensierung unter cc Namensnennung [39] erlaubt mir formell, die selbsterstellten Grafiken hier zu zeigen. Ich weiß, dass viele das nicht so ernst nehmen, aber ich arbeite an Freenet [50] mit, da will ich mir rechtlich keine offene Flanke geben. ↩
Operativ bedeutet, dass regelmäßig Daten geliefert werden, die als qualitativ hochwertig angesehen werden3, dass andere darauf aufbauen können. ↩
Qualitativ hochwertig heißt in allererster Linie, dass Unsicherheiten sauber angegeben werden. Damit ist klar, welche Aussagen auf Grundlage der Daten getroffen werden können und welche nicht. Bei einem Wert von 3±3 könnte ich zum Beispiel nicht sagen, dass der Wert positiv ist, weil bei einer erneuten Berechnung, die andere (aber gleich gute) Grundlagen verwendet, mit einer Wahrscheinlichkeit von 16% ein negativer Wert herauskommen würde. Bei 3±3 wird der Bereich 0 bis 6 als „ein Sigma“ (1σ) bezeichnet: In diesem Bereich liegen bei Gaussscher Normalverteilung (typischer Zufall) [51] 68% der Messwerte. Der Bereich -3 bis 9 wird als „zwei Sigma“ (2σ) bezeichnet. Darin liegen 95% der Messwerte. Wenn ein Ergebnis außerhalb zwei Sigma liegt, wird das meist als Indikator gesehen, dass es signifikant von dem erwarteten Wert abweicht. Wenn also jemand sagt „in der Tanzkneipe sind normalerweise 15±6 Leute“ und am Karaokeabend zähle ich 30 Leute, sind das mehr als zwei Sigma (der 2σ Bereich ist 3 bis 27) , also könnte ich sagen, dass Karaoke die Anzahl der Leute in der Kneipe signifikant erhöht. Wer gemerkt hat, dass hier was nicht stimmt, weil es nicht möglich ist, um 3σ nach unten abzuweichen, und deswegen die ganze Kneipen-Statistik in Frage stellt, hat recht - und wird vermutlich Spaß an dem Wikipedia-Artikel zur Poisson-Verteilung [52] haben ☺. ↩
| Anhang | Größe |
|---|---|
| flux-histobs-flux-ct-t4d-alternating-nam.pdf [38] | 50.59 KB |
| flux-histobs-flux-ct-t4d-alternating-nam.png [53] | 224.15 KB |
| randomsets-case-resampling-ctvst4d-5x7-5x20.pdf [41] | 148.83 KB |
| randomsets-case-resampling-ctvst4d-5x7-5x20.png [54] | 153.14 KB |
Das ist ein Muster, das ich mir letzten Semester selbst für die Struktur der HEAS Übungsgruppen geschrieben habe.
Ich habe es verwendet, um sicher zu sein, dass ich nicht irgendwas vergesse, und um den Fluss der Übungsgruppen zu verbessern.
Ich hoffe, dass ich das geschafft habe.
Um das Muster zu verwenden, habe ich es mir vor jeder Übungsgruppe vorgenommen und zu jedem Punkt, bei dem etwas auszuarbeiten ist, ein paar Sätze aufgeschrieben (und sie mir oft auch vorgestellt, oder einfach mal vorgesprochen, damit ich wusste, dass sie funktionieren).
Bei den Sachen, die ich selbst ausgearbeitet habe, war es teilweise auch etwas mehr Vorbereitung, um mir das Thema nochmal wirklich zu vergegenwärtigen (und wie ich es präsentieren will).
Und ich hatte das Gefühl dass die Übungsgruppen dadurch sowohl für die Leute als auch für mich sehr viel angenehmer und nützlicher wurden.
Wenn ihr Anmerkungen oder Ideen dazu habt, würde ich mich freuen, wenn ihr einen Kommentar hinterlassen [55] würdet.
Das Muster für die Übungsgruppe
Wenn ihr Anmerkungen oder Ideen zu dem Muster habt, würde ich mich freuen, wenn ihr einen Kommentar schreiben würdet. Ich bin nicht perfekt, und ich möchte, dass dieses Muster für Übungsgruppenleiter so hilfreich wie möglich ist.
Ich habe es mir übrigens (gekürzt) auf einen kleinen Pappstreifen geschrieben, um es immer dabei zu haben (und um in der Übungsgruppe mental abhaken zu können).
- Arne Babenhauserheide
Ich plane, im Herbst 2015 meine Doktorprüfung abzulegen. Am KIT gehen Prüfende dabei gerne auf frühere Nobelpreise ein (natürlich vor allem auf die von Forschern aus Karlsruhe). Das möchte ich als Aufhänger nehmen, mich endlich genauer mit den Themen der Nobelpreise zu beschäftigen. Lange Zeit habe ich sie wenig beachtet, weil ich es nie so mit Autorität hatte und lieber spannende Randgebiete betrachtet habe. Aber für jede Ideologie gibt es einen Punkt, an dem man sie in Frage stellen sollte, und für Nobelpreise ist diese Zeit bei mir gekommen.
Ich will die Nobelpreise der letzten Jahre selbst besser verstehen, und dafür gibt es kaum einen besseren Weg, als sie anderen zu erklären. Genau das will ich hier tun.
Ich fange mit Nobelpreisen für Physik an, sollte aber wohl auch Chemie anschauen.
Auf nobelprize.org [57] gibt es eine Liste aller Nobelpreisträger und Nobelpreisträgerinnen für Physik [58] zusammen mit Kurzbeschreibungen.
Das KIT führt eine eigene Liste der Nobelpreisträger aus Karlsruhe [59], allerdings alle außer der Braunschen Röhre für Chemie.
1993 haben Russell A. Hulse und Joseph H. Taylor Jr. den Nobelpreis in Physik für die Entdeckung des Doppelpulsarsystems PSR1913+16 [60] erhalten.
Anhand des Systems aus zwei Pulsaren konnten sie belegen, dass es Gravitationswellen gibt (was auch ein weiterer Beweis dafür ist, dass es sinnvoll ist, den Himmel zu beobachten, um die Welt zu verstehen ☺).
Gravitationswellen hängen insofern mit Gravitionsmagnetismus zusammen, dass Magnetismus aufgrund der Änderung in der Anziehung durch bewegte Ladung entsteht.
Wenn nun Pulsare Gravitationswellen aussenden, versetzen sie andere Teilchen in Bewegung. Da mit dieser Bewegung Energie transportiert wird, muss das Doppelsystem der Pulsare diese Energie verlieren - und damit Stück für Stück näher zusammenrücken, also mit höherer Frequenz rotieren. Und das wurde in Langzeitmessungen nachgewiesen.
Interessante Fakten:
PDF-version [61] (zum Drucken)
Auf dem YIN-Day 2013 [62] haben sich am 12.10.2013 die verschiedenen Nachwuchsforschergruppen des KIT vorgestellt. Zusätzlich gab es einige Vorträge, die von einer Podiums-Diskussion abgeschlossen wurden.
Diese Diskussion hat mir viel Hoffnung auf die Zukunft der Forschung in Deutschland gemacht, daher möchte ich meine Notizen dazu weitergeben.
Moderiert wurde die Diskussion von Heike Mund, die eine schöne Mischung aus provokanten Fragen und guten Vorlagen beigetragen hat - zu der ich allerdings außer auf Xing [63] keine Informations-Seite gefunden habe.
Ich schreibe hier meine Notizen auf. Die Notizen beinhalten nicht alle Aussagen, sondern nur die Teile, die mir relevant erschienen. In meinen handschriftlichen Notizen habe ich die Aussagen jeweils Personen zugeordnet, statt sie im typischen Interview-Stil nach Fragen zu gruppieren.
Diese Struktur behalte ich hier bei, um Verzerrungen der Aussagen durch möglicherweise falsche Zuordnungen zueinander zu vermeiden.
Da ich nur von Dr. Dorothea Wagner die Erlaubnis bekommen habe, meinen Mitschrieb zu veröffentlichen, habe ich die Aussagen der anderen Diskussionsteilnehmer kurz zusammengefasst.
Heike Mund stellte Fragen zu prekären Arbeitsverhältnissen in der Wissenschaft (Wilfried Porth sprach sofort gegen das Wort „prekär“), zur Konkurrenzsituation in Hochschulen, zu Drittmitteln, zu einer Kultur des Scheiterns und zu Talentförderung.


Hat Leute zur Bewerbung aufgefordert, von dem firmeninternen Nachwuchprojekt gesprochen, in dem es mehr Freiheit gibt als in anderen Geschäftsfeldern und würde sich mehr Produktorientierung an den Universitäten wünschen.

Beschrieb, dass soziale Netze früher auf Konferenzen entstanden, dass ein so früh entstehendes Netz mit YIN aber etwas Neues ist. Er sagte, Medizin und Frauenhofer seien hierachisch, und dass ein richtiges Tenure-Track-Verfahren fehlt. Will 3 Phasen der Wissenschaftlichen Arbeit: Promotion (muss zuende geführt werden können), Post-Dok (2 Jahre), dann eine feste Stelle oder gehen. Wichtig bei YIN sei gewesen, nicht zu viel einzugreifen.

Hat gesagt, dass YIN weitergeht, wenn es gut läuft, und dass nach 2 Jahren Post-Dok entweder entfristet oder gekündigt werden sollte.
Geschwärzte Stellen sind Texte, für die ich keine Freigabe erhalten habe (bzw. keine Antwort - vermutlich ist die E-Mail untergegangen).
Gestern Mittag wurde Philae [75] von Rosetta [76] abgesetzt. Gestern Abend ist Philae gelandet.
Als der ersten Signale ankommen, brauchen die Wissenschaftler scheinbar ein paar Augenblicke, bis sich auf ihren Gesichtern nicht mehr unsichere Freude sondern tiefes Glück zeigt.
“It’s all down to Isaac Newton now, it’s down to the laws of physics. We’re on the way to the surface. […] If Isaac’s is friendly to us, we’ll have a great landing later today.” — Mark McCaughrean
Die beste Live-Berichterstattung hatte meiner Meinung nach XKCD. Sie ist jederzeit nachzuerleben auf xkcd1446 [77].
Von ESA selbst gab es Infos über Twitter:
.@philae2014 [78]’s first postcard just after separation – it’s of me!
#CometLanding [79]
Credit: ESA/Rosetta/Philae/CIVA pic.twitter.com/OXJwGunL3V [80]
— ESA Rosetta Mission (@ESA_Rosetta) November 12, 2014 [81]It’s me… landing on a comet & feeling good! MT @ESA_Rosetta [82]: I see you too! #CometLanding [79] pic.twitter.com/DjU0J1Ey4H [83]
— Philae Lander (@Philae2014) November 12, 2014 [84].@ESA_Rosetta [82] See for yourself! ROLIS imaged #67P [85] when we were just 3km away! Glad I can share. #CometLanding [79] pic.twitter.com/b6mcid2fsn [86]
— Philae Lander (@Philae2014) November 12, 2014 [87]I’m on the surface but my harpoons did not fire. My team is hard at work now trying to determine why. #CometLanding [79]
— Philae Lander (@Philae2014) November 12, 2014 [88]Philae ist gelandet!
Weitere aktuelle Informationen gibt es von NASA JPL auf ustream (natürlich mit Fokus auf die Mitarbeit der NASA):
ESA hat leider keine entsprechend aktuellen Infos. Tipp: Ihr könntet einfach alle Medienberichte zu Rosetta zugänglich machen. Die ARD hatte zum Beispiel einen tollen Beitrag von Ranga Yogeshwar:
(Mission Rosetta - Auf der Suche nach dem Ursprung des Lebens [89] — Download [90])
Und wir hören den Kometen 67P/Churyumov-Gerasimenko durch seinen Einfluss auf das Magnetfeld der Sonne:
Schon jetzt haben die Wissenschaftler um Rosetta viele der Erwartungen erfüllt, die Ambition geweckt hat: Die Europäische Raumfahrt hat magische Augenblicke erlebt.
Visionen zu verwirklichen hat eine große Bedeutung für eine Gesellschaft, und die ESA hat es geschafft, dass diese Vision viele berühren konnte.
PS: Ich kann hier leider keine einzelnen Bilder des Landers zeigen, weil die Urheberrechtsrichtlinien [92] von ESA immernoch inkompatibel mit freier Kultur [93] sind: «If ESA images are to be used in advertising or any commercial promotion, layout and copy must be submitted to ESA beforehand for approval to». Die Bedingungen sind schon viel besser als vor einigen Jahren, aber leider immernoch unbenutzbar. Der Film und die Tweets gehen, weil der EuGH geurteilt hat, dass Einbettung mit den Methoden, die auch die Ursprungsseite nutzt, das Urheberrecht nicht berührt [94].
Für verlässliche Wissenschaft sind reproduzierbare Veröffentlichungen essenziell - aber oft sind sie nicht gegeben12. Dieser 5-Minuten-Vortrag motiviert, wieso Reproduzierbarkeit so wichtig ist, und zeigt eine Lösung zum wirklich reproduzierbaren Veröffentlichen - die er auch selbst nutzt. Ich habe ihn in einem Seminar zum wissenschaftlichen Präsentieren gehalten.
Einen praktischen Leitfaden für entsprechende Veröffentlichungen, den ich auch selbst genutzt habe, liefert das Tutorial: Writing scientific papers for ACP using emacs org-mode [95].
 [96]
[96]
PDF-version [96] (for printing)
Release [97] (to download)
orgmode-version [98] (for editing)
repository [99] (for forking)
„Niemals! Das verbietet die wissenschaftliche Integrität!“
[Quarks & Co., 2013-06-04]
Vertrauen in andere durch saubere Veröffentlichungen.
Vertrauen in die eigene Veröffentlichung.
#+BEGIN_SRC python import pylab data = pylab.genfromtxt( "data.txt") pylab.plot(data) pylab.savefig( "image.png") print "#+caption: desc" print "[[./image.png]]" #+END_src
autoreconf -i && \ ./configure && \ make distcheck
→ repro-pub-0.1.tar.gz (repro-pub-0.5.0.tar.gz [97])
Versuchsaufbau exakt beschreiben.
Bitte stellen Sie Ihre Fragen
arne.babenhauserheide@kit.edu oder arne_bab@web.de
dnl run `autoreconf -i` to generate a configure script. dnl Then run ./configure to generate a Makefile. dnl Finally run make to generate the project. AC_INIT([Repro Pub], [0.5.0], [arne.babenhauserheide@kit.edu]) # Check for programs I need for my build AC_CANONICAL_TARGET AC_ARG_VAR([emacs], [How to call Emacs.]) AC_CHECK_TARGET_TOOL([emacs], [emacs], [no]) AS_IF([test "x$emacs" = "xno"], [AC_MSG_ERROR([cannot find Emacs.])]) # Run automake AM_INIT_AUTOMAKE([foreign]) AM_MAINTAINER_MODE([enable]) AC_CONFIG_FILES([Makefile]) AC_OUTPUT
# basic definitions vortrag = vortrag.pdf vortrag_DATA = vortrag.org data.txt dist-tarball.png vortragdir = . # dist_pkgdata_DATA = rohdaten EXTRA_DIST = ${vortrag_DATA} ${vortrag} # kill editor backups and latex stuff MOSTLYCLEANFILES = \\\#* *~ *.bak *.vrb *.bbl \ *.blg *_flymake.* CLEANFILES = ${vortrag} DISTCLEANFILES = ${CLEANFILES} \\\#* *~ *.bak *.vrb *.bbl \ *.blg *_flymake.* auto/*el all : ${vortrag}
# emacs org-mode beamer build instructions ${vortrag} : ${vortrag_DATA} if test "$<" != "$(notdir $<)"; then \ cp -u "$<" "$(notdir $<)"; fi echo yes | @emacs@ --batch --load "~/.emacs" \ --visit "$(notdir $<)" \ --funcall org-beamer-export-to-pdf if test "$<" != "$(notdir $<)"; \ then rm -f "$(notdir $<)"; \ rm -f $(basename $(notdir $<)).tex \ $(basename $(notdir $<)).tex~ \ auto/$(basename $(notdir $<)).el; \ else rm -f $(basename $<).tex \ $(basename $<).tex~ \ auto/$(basename $<).el; \ fi
Gerade haben Biologen gezeigt3, dass die Verfügbarkeit der Rohdaten von alten Veröffentlichungen jedes Jahr um 17% fällt. Das heißt, schon nach 4 Jahren gibt es für die Hälfte der Veröffentlichungen keine Daten mehr. Die hier gezeigte Methode macht es sehr einfach sicherzustellen, dass alle für die Veröffentlichung notwendigen Daten mitveröffentlicht werden - und erzeugt automatisch eine Archivdatei dafür. ↩
Leider ist die durch die politisch gesetzten Rahmenbedingungen erzwungene Konkurrenzsituation für reproduzierbare Veröffentlichungen hinderlich, denn wer seine Daten und Skripte veröffentlicht - eigentlich alle Programme, die er oder sie nutzte - verspielt die Möglichkeit, sich ein Monopol auf die Daten aufzubauen, das die nächsten Veröffentlichungen sichern könnte. Sobald die Daten draußen sind, können andere damit arbeiten - und nur die schnellsten können veröffentlichen (ja, das System ist dumm…). Zusätzlich stehen sauberer Veröffentlichung oft „IP“-Regeln entgegen - also der Wunsch der Uni, ihre Ergebnisse zu monopolisieren. Zum Glück gibt es mit Open Access inzwischen eine Bewegung gegen solche schädlichen Regelungen - aber der Kampf wird wohl noch lange andauern. Immerhin stehen hier Misstrauen, Gier und leider berechtigte Sorgen um die eigene Zukunft gegen wissenschaftliche Integrität. ↩
The Availability of Research Data Declines Rapidly with Article Age [105] - Zeitungsartikel dazu: The Vast Majority of Raw Data From Old Scientific Studies May Now Be Missing [106]. ↩
| Anhang | Größe |
|---|---|
| repro-pub-0.5.0.pdf [96] | 229.72 KB |
| repro-pub-0.5.0.org [98] | 7.4 KB |
| repro-pub-thumb-0.5.0.png [107] | 16.88 KB |
| repro-pub-0.5.0.tar_.gz [97] | 354.19 KB |
| dist-tarball.png [108] | 47.6 KB |
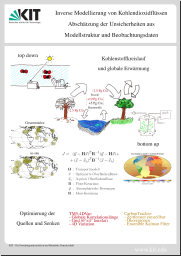
Am 15. Januar 2016 habe ich meine Doktorarbeit [109] verteidigt. Ich habe dafür Poster verwendet und keine Folien, obwohl die Strukturierung des Vortrags mit Postern eine größere Herausforderung ist.
Gewählt habe ich die Poster, weil ich damit besser auf vorherige Inhalte zurückverweisen konnte. Das passt eher zu meinem Rollenspiel [110]- und Mind-Map-geprägten Vortragsstil und ich kann das Verständnis der Zuhörenden über Fixpunkte strukturieren, die die ganze Zeit sichtbar bleiben. Außerdem wollte ich die Herausforderung. Das hier sind meine Poster:
 [111]
[111] 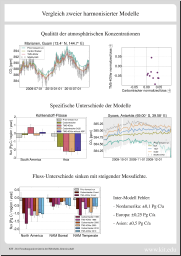 [112]
[112]  [113]
[113]
Erstellt habe ich die Poster mit Scribus [114]. Das KIT-Logo ist ein eingetragenes Markenzeichen des Karlsruher Institutes für Technologie [115], wo ich meine Doktorarbeit gemacht und erfolgreich verteidigt habe, muss also wahrscheinlich für Weiternutzung der Poster entfernt werden.
Die Scribus-Quellen ohne das KIT-Logo gibt es in der Archivdatei phd-verteidigung-arne-babenhauserheide-2016-01-15.tgz [116].
Viele der Darstellungen wurden vorher bereits verwendet: In dem Papier „Comparing the CarbonTracker and TM5-4DVar data assimilation systems for CO2 surface flux inversions“ [117] (Autoren: A. Babenhauserheide, S. Basu, S. Houweling, W. Peters and A. Butz, Lizenz creativecommons attribution [118]) oder in meiner Doktorarbeit „Inverse modelling of carbon dioxide surface fluxes - estimating uncertainties due to model design and observational constraints“ [109] (auch cc by [118]).
Ich habe am 21.4.2009 mit Stephan Flock einen Seminarvortrag zum Elektronik-Versuch (E01) des Fortgeschrittenen-Praktikums der Uni Heidelberg gehalten.
Mein Teil war dabei die Theorie, und ich habe mich entschieden, im Theorieteil das dranzubringen, was im Praktikum wirklich wichtig war: Was haben wir?, Wie können wir das kombinieren? und Wie können wir das prüfen?, dazu noch eine Beispiel-Dimensionierung.
Anmerkung: Die Präsentation des Theorieteils dauert etwas zu lang (30 min statt 20min) und ich habe die Ergebnisse rausgelassen (unklare Urheberrechtslage). Diese Präsentation ist damit unvollständig, aber wenn ich etwas auf meiner Seite veröffentliche, sollte die Lizensierung passen (frei sein).
Viel Spaß beim Lesen!
PS: Alle Quelldaten des Praktikums sind in einem Mercurial-Repository [120] verfügbar. Die zip-Datei im Anhang enthält die Version aus der das PDF erstellt wurde.
PPS: Der Vortrag und alle enthaltenen Dateien sind unter der GPLv3 or later und einigen anderen freien Lizenzen [21] freigegeben.
| Anhang | Größe |
|---|---|
| Elektronik.pdf [121] | 6.18 MB |
| Elektronik.zip [122] | 10.35 MB |
Es gibt immer mal wieder Leute, die sagen „unser Universum könnte gar nicht nur durch Zufall so entstanden sein. Es gibt so viele Möglichkeiten, wie es funktionieren könnte. Die Wahrscheinlichkeit, dass die Gesetze so sind, dass wir darin leben können, ist so gering, dass es gar kein Zufall sein kann“.
Sie machen dabei einen ganz einfachen Fehler: Sie vergessen, dass wir dieses Universum beobachten, und dass daher die Wahrscheinlichkeit genau 1 ist, dass das beobachtete Universum auf Grundlagen aufbaut, die unser Leben ermöglichen.
Eine richtige Argumentation ist: „Wenn ich tief unter Wasser nur in einem U-Boot überleben kann, dann ist die Wahrscheinlichkeit, dass ich in einem U-Boot bin, während ich mir das Meer anschaue, eben genau 1: Wäre ich nicht in dem U-Boot, dann könnte ich das Meer nicht beobachten (denn ich würde nicht leben)“.
Die falsche Argumentation ist: „Die Wahrscheinlichkeit, dass irgendjemand in einem U-Boot ist, und nicht irgendwo anders in dem riesigen Ozean, ist so gering, dass alleine die Tatsache, dass er in einem U-Boot ist, bedeutet, dass die ganze Welt kein Zufall sein kann“.
Um das noch genauer zu widerlegen: Wenn auf diesem U-Boot ein Brot anfängt zu schimmeln, heißt das nicht, dass das U-Boot für den Schimmel gemacht wurde. Es war nur der einzige Ort (in der Nähe), an dem eine Brotschimmel-Kolonie ihre Existenz beginnen konnte, daher ist die Umgebung, die ein Brotschimmel in dem Beispiel-Meer vorfindet, mit absoluter Sicherheit das U-Boot (wenn jetzt jemand sagt „aber es gibt doch Schimmel, der im Meer leben kann“: Ich meine den anderen Schimmel, der das nicht kann). Es gab dann nicht zwingend einen Schimmelgott, der das U-Boot so geschaffen hat, dass es dem Schimmel alles bietet, das er zum Leben braucht.
Ein Schimmel kann das U-Boot nur beobachten, wenn das Boot seiner Existenz zuträglich ist, daher ist jede Umgebung, von der aus irgendein Schimmel irgendetwas beobachten kann, der Existenz des Schimmels zuträglich. Das ändert aber nichts daran, dass es sehr viele Orte gibt, an denen kein Schimmel existieren oder entstehen kann.
Dass wir hier leben können sagt nichts darüber aus, ob es einen Gott gibt. Denn wenn wir von einem Ort aus beobachten, bedeutet das automatisch, dass wir an diesem Ort leben können, sonst könnten wir von dort aus nicht beobachten.
Anders gesagt: Ja, unsere Existenz kann einfach ein riesengroßer Zufall sein (was uns zur Physik zurückbringt). Und das ist gut so. Wir müssen die Entstehung von Leben nicht als zwingende Bedingung an ein Universum stellen. Es genügt, dass Leben entstehen kann. Den Rest übernimmt einfache Logik: Leben wird immer in einem Universum sein, in dem es entstehen konnte → Auswahlkriterium der Universen, die von Leben beobachtet werden können.
Darko Dubravica [123] erklärt die Ergebnisse seiner Arbeit (die Verringerung des Residuums1 ist Wahnsinn!).
[124]
(anklicken für die große Version [124], Quelle: darko-dubravica-hitran-bw.svg [125]. Frei lizensiert unter der GPL [126] (wie fast alles hier [21]))
Gezeichnet mit Kugelschreiber [127], in SVG [125] umgewandelt mit Inkscape [128] (manuell 3 Helligkeitsstufen gewählt), dann als PNG [124] exportiert.
Der Dank für die Inspiration zu diesem skizzierten Mitschrieb geht an Sacha Chua und ihre Sketched Books [129], auch wenn meine Zeichnungen noch weit von deren Qualität entfernt sind ☺
Außerdem hilft das besser gegen Müdigkeit als Kaffee - und ich verstehe beim Mitskizzieren die Kernaussage des Vortrags oft besser als wenn ich nur zuhöre.
Danke auch an Darko, der mir erlaubt hat, die Zeichnung online zu stellen!
PS: Den Titel habe ich gewählt, weil er in der Zeichnung aussieht, wie ein legendärer russischer Wissenschaftler des 19-ten Jahrhunderts (z.B. Ivan Pavlov [130]). Außerdem ist die Arbeit, die er macht, fast schon klassisch: Komplexe Mathematik gefolgt von monatelanger geduldiger Kleinarbeit.
| Anhang | Größe |
|---|---|
| darko-dubravica-hitranbw.png [124] | 3.62 MB |
| darko-dubravica-hitran-bw.svg [125] | 10.84 MB |
| darko-dubravica-hitran-bw-klein.png [131] | 161.41 KB |
| darko-dubravica-hitran-20140718151636982_0001.jpg [127] | 641.59 KB |
Links:
[1] https://www.draketo.de/licht/freie-software
[2] https://www.draketo.de/english/free-software
[3] http://dx.doi.org/10.5445/IR/1000052678
[4] http://www.imk-asf.kit.edu/
[5] http://www.pfiffiges-spielzeug.de/
[6] http://www.math.uni-heidelberg.de/logic/SS07/thinf_SS07.html
[7] http://www.rzuser.uni-heidelberg.de/~q61/ed.html
[8] http://www.thphys.uni-heidelberg.de/~pawlowsk/
[9] https://www.draketo.de/stichwort/filk
[10] http://bewegung.taz.de/aktionen/umweltdialog-03/beschreibung
[11] http://berkeleyearth.org
[12] http://www.esrl.noaa.gov/
[13] http://www.giss.nasa.gov/
[14] http://www.cru.uea.ac.uk/
[15] http://berkeleyearth.org/summary-of-findings
[16] http://berkeleyearth.org/videos/
[17] https://www.draketo.de/licht/physik/kohlenstoffkreislauf-carbon-cycle
[18] https://www.draketo.de/files/carbon-cycle-free.pdf
[19] http://www.globalfiredata.org/
[20] https://www.draketo.de/licenses
[21] https://www.draketo.de/lizenzen
[22] https://www.draketo.de/files/carbon-cycle-free.odp
[23] http://de.libreoffice.org/
[24] https://www.draketo.de/files/cc-bilder.zip
[25] http://wesnoth.org
[26] https://www.draketo.de/files/cc-preview.png
[27] https://www.draketo.de/files/wissenschaftliche-methode_0.dot
[28] http://www.spektrum.de/astrowissen/wissen.html
[29] https://www.draketo.de/light/english/scientific-method-140-characters
[30] https://www.draketo.de/files/wissenschaftliche-methode.dot
[31] https://www.draketo.de/files/wissenschaftliche-methode.png
[32] https://www.draketo.de/files/wissenschaftliche-methode_0.png
[33] https://www.draketo.de/deutsch/lieder/licht/studier-im-rhythmus
[34] http://bah.draketo.de
[35] http://draketo.de
[36] http://de.wikipedia.org/wiki/Grenzwert_(Funktion)
[37] http://www.atmos-chem-phys.net/15/9747/2015/acp-15-9747-2015.html
[38] https://www.draketo.de/files/flux-histobs-flux-ct-t4d-alternating-nam.pdf
[39] http://creativecommons.org/licenses/by/3.0/
[40] http://www.atmos-chem-phys-discuss.net/15/8883/2015/acpd-15-8883-2015.html
[41] https://www.draketo.de/files/randomsets-case-resampling-ctvst4d-5x7-5x20.pdf
[42] http://www.esrl.noaa.gov/gmd/ccgg/carbontracker/
[43] http://krol.synology.me/~tm5/4d-var/
[44] http://www.rug.nl/staff/w.peters/
[45] http://www.pnas.org/content/104/48/18925.long
[46] http://krol.synology.me/~tm5/about-tm5/
[47] http://www.uu.nl/staff/SHouweling/0
[48] http://www.atmos-chem-phys.net/13/8695/2013/acp-13-8695-2013.html
[49] http://splasho.com/upgoer5/?i=I2HtoTI0VUEbnJ5eYJWirTImVTElMJSgVUE3olOxpzIuoKZtp3EupaEcozptMaWioFO0nTHtp2SgMFOcMTIupjcbo3ptoKIwnPOuozygLJjgLaWyLKEbVUqyVTAuovOznJ5xVTyhVUEbMFOunKVtLKDXoTImplO0nTShVT9hMFObqJ5xpzIxVUOfLJAyplOcovO0nTHtq29loTDtLJ5xVUqbMKWyVTShnJ1uoP1vpzIuqTttL291oTDtM28tqT8tLJ5xVUqbMKWyVTy0VTAiqJkxVTAioJHtMaWioF4XPyEbMFOxpzIuoKZto2LtqTuyVUEbnJ5eYJWirTImVUAyLKWwnPOzo3VtozI3VTyxMJSmVUqbMKWyVTShnJ1uoP1vpzIuqTttL291oTDtL29gMFOzpz9gPzShMPO3nTIlMFOcqPOwo3IfMPOaolO0ol4XPyEiVTMcozDto3I0VTuiqlOao29xVUEbMFOxpzIuoKZtMzy0VUEbMFOlMJSfVUqipzkxVUqyVTkio2ftnT93PzEcMzMypzIhqPO0nTI5VTSlMFOzpz9gVUOfLJAyplO3nTIlMFO3MFOeoz93VTuiqlOgqJAbVTShnJ1uoNcvpzIuqTttnKZtnJ4tqTuyVTScpvO3nTywnPO3MFOxnJDtoz90VUEyoTjtqTuyVUEbnJ5eYJWirTImVTSvo3I0PaqbMJ4tqTuyrFOmqTSlqTIxVUEiVTElMJSgYtbXITuyovO3MFOfo29eVUqbMKWyVUEbMFOxpzIuoKZtLKWyVTEcMzMypzIhqPO0olOaMKDtLJ4tnJEyLFObo3pXL2kip2HtqTuyrFOupzHtqT8tqTuyVUWyLJjtq29loTDhVSEbnKZtnJEyLFOcplOho3DtqTuyVUWyLJjtq29loTDXLaI0VTy0VUEyoTkmVUImVTuiqlOxnJMzMKWyoaDtqTuyVUWyLJjtq29loTDtL2ShVTWyVTMlo20tqTuyPzElMJSgpl4XPyqyVTMcozDtqTuuqPO0nTHtMUWyLJ1mVTSlMFOmolOwoT9mMFO0olOyLJAbVT90nTIlVUEbLKDtq2HtL2ShPz5iqPOmLKxtq2ucL2tto25yVTymVTWyqUEypv4XPyqyVTSfp28tMzyhMPO0nTS0VUqyVTEiVT5iqPOeoz93VUqbMKEbMKVtqTuyVT9fMPO3o3WfMPOcplOuVUOfLJAyPaqbMKWyVTShnJ1uoP1vpzIuqTttM29yplO0olOipvO3nTIlMFOcqPOwo21yplOzpz9gYtbXDaI0VUqyVUAyMFO0nTS0VUqbMJ4tq2Htq291oTDtnTS2MFOuplOgLJ55VUOfLJAyplO3nTywnPOfo29eVTS0PzShnJ1uoP1vpzIuqTttLKDtMKMypaxtpTkuL2HtnJ4tqTuyVUqipzkxVTSmVTyhVUEbMFOhMKptq29loTDfPaEbMJ4tq2HtL291oTDtn25iqlOuLz91qPO0nTHto2kxVUqipzkxYPO0o28hVRShMPO0olOznJ5xVT91qPOzo3VXp21uoTkypvOjoTSwMKZtq2uyqTuypvOuozygLJjgLaWyLKEbVTqiMKZtqTuypzHto3Vtq2uyqTuypvOcqNcwo21yplOzpz9gVUEbMKWyYPO3MFOiozk5VT5yMJDtqT8tp3EupaDtoJ9lMFOjoTSwMKZtq2uypzHtq2HXq2S0L2ttLJ5coJSfYJWlMJS0nP4XPyE3MJ50rFOhMKptpTkuL2ImVUAbo3IfMPOuoTkiqlO1ozEypaA0LJ5xnJ5aVUEbMFOioTDtq29loTDtq2IfoNcyoz91M2ttqTuuqPO3MFO3o3IfMPOmMJHtnKDtq2uyovOcqUZtq29iMUZtq291oTDtqTSeMFO1pPOiozk5PzuuoTLtLKZtoKIwnPOuozygLJjtLaWyLKEbVTSmVUEbMFO5MJSlVTWyMz9lMF4XPxShMPO0nTS0VTymVUqbLKDtFFOxnJDtMz9lVUEbpzIyVUyyLKWmBvOTnJ5xnJ5aVT91qPObo3ptq2IfoPO3MDceoz93VUqbMKWyVTShnJ1uoP1vpzIuqTttL29gMKZtMaWioFOuozDtM29yplO0ol4XPv0gYF0gYDbXITucplOcplO3nTS0VRxtMT8tMz9lVUqipzf6PtcWVUEyoTjtqTucozfgLz94MKZtnT93VUEiVTMcozDto3I0VUqbMKWyVTShnJ1uoP1vpzIuqTttq2ucL2ttq2HtL2ShVUAyMDccovO0nTHtLJylVTAioJImVTMlo20tLJ5xVTqiMKZtqT8hPtcHnTS0VTShnJ1uoP1vpzIuqTttq2SloKZto3IlVUqipzkxVTWyL2S1p2HtnKDtnT9fMUZtq2SloJyhMlOfnJqbqPOxo3qhPaqbnJAbVUEbMFOapz91ozDtp2IhMUZtqKNtLKqurF4tFKDtMT9yplOho3Dto25frFOwo21yVTMlo20tLJ5coJSfpljtLaI0PzSfp28tMaWioFOvqKWhnJ5aVUEbnJ5aplO3nTywnPO3MFOvpzyhMlOiqKDtMaWioFO0nTHtM3WiqJ5xVUqbMKWyVUEbMKxXnTSxVUWyp3EyMP4XPyqyVTAuovOmMJHtnT93VT11L2tto2LtqTuuqPOuozygLJjgLaWyLKEbVTymVTyhVUEbMFOunKVtLKDtqTuyVT1ioJIhqPjXLaI0VT9hoUxto24tqTuyVTqlo3IhMPOuqPO2MKW5VTMyqlOjoTSwMKZto3VtMaWioFObnJqbVUIjVUqcqTttoKIwnNc3pz9hMl1vMJyhMl4XPyEiVTMcozDto3I0VUqbMKWyVTy0VTAioJImVTMlo20fVRxtqTIfoPO0nTHtqTucozfgLz94MKZtqT8tMUWyLJ0toJShrDcxnJMzMKWyoaDtMUWyLJ1mYvOHnTI5VTElMJSgVUqbMKWyVUEbMFOuozygLJjgLaWyLKEbVTAiqJkxVTAioJHtMaWioFOuozDXnT93VT11L2tto2LtnKDtq2Htq291oTDtp2IyVPOcMvO0nTHtMUWyLJ0tq2IlMFO0paIyVTS0VUEbMFOjoTSwMKZtnJ4tqTuyPaqipzkxVTS0VUqbnJAbVUqyVTgho3ptnT93VT11L2ttqTuypzHtpzIuoTk5VTymYvOHnTIhVUEbMKxtL2uuozqyVUEbMDcxpzIuoKZtqT8toJSeMFObo3ptoKIwnPOuozygLJjgLaWyLKEbVUEbMFOxpzIuoKZtp2IyVTMcqPOvMKE0MKVtq2uuqPO3MDcmMJHtnJ4tqTuyVUWyLJjtq29loTDhPtcOozDtq2uyovO0nTHtMUWyLJ1mVTSapzIyVUqcqTttq2uuqPO3MFOmMJHtnJ4tqTuyVUWyLJjtq29loTDfVUqyVUEbnJ5ePaEbLKDtq2uuqPO0nTHtMUWyLJ1mVUAurFO3nTIlMFO0nTHtLJ5coJSfYJWlMJS0nPOwo21yplOzpz9gVTShMPOao2ImVUEiPzymVTAfo3AyVUEiVUqbMKWyVTy0VTAioJImVTMlo20tnJ4tqTuyVUWyLJjtq29loTDhPtcOozDtqTuuqPOcplO3nTS0VRxtq2ShqPO0olOznJ5xVT91qQbtFFO0paxtqT8toTIupz4tq2uypzHtLJ5coJSfYJWlMJS0nNcwo21yplOzpz9gVTShMPO3nTIlMFOcqPOao2ImYt==
[50] https://www.draketo.de/deutsch/freenet
[51] http://de.wikipedia.org/wiki/Normalverteilung
[52] http://de.wikipedia.org/wiki/Poisson-Verteilung
[53] https://www.draketo.de/files/flux-histobs-flux-ct-t4d-alternating-nam.png
[54] https://www.draketo.de/files/randomsets-case-resampling-ctvst4d-5x7-5x20.png
[55] http://draketo.de/comment/reply/145#comment-form
[56] http://de.gentoo-wiki.com/Screen_Tutorial
[57] http://nobelprize.org
[58] http://www.nobelprize.org/nobel_prizes/physics/laureates/
[59] http://www.kit.edu/kit/7894.php
[60] http://www.nobelprize.org/nobel_prizes/physics/laureates/1993/
[61] https://www.draketo.de/files/2013-10-17-Do-yin-day-podiumsdiskussion-wagner-hippler-loehe-porth-zensiert.pdf
[62] http://www.kit.edu/besuchen/pi_2013_14050.php
[63] https://www.xing.com/profiles/Heike_Mund3/
[64] http://i11www.iti.uni-karlsruhe.de/members/dorothea_wagner/index
[65] http://www.hrk.de/hrk/gremien/praesidium/horst-hippler/
[66] http://www.kit.edu/ps/vp-for-info.php
[67] http://www.daimler.com/dccom/0-5-78470-49-1169771-1-0-0-0-0-0-19522-0-0-0-0-0-0-0-0.html
[68] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-wagner-hippler-loehe-porth-mund-seite1-zensiert.jpeg
[69] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-wagner-hippler-loehe-porth-mund-seite2-zensiert.jpeg
[70] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-wagner-hippler-loehe-porth-mund-seite3-zensiert.jpeg
[71] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-skizze-hippler.png
[72] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-skizze-loehe.png
[73] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-skizze-porth.png
[74] https://www.draketo.de/files/2013-10-12-Notizen-zur-Podiumsdiskussion-auf-dem-YIN-day-2013-skizze-wagner.png
[75] http://www.esa.int/spaceinimages/Images/2014/11/Farewell_Philae_-_narrow-angle_view
[76] http://www.esa.int/Our_Activities/Space_Science/Rosetta/Europe_s_comet_chaser
[77] http://xkcd1446.org
[78] https://twitter.com/Philae2014
[79] https://twitter.com/hashtag/CometLanding?src=hash
[80] http://t.co/OXJwGunL3V
[81] https://twitter.com/ESA_Rosetta/status/532537918557265921
[82] https://twitter.com/ESA_Rosetta
[83] http://t.co/DjU0J1Ey4H
[84] https://twitter.com/Philae2014/status/532547743206875136
[85] https://twitter.com/hashtag/67P?src=hash
[86] http://t.co/b6mcid2fsn
[87] https://twitter.com/Philae2014/status/532593337585651713
[88] https://twitter.com/Philae2014/status/532579550069551104
[89] http://mediathek.daserste.de/ARD-Sondersendung/Mission-Rosetta-Auf-der-Suche-nach-dem/Das-Erste/Video?documentId=24687834&topRessort=tv&bcastId=3304234
[90] http://media.tagesschau.de/video/2014/1112/TV-20141112-2325-2701.websm.h264.mp4
[91] https://www.draketo.de/english/ambition-film
[92] http://www.esa.int/spaceinimages/ESA_Multimedia/Copyright_Notice_Images
[93] http://freedomdefined.org/Definition/De
[94] http://curia.europa.eu/juris/document/document.jsf?text=&docid=143224&pageIndex=0&doclang=EN&mode=lst&dir=&occ=first&part=1&cid=480769
[95] https://www.draketo.de/english/emacs/writing-papers-in-org-mode-acpd
[96] https://www.draketo.de/files/repro-pub-0.5.0.pdf
[97] https://www.draketo.de/files/repro-pub-0.5.0.tar_.gz
[98] https://www.draketo.de/files/repro-pub-0.5.0.org
[99] https://www.draketo.de/proj/repro-pub
[100] http://gnu.org/s/emacs
[101] http://orgmode.org
[102] http://gnu.org/software/autoconf/
[103] http://gnu.org/software/automake/
[104] http://draketo.de/light/english/free-software/makefile-to-autotools
[105] http://www.cell.com/current-biology/retrieve/pii/S0960982213014000
[106] http://blogs.smithsonianmag.com/science/2013/12/the-vast-majority-of-raw-data-from-old-scientific-studies-may-now-be-missing/
[107] https://www.draketo.de/files/repro-pub-thumb-0.5.0.png
[108] https://www.draketo.de/files/dist-tarball.png
[109] https://publikationen.bibliothek.kit.edu/1000052678
[110] https://www.draketo.de/deutsch/rpg
[111] https://www.draketo.de/files/vortrag-seite1.pdf
[112] https://www.draketo.de/files/vortrag-seite2.pdf
[113] https://www.draketo.de/files/vortrag-seite3.pdf
[114] http://scribus.net
[115] http://kit.edu
[116] https://www.draketo.de/files/phd-verteidigung-arne-babenhauserheide-2016-01-15.tgz
[117] https://www.atmos-chem-phys.net/15/9747/2015/
[118] https://creativecommons.org/licenses/by/4.0/
[119] http://draketo.de/files/Elektronik.pdf
[120] http://bitbucket.org/ArneBab/physik_fp_hd-seminarvortrag_elektronik/
[121] https://www.draketo.de/files/Elektronik.pdf
[122] https://www.draketo.de/files/a23aebb967db.zip
[123] http://www.imk-asf.kit.edu/mitarbeiter_1784.php
[124] https://www.draketo.de/files/darko-dubravica-hitranbw.png
[125] https://www.draketo.de/files/darko-dubravica-hitran-bw.svg
[126] http://gnu.org/l/gpl
[127] https://www.draketo.de/files/darko-dubravica-hitran-20140718151636982_0001.jpg
[128] http://inkscape.org
[129] http://sachachua.com/blog/sketched-books/
[130] http://commons.wikimedia.org/wiki/File:Ivan-Pavlov09.jpg
[131] https://www.draketo.de/files/darko-dubravica-hitran-bw-klein.png

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
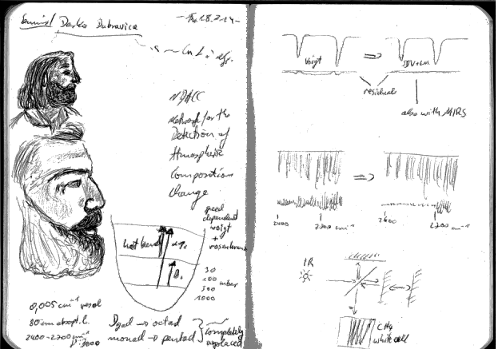{kind=link}