„Frei, Robust, Ethisch und Innovativ”
„Free, Reliable, Ethical and Efficient“
„Libre, Inagotable, Bravo, Racional y Encantado“
- Akronym zu freier Software [1].
Ich bin seit nun 2004 glücklicher Nutzer von GNU/Linux und anderer freier Software, und die Philosophie freier Software ist für mich ein wichtiges Standbein unserer Gesellschaft.
Sie verteidigt vier grundlegende Freiheiten:
Übrigens habe ich auch ein paar Lieder über freie Software unter meinen englischen Liedern [5]. Hört doch mal rein!
Auf Free Software [6] sammle ich meine englischen Artikel.
Gerade hat eine Gruppe kleiner Spielehersteller durch das Humble Indie Bundle [7] mit dem „Zahl soviel du willst“ Modell in nur einer Woche eine Million Dollar verdient [8] – und veröffentlichen jetzt von vieren der Spiele den Quellcode als freie Software.
Sie zeigen damit deutlich, welche neuen Möglichkeiten das Internet bietet, wenn man es schafft, andere für sein Projekt zu begeistern.
Jeder Käufer konnte frei wählen, wie viel er zahlen will, von einem Cent ausgehend und nach oben offen. Außerdem konnte jeder Käufer festlegen, wie viel von dem Geld die Entwickler kriegen und wie viel an gemeinnützige Organisationen gespendet wird.
Gleichzeitig hatten sie auf ihren Seiten Echtzeitstatistiken, wie viel Geld sie bereits verdient haben, aufgeschlüsselt nach dem Durchschnittsbetrag je Nutzergruppe (Windows, MacOSX, GNU/Linux).
Und alleine die letzten 19 Stunden brachten ihnen 200,000$ [9] – nachdem sie gesagt hatten, dass sie, wenn sie die eine Million Dollar Grenze knacken, den Quellcode von dreien der Spiele veröffentlichen würden.
Eine weitere Besonderheit, und vielleicht einer der zentralen Punkte ihres Erfolges: Sie liefen alle sowohl auf Windows als auch auf MacOSX und GNU/Linux. Und waren natürlich ohne DRM.
Meine tiefsten Glückwünsche!
Updates:
Lugaru [10] wurde gerade als freie Software unter der GPL veröffentlicht [11] (allerdings nur der Quellcode – die Mediendaten dürfen weitergegeben aber nicht verkauft werden) und hat schon einen Tag später die ersten Patches gekriegt [12].
Ich habe eine englische Betrachtung dazu geschrieben, was die Entwickler bei dem Humble Indie Bundle alles richtig gemacht haben: How to make a million dollars in pay-what-you-want — thoughts on the Humble Indie Bundle [13]
Codeswarms [14] sind eine Methode, die Entwicklung von Programmen zu visualisieren.
Genauer: Mit ihnen lassen sich commits in Quellcode-Repositories visualisieren.
Was dabei rauskommt sieht dann in etwa so aus, nur als Film:

Ich bin ihnen inzwischen seit Monaten völlig verfallen, weil ich in einem Codeswarm nicht nur nachvollziehen, sondern sehen und fühlen kann, wie sich ein Programm entwickelt hat.
Fragen wie
und viele mehr beantworten sich wie von selbst in schönen Filmen.
Aber was mir mit am Besten gefällt:
Mit Codeswarm werden Coder Rockstars.
Wenn das jetzt weit her geholt klingt, dann schau dir mal einen Codeswarm an und beobachte, wie du die Coder davor und danach siehst.
Probier' das doch mal mit den folgenden:
Um eigene codeswarms zu erstellen, schau mal auf der Video Seite [17] von codeswarm vorbei.
Einige von meinen drehen sich um den GNU/Hurd [18]:
Außerdem habe ich das Projekt shared_codeswarm [20] gestartet, mit dem sich code_swarms aus verschiedenen Projekten einfach zusammenfassen lassen. Eine schöne Anwendung davon sind battle_swarms und der unregelmäßig aktualisierte Mercurial code_swarm:
Viel Spaß beim Schauen!
Jetzt bräuchte ich nur noch einen Großrechner und Subversion Zugriff auf alle freien Programme, und ich könnte einen "Free Software Liveswarm" erstellen: Einen Videofeed in dem man in Echtzeit beobachten kann, wie sich freie Software weiterentwickelt.
Ich denke, irgendwann wird es das oder etwas in der Art geben, mit dem wir zu jeder Zeit sehen, was gerade in unserem Code-Universum geschieht.
Update (2015-10-08): Mit der Kompatibilität von BY-SA in Richtung GPLv3 [23] ändert sich die Grundlage dieses Artikels. Wenn die veröffentlichte Datei deines Werkes auch die ist, die du als Grundlage für Änderungen nehmen würdest, ist die CC BY-SA Lizenz jetzt die sinnvollste Wahl für freie Kunst, weil sie niedrigere Hürden für deren Veröffentlichung hat.
Ich will alle zukünftigen Adaptionen meiner Werke mit all meinen anderen Werken nutzen können (nicht nur dürfen, sondern die praktische Möglichkeit dazu haben).
Viele reden jetzt über Creative Commons, aber für die Belange freier Kultur sind sie gefährlich unsicher, wenn du kommerzielle Nutzung erlauben willst (bei den nichtkommerziellen fällt die Gefahr weg, sie bringen für freie Werke aber ganz eigene Probleme).
Anmerkung (2014-09-05): Sollte die cc by-sa kompatibel mit der GPL werden, werde ich diese Haltung überdenken, da ich damit Anpassungen meiner Werke immer sichern kann, falls jemand die Schwächen der cc by-sa ausnutzt, solange das aber nicht passiert, können andere meine Werke mit mehr anderen Werken kombinieren.
Meine Bedingung an eine freie Lizenz ist: Ich will alle zukünftigen Adaptionen meiner Werke mit all meinen anderen Werken nutzen können (nicht nur dürfen, sondern die praktische Möglichkeit dazu haben). Da Programme die GPL brauchen und ich gerne Programmiere, müssen alle Lizenzen, die ich verwende, Copyleft und GPL-kompatibel sein. Zur Zeit trifft das nur auf die GPL zu, aber das könnte sich bald ändern [24].
Die Ausnahme der Regel ist die cc-GPL [25]. Sie ist sicher, da sie direkt die normale GPL v2 or later [26] mit ein paar Bildern ist.
Mein Grund dafür, dass CC-Lizenzen bei mir nicht in Frage kommen ist, dass nach meinem Verständnis die einzige "Sicherung" des Quelltextes das folgende ist:
"(IV) when You Distribute or Publicly Perform the Adaptation, You may not impose any effective technological measures on the Adaptation that restrict the ability of a recipient of the Adaptation from You to exercise the rights granted to that recipient under the terms of the Applicable License." - Das ist aus der neusten Version: http://creativecommons.org/licenses/by-sa/3.0/legalcode
Das heißt: Ich darf nicht extra beschränken, aber wenn es Teil meiner Leistung ist, dass es als 32kB/s Radiostream kommt, muss ich auch keine bessere Version vorhalten, und Liedtexte oder ähnliches sind auch nicht enthalten, selbst wenn ich sie geändert habe.
Das heißt auch, ich kann einen cc-by-sa Text nehmen und in eine Flash Animation packen, die automatisch scrollt und ihn für jegliche Nachnutzer fast unbrauchbar macht, und ich muss den Originaltext nicht rausgeben.
Aus dem Wissenschaftsbereich: Ich kann ein LaTeX-Dokument nehmen, ändern, und es nur als PDF rausgeben (mit shapes statt Buchstaben), und damit muss ich meine Änderungen effektiv nicht mehr freigeben.
Und das ist für eine freie Lizenz inakzeptabel und zeigt für mich, dass bisher der Denkansatz dahinter wohl nicht "Freiheit" ist, sondern "möglichst leichte Anwendbarkeit, auch wenn es langfristig unsicher ist".
Daher: Finger weg von CreativeCommons Lizenzen für freie Werke.
Für freie Werke sollten nur echt freie Lizenzen [27] genutzt werden.
Für unfreie, nur nichtkommerziell nutzbare oder vogelfreie Werke sind CC-Lizenzen sinnvoll, aber die ShareAlike Bedingung ist zu zahnlos um eine echt freie Lizensierung mit CreativeCommons Lizenzen zu ermöglichen.
Anmerkung: Wenn nur nichtkommerzielle Nutzung erlaubt wird ( [28]), ist dieses Problem weniger präsent, weil damit der Anreiz, die Zielsetzung "wer mein Werk nutzt muss auch mir die Nutzung erlauben" zu umgehen deutlich schwächer wird. Dadurch ist das die einzige CC Lizenz, die ich nutzen würde, abgesehen natürlich von CC GPL [29] und CC LGPL [30].
Allerdings ist ein Werk, das nur nichtkommerzielle Nutzung erlaubt per Definition inkompatibel mit freier Software und macht auch auch sonst ein ganz eigenes Fass von Problemen [31] auf. – Arne
[28]), ist dieses Problem weniger präsent, weil damit der Anreiz, die Zielsetzung "wer mein Werk nutzt muss auch mir die Nutzung erlauben" zu umgehen deutlich schwächer wird. Dadurch ist das die einzige CC Lizenz, die ich nutzen würde, abgesehen natürlich von CC GPL [29] und CC LGPL [30].
Allerdings ist ein Werk, das nur nichtkommerzielle Nutzung erlaubt per Definition inkompatibel mit freier Software und macht auch auch sonst ein ganz eigenes Fass von Problemen [31] auf. – Arne
Weitere Info: Warum wir für unser Rollenspiel-Regelwerk (RPG) die GPL statt den cc-Lizenzen oder der GFDL verwenden [32].
Emacs [33] ist ein freies Textbearbeitungsprogramm, das sowohl in der Konsole als auch mit grafischer Oberfläche genutzt werden kann, weitreichende Anpassung via Lisp [34] ermöglicht1 (lisp lernen [35]) und am Anfang der freie Software Bewegung stand (info [36]).
Es gibt ihn für fast alle Betriebssysteme, inklusive vieler exotischer, und er ist einer von zwei Editoren (=Textverarbeitungsprogrammen), um die eine eigene (ironisch gemeinte) Religion entstanden ist2. In Aktion sieht er z.B. so aus:
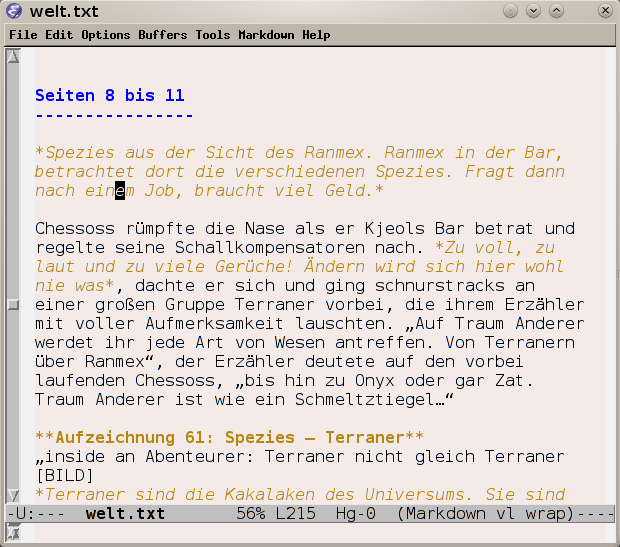
Die Zeile unten ist der Minibuffer, in dem Befehle eingegeben und Ausgaben angezeigt werden können. Das Bild habe ich aus meinem Eintrag Darum Emacs: Markdown mode [37] übernommen.
Hier sammle ich ein paar praktische Resourcen zu Emacs (=Links und Kurznotizen).
Eine Warnung sollte ich dir allerdings nicht vorenthalten: Emacs zu verwenden beinhaltet das Risiko, dass du immer größere Teile deiner Arbeitsabläufe in ihn verlagerst. Er ist inzwischen nicht mehr nur mein Editor, sondern auch LaTeX-IDE (mit grafischer Formelvorschau), Programmierplattform, Zeitplaner (org-mode, und ich kratze erst an der Oberfläche), GnuPG-verschlüsseltes Tagebuch, Darkroom-Schreibprogramm [38], Musikabspieler (emms), identi.ca client und vieles mehr. In emacs zu arbeiten wird Stück für Stück immer natürlicher und irgendwann wirkt alles andere unelegant und einschränkend. Und emacs funktioniert fast überall, selbst in der Text-Konsole und auf Android-Handies [39].
creating custom modes the easy way with generic-mode [40] – Eigene und seltene Dateiformate einfach selbst einbinden.
Rudel [41] – In Echtzeit mit mehreren Leuten an Dokumenten schreiben (übers Netz).
Das beinhaltet Dinge wie ein Mailprogramm oder Webbrowser, transparentes bearbeiten von verschlüsselten Dateien (wie in meinem Tagebuch [42]), Integration von Versionsverwaltungssystemen, Hervorhebung und Vervollständigung von Quellcode und vieles mehr; alles vom Benutzer aktivierbar (teils über die zahlreichen Erweiterungen im Emacs-Wiki [43]), wenn er es braucht, und trotzdem relativ schlank (im Vergleich zu vielen heutigen Texteditoren), ↩
Gemeint ist die „Church of Emacs [44]“. Der andere Editor ist vim [45], und was Features angeht, geben sich beide nichts. Sie haben aber völlig andere Grundannahmen, was Bedienbarkeit angeht3. ↩
Der Grundunterschied ist, dass man in Emacs direkt tippen kann und durch Kurzbefehle auf die verschiedenen Aktionen zugreift (‚Strg-x Strg-s‘ speichert, ‚Strg-x Strg-c‘ beendet), während in Vim (etwas vereinfacht) mit Escape und ‚i‘ zwischen dem Befehlsmodus und dem Tippmodus gewechselt werden kann (‚i‘ bringt einen in den Eingabemodus, ‚Escape :wq‘ speichert und beendet). Dabei ergingen sich Anhänger der beiden Editoren in oft immer weiter zugespitzten Diskussionen, die zu so freundlichen Bezeichnungen wie „Escape-Meta-Alt-Control-Shift“ für Emacs und Aussagen wie „Vim hat zwei Modi: Nur piepsen oder alles zerstören“ geführt haben (was beides eine Spur Wahrheit enthält und wohl nur im Rückblick lustig ist). Welchen von beiden man verwendet ist meist Geschmackssache (ich nutze z.B. meist Emacs). Was natürlich die Benutzer nicht daran hindert, endlos über ihren Geschmack zu streiten :) ↩
Ich habe letztens entdeckt [46], dass es einen Unicode-Modifier zum Durchstreichen gibt. Was lag also näher als eine Funktion zu schreiben, mit der ich in Plain-Text Worte durchstreichen kann?
Zum Glück macht emacs das einfach: Packt das folgende in eure .emacs, dann könnt ihr mit M-x strikethrough den aktuell markierten Text durchstreichen:
(defun strikethrough (start end) (interactive "r") (goto-char (min start end)) (while (< (point) (+ (max start end) (abs (- start end)))) (forward-char) (insert "̶")))
Achtet darauf, die Funktion wirklich zu kopieren. Der Bindestrich ist in Wirklichkeit 0x0336, auch bekannt als COMBINING LONG STROKE OVERLAY, 822, #o1466 oder #x336. Einfach Abtippen klappt also nicht.
Wenn ihr den Strich wirklich von Hand braucht, hilft euch M-x ucs-insert 336.
Solche infos über ein Zeichen gibt euch übrigens M-x describe-key.
Nun zum Test: strike C-SPACE M-b M-x strikethrough.
Viel Spaß mit Emacs [47]!
Ich könnte vieles sagen, das ich an Emacs toll finde, aber ich werde mich hier auf ein einziges Bild beschränken:
Emacs [33] mit Markdown Mode [48] (und visual-line-mode [49]); nur eine seiner kleineren Stärken, aber die, die mich heute gepackt hat.
| Anhang | Größe |
|---|---|
| 2010-03-24-darum-emacs-markdown-mode.png [50] | 84.35 KB |
Das hier funktioniert seit dem Wechsel von web.de auf nur-SSL für mich nicht mehr. Ich habe noch nicht herausgefunden warum. Mein Bug-Report dazu [51].
Die Einrichtung von Emacs zum Verschicken von E-Mails hat mich etwas Zeit gekostet.
Bei web.de funktioniert das hier (EMAIL, NAME und PASSWORT ersetzen):
; email
(setq user-full-name "Arne Babenhauserheide"
mail-from-style 'angles
user-mail-address "EMAIL"
mail-default-reply-to user-mail-address)
(setq user-mail-address "EMAIL")
(setq smtpmail-default-smtp-server
"smtp.web.de")
(setq smtpmail-local-domain nil)
; disable “we now use message mode” warning.
(setq compose-mail-user-agent-warning nil)
(setq compose-mail-user-agent-warnings nil)
(setq message-default-headers "BCC: EMAIL
")
(require 'smtpmail)
; MailMode
(setq send-mail-function
'smtpmail-send-it)
; MessageMode
(setq message-send-mail-function
'message-smtpmail-send-it)
(setq starttls-extra-arguments
'("--insecure" "--verbose"))
(setq smtpmail-auth-credentials
'(("smtp.web.de" 25
"NAME" "PASSWORT")))
(setq smtpmail-default-smtp-server
"smtp.web.de")
(setq smtpmail-smtp-server "smtp.web.de")
(setq smtpmail-smtp-service 25)
Ich verwende nun seit einiger Zeit Emacs als Tagebuchprogramm. Mit ihm komme ich zum ersten Mal wirklich zum schreiben.
Der Aufruf bei mir ist schlicht
tagebuch
Den Grund, dass es für mich mit Emacs funktioniert, sehe ich darin, dass er mir genau das bietet, was ich brauche – und dabei verdammt schnell ist. Was ich brauche:
Verschlüsselung ohne Aufwand (epa-file integriert transparentes GnuPG, also wirklich sichere Verschlüsselung).
Sofort schreiben können (ist direkt bei der Zeile, bei der ich aufgehört habe).
Schnell. Ich will nicht warten müssen, bevor ich tippen kann (geht über eine eigene Initfile, die Codevervollständigung und so rauslässt).
Datum zum Eintrag (geht dank miniscript über „M-x datum“).
(Auch) Auf der (Text-)Konsole. Wenn ich am Systembasteln bin, will ich trotzdem Schreiben können.
Optional Versionsverwaltung (nur für backups; wenn es ein Mercurial repository gibt, speichere ich einen Schnappschuss via C-x v v).
Und wenn ich mal was wo anders nutzen will, kann ich es einfach via emacs rüberkopieren, trotz verschlüsselter Datei. Und es gibt keine temporären Dateien, die ich entschlüsselt rumliegen haben muss.
Und es passt sich der Farbgebung meiner Konsole an :)
(benötigt emacs Version 23.1+ [33])
Meine Einrichtung sieht so aus:
.babrc (alias):
alias tagebuch='/usr/bin/emacs \
-nw --no-init-file --no-site-file \
--load ~/.emacs-init-tagebuch \
~/pfad/zum/Tagebuch.txt.gpg'
Dazu habe ich die Datei ~/.emacs-init-tagebuch [52].
Um deinen eigenen Emacs so zu nutzen (unter GNU/Linux),
~/.bashrc, ~/.emacs-init-tagebuch herunter und ~/.emacs.d/libs/markdown-mode/markdown-mode.el. alias tagebuch='/usr/bin/emacs \
-nw --no-init-file --no-site-file \
--load ~/.emacs-init-tagebuch \
~/pfad/zum/Tagebuch.txt.gpg'
-nw --no-init-file und --no-site file sagen: In der Konsole anzeigen und kein Standarddateien laden → deutlich schneller (Emacs kann unglaublich viel, aber einige Sachen machen es langsam; z.B. die vollständige Programmierumgebung).
--load ~/.emacs-init-tagebuch: Fügt genau die Fähigkeiten hinzu, die ich brauche, keine mehr, keine weniger. Details weiter unten.
Der Pfad ist klar. Die ~/.emacs-init-tagebuch richtet Emacs so ein, dass es jede Datei, die auf .gpg endet, transparent entschlüsselt (heißt, ich muss nur das Passwort eingeben, dann kann ich arbeiten, als wäre es nur eine normale Textdatei). Außerdem wird in Dateien mit Endung .txt.gpg Markdown-Syntax hervorgehoben und ist so schöner zu lesen und schreiben (daran habe ich mich schlicht gewöhnt und will es auch in meinem Tagebuch).
Die init-Datei aktiviert einige Features, die ich brauche:
Sie bindet mir den Markdown Mode [54] ein, so dass ich Syntax-Highlighting habe.
(setq load-path (cons "~/.emacs.d/libs/markdown-mode" load-path))
(autoload 'markdown-mode "markdown-mode.el"
"Major mode for editing Markdown files" t)
Dann aktiviert sie markdown für verschlüsselte Textdateien:
(setq auto-mode-alist
(cons '("\\.txt\\.gpg" . markdown-mode)
auto-mode-alist))
Dazu liefert sie schöne Zeilenumbrüche (am Wortende):
(global-visual-line-mode)
und aktiviert transparente Ver- und Entschlüsselung:
(require 'epa-file)
(epa-file-enable)
Außerdem habe ich mir eine kleine Lisp-Funktion geschrieben, die mir das Datum als Titel (zweite Ebene, H2 in HTML) in Markdown-Syntax ausgibt. Sie wird einfach mit M-x datum aufgerufen (im Code unten wird der Befehl durch das Schlüsselwort (interactive) aktiviert). Und ja, ich könnte hier alles einfügen, das ich in Lisp generieren kann. Also so gut wie alles :) (echte Programmiersprache)
(defun datum ()
"print the current time in iso-format"
(interactive)
(insert (format-time-string "%Y-%m-%d %H:%M:%S") "\n-------------------\n\n"))
Abschließend legt sie fest, dass sich emacs die Zeilennummer merken soll (ich will beim nächsten Öffnen des Tagebuches wieder in der Zeile sein, in der ich aufgehört habe), dass ich keine Startinfo haben und Dateien in UTF-8 kodieren will (für Umlaute und Zeug wie ι∫→√).
(custom-set-variables
'(current-language-environment "UTF-8")
'(default-input-method "rfc1345")
'(inhibit-startup-screen t)
'(save-place t nil (saveplace)))
Damit habe ich ein Tagebuch-Programm, das alles kann, was ich brauche. Und wenn ich noch mehr brauche, kann ich das ohne Probleme später einfügen.
Viel Spaß beim Tagebuch-Schreiben mit Emacs!
| Anhang | Größe |
|---|---|
| emacs-init-tagebuch [52] | 1 KB |
Um den Deutschen und Spanischen Muttertag in der Org-Agenda angezeigt zu bekommen, nutzt einfach
M-x customize-variable calendar-holidays
Und fügt die folgenden Zeilen ein:
(holiday-fixed 3 19 "Dia del Padre")
(holiday-float 5 0 2 "Muttertag")
(holiday-float 5 0 1 "Dia de la Madre")
(holiday-easter-etc 39 "Vatertag")
Dann nur noch C-x C-s zum Speichern, und die Org-Agenda zeigt euch die richtigen Mutter- und Vatertage für Deutschland und Spanien an.
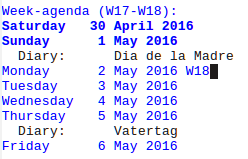
» Adding namespace support to emacs lisp in a macro with just 15 lines of code - it’s things like this which make lisp feel like the mother of all languages.«1
(defmacro namespace (prefix &rest sexps) (let* ((naive-dfs-map (lambda (fun tree) (mapcar (lambda (n) (if (listp n) (funcall naive-dfs-map fun n) (funcall fun n))) tree))) (to-rewrite (loop for sexp in sexps when (member (car sexp) '(defvar defmacro defun)) collect (cadr sexp))) (fixed-sexps (funcall naive-dfs-map (lambda (n) (if (member n to-rewrite) (intern (format "%s-%s" prefix n)) n)) sexps))) `(progn ,@fixed-sexps)))
(provide 'namespace)
(require 'namespace) (namespace foo (defun bar () "bar") (defun foo (s) "foo"))
(foo-foo (foo-bar))
Disclaimer: This code is not perfect. It will likely fail in unpredictable ways, and the number of not supported corner-cases is probably huge - and unknown. But (and that’s the relevant result) you can do this right. Rainer Joswig gives pointers for that [55] on Stackoverflow: “What you actually need is a so-called code-walker”. Also he shows examples where the code breaks.
(Der Hauptteil dieses Codes stammt von vpit3833 [56] und konr [57] und ich darf ihn verwenden [58]. Er funktioniert dank einer Korrektur von Stefan [59]. Er ist nicht perfekt, aber da er mir v.a. dazu dienen soll, meine eigenen Codeschnipsel besser zu organisieren, sollte ich das verschmerzen können)
Der Code mag schwer lesbar sein, hat aber riesige Implikationen: Du als einfacher Endnutzer des Lisp-Interpreters kannst Namespace-Support hinzufügen, ohne dass die Hauptentwickler dafür irgendetwas machen müssen.
Ich habe danach gesucht, weil ich in Python automatisch in jedem Modul einen Namespace habe, so dass der aktuelle Namensraum auch bei Verwendung von Zusatzmodulen sauber bleibt und ich immer weiß, woher eine Funktion oder Variable kommt, die ich verwende (das heißt, ich verwende kein from module import fun; fun(), sondern nur noch import module; module.fun oder bei sehr oft benutzten Modulen vielleicht noch import numpy as np; np.array()).
Um das in Emacs Lisp zu realisieren, musste ich bis heute jede Funktion explizit mit dem Namensraum definieren - und auch in dem Modul mit dem Namensraum aufrufen. Mit dem namespace macro kann ich jetzt diesen Code
(defun foo-bar () "bar") (defun foo-baz () (foo-bar)) (defun foo-isastring (s) (stringp s)) (defun foo-foo (s) (if (foo-isastring s) "foo"))
(foo-foo (foo-bar))
In diesen Code umschreiben
(require 'namespace) (namespace foo (defun bar () "bar") (defun baz () (bar)) (defun isastring (s) (stringp s)) (defun foo (s) (if (isastring s) "foo")))
(foo-foo (foo-bar))
Spannend wäre jetzt noch ein require-namespaced, um dem Code von anderen nachträglich einen Namensraum geben zu können:
(require-namespaced 'feature)
PS: In Guile Scheme [60] gibt es hierfür (use-modules ((foo) #:prefix foo-))
Der Code stammt größtenteils aus einer Diskussion auf Stackoverflow [61]. ↩
Ich bin gerade auf das Paper hier gestoßen:
“A Multi-Language Computing Environment for Literate Programming and Reproducible Research [62]” (PDF [63])
Es beschreibt schön, was mit emacs [64] org-mode [65] möglich ist. Dazu gehören so spannende Punkte wie im Dokument mitgelieferter Quellcode, dessen Ergebnisse automatisch eingebunden werden, so dass die Dokumente aktuell bleiben können.
Vor allem Neuerungen in Algorithmen können so sehr elegant gezeigt werden, und direkt erstellte Grafiken stellen sicher, dass keine veralteten Daten gezeigt werden und dokumentiert ist, woher die Daten eigentlich kommen.
Und der Quellcode sieht automatisch schön aus.
Das hier steht im paper (allerdings mit # statt \#):
\#+source: python-listdir
\#+begin_src python
import os
return len(os.listdir('.'))
\#+end_src
| number of files |
|-----------------|
| 28 |
\#+TBLFM: @2$1='(sbe python-listdir)
Es wird zu dem hier:
import os return len(os.listdir('.'))
| number of files |
|---|
| 28 |
Und im PDF sieht es so aus:

| Anhang | Größe |
|---|---|
| org-mode-babel-to-table.png [66] | 6.69 KB |
Wenn die Pressefreiheit stirbt, brauchen wir einen Ort, um unseren Kampf für freie Kommunikation zu organisieren.
Freenet [68] ermöglicht anonyme, unzensierbare Kommunikation.
Über Freenet kannst du anonyme Webseiten (freesites) veröffentlichen, die anderen Freenet-Nutzern zugänglich sind. Du lädst sie einfach in das dezentrale p2p-Netz, und solange sich Leute dafür interessieren (also sie anschauen), bleiben sie verfügbar, egal ob dein Rechner an ist oder nicht, und niemand kann sie offline nehmen1.
Du kannst auch die vielen verfügbaren Seiten lesen, die verschiedenste Themen von Kryptographie bis Philosophie abdecken, in anonymen Foren diskutieren (z.B. Sone [69] und FMS [70]) und dir ein Pseudonym aufbauen: Leute können sicher sein, dass nur du deine Seiten und Forenbeiträge schreibst. Sie wissen nur nicht, wer du wirklich bist (Pseudonymität).
Logischerweise ist es komplett dezentral organisiert, so dass es keine Möglichkeit der zentralen Kontrolle und keine einzelne Schwachstelle gibt. Nur so lässt sich sicherstellen, dass die Nutzer wirklich anonym sind und wirkliche Redefreiheit gewahrt bleibt. Dezentrale, nutzerkontrollierte Moderationmöglichkeiten liefern dabei Schutz gegen eine Zensur durch Überschreien oder Schikanieren.
Lade dir einfach das Installationsprogramm herunter und starte es (Downloadseite [71] (englisch)).
Nachdem es installiert ist und läuft, findest du eine neue Webseite unter 127.0.0.1:8888 [72]. Das ist deine Freenet-Startseite.
Du hast nun zwei Möglichkeiten
Du nutzt es direkt. Bereits jetzt kannst du anonyme Webseiten besuchen und veröffentlichen. Allerdings wird es anfangs etwas langsam sein. Gib ihm etwas Zeit, dann wird es schneller. In diesem Modus ist es sehr schwer herauszufinden, welche Seiten du besuchst und veröffenlichst, allerdings können Leute von außen herausfinden, dass du Freenet nutzt.
Von diesem Weg kannst du fließend zum sichereren Darknet Modus übergehen, wenn mehr und mehr deiner Freunde Freenet nutzen.
Du willst noch mehr Anonymität. In dem Fall suchst du Bekannte, die auch Freenet nutzen und verbindest dich mit ihnen. Schreib ihnen zum Beispiel diese E-Mail [73].
Klick dafür auf den Link Freunde [74] auf deiner Freenet-Startseite und wähle "advanced mode". Dort findest du eine Liste deiner Freunde und ganz unten deine "Knoten-Referenz". Mit der Knoten-Referenz identifizieren sich Freenet-Programme gegenseitig, um sicherzustellen, dass der andere wirklich ein Freund ist.
Wenn du mich kennst, dann schreib mir doch eine E-Mail [75] mit deiner Knoten-Referenz (am Besten verschlüsselt [76] - mein öffentlicher Schlüssel [77]) oder schreib' sie mir via Jabber o.ä..
Dann kann ich dir meine Knoten-Referenz schicken und sobald du sie hinzugefügt hast, verbinden sich unsere Freenet-Programme direkt.
Wenn du auf die Art mindestens 5 Freunde zusammen hast, kannst du auf deiner Freenet-Seite auf Konfiguration [78] klicken und das Sicherheitslevel auf "Hoch" stellen.
Damit wird es dann von außen fast unmöglich festzustellen, dass du Freenet nutzt.
Außerdem kannst du deinen Freunden direkt in Freenet Nachrichten schicken :)
Ich würde mich freuen, dich in Freenet zu sehen (auch wenn ich dich vermutlich nicht erkennen werde :-) ).
Und wenn du mich kennst, würde dich gerne auch in Freenet zu meinen Freunden hinzuzufügen, so dass wir uns gemeinsam gegen Zensur zur Wehr setzen können (der politische Weg ist zwar ebenso wichtig, aber dafür brauchen wir unzensierbaren Informationsaustausch, sonst sind wir zu leicht auszuschalten).
Um Inhalte in Freenet offline zu nehmen braucht es Maßnahmen, die einen Großteil des Internets blockieren würden. Ein nationaler Firewall wie in China reicht nicht. Das absolute Verbot verschlüsselter Übertragungen (für Privatleute) würde aktuell2 reichen, würde aber gleichzeitig den Großteil unserer Wirtschaft und Online-Kommunikation zerstören und uns wehrlos gegen Wirtschaftsspionage machen. ↩
Um auch beim Verbot von Verschlüsselten Übertragungen verbunden zu bleiben, sind zum Beispiel Bunny-Cams angedacht: Ein süßes Häschen wird vor eine Kamera gesetzt und ins Netz gestreamt. In den Bildstörungen werden die Daten versteckt (Steganographie [79]). ↩
Wenn ihr mal mit mir über Freenet [80] verbunden wart, bitte schaltet eure Knoten wieder an (oder schreibt mir eine Mail, damit wir euren neuen Knoten mit meinem verbinden können).
Ich würde gerne wieder vertraulich mit euch sprechen können. Gerade jetzt.
Solltet ihr die Mail verloren haben: Sie sagte in etwa das hier:
Über Freenet verbinden [81]
[80] Freenet ermöglicht es uns, unsichtbare Nachrichten zu schreiben. Zusätzlich kannst du darüber unter Pseudonym schreiben. Um dich mit mir zu verbinden … (weiterlesen) [81]
Weitere Infos zu Freenet: Wenn die Pressefreiheit stirbt, brauchen wir einen Ort, um unseren Kampf für freie Kommunikation zu organisieren [83].
Die Bundesregierung hat am 16.10.2015 die Vorratsdatenspeicherung durchgewunken, nachdem sie zwei Tage vorher die Opposition durch rechtswidrige1 Erweiterung der Tagesordnung am Vortag [84] ausgebremst hat (was das Bundesverfassungsgericht vor nicht einmal einem Monat verboten hat).2 Auf irgendwelche Fairness der aktuellen Regierung, oder auch nur Einhaltung geltenden Rechts, können wir daher offensichtlich nicht mehr vertrauen,3 und es wird Zeit, technische Lösungen zu nutzen.
Update 2026: Der EuGH hat 2022 entschieden, dass die Vorratsdatenspeicherung gegen Grundrechte verstößt. Das Bundesverfassungsgericht bestätigte das 2023. Einzelheiten gibt es als Chronologie in der Wikipedia [85]. Die Regierung plant schon wieder ein neues Gesetz, vermutlich auch wieder rechtswidrig [86].
Um zu verhindern, dass all eure Kommunikationspartner verwertbar aufgezeichnet werden, installiert bitte Freenet/Hyphanet [87].
→ Hyphanet installieren (Direktlink) ← [88]
 [87]
[87]
Bisher habe ich nur geschrieben, was Freenet/Hyphanet bietet und wie es für euch nützlich sein kann. Die Dreistigkeit der Regierung schockt mich so, dass ich euch jetzt bitte. Bitte installiert und verwendet Freenet/Hyphanet [87].
Ich bitte euch darum, weil uns Freenet/Hyphanet [87] (das Netzwerk, nicht der Provider) eine Plattform liefert, mit der wir Gegenmaßnahmen organisieren können, ohne dass all unsere Handlungen von denen überwacht werden, gegen die wir uns stellen. Wenn sie wissen, wer wann mit wem spricht, sind sie uns immer einen Schritt voraus.
Über Freenet/Hyphanet können wir sicher kommunizieren [89]:
Wenn ihr in Berlin wohnt, geht am Freitag zusammen mit digitalcourage zum Reichstag und demonstriert gegen die Vorratsdatenspeicherung [93]. Und egal wo ihr wohnt, installiert bitte Freenet/Hyphanet [87]:
Wenn die Pressefreiheit stirbt, brauchen wir einen Ort, um unseren Kampf für freie Kommunikation zu organisieren
Eine Beschreibung der Möglichkeiten, die Freenet/Hyphanet bietet, findet ihr im Artikel Freenet/Hyphanet: The forgotten cryptopunk paradise [94].
Und da ich es nicht oft genug wiederholen kann: Bitte installiert Freenet/Hyphanet [87]. Die Totalüberwachung trifft jetzt nicht mehr nur Australien [95], sondern ab morgen auch uns in Deutschland [96] (wenn die Seite des Bundestages nicht gleich lädt, klickt einfach auf neu laden). Und das betrifft uns — wie die Gründerin der Cryptoparties schreibt — selbst bei so grundlegenden Fragen wie Tampons [97]. Daher installiert bitte Freenet/Hyphanet [87].
Wenn du bis hier gelesen hast und noch nicht am Installieren bist, installierst du Freenet/Hyphanet [87] hoffentlich morgen. Ab dann brauchen wir es.
Und wenn du Abgeordnete oder Abgeordneter im Deutschen Bundestag bist und nicht weißt, ob das Bundestagsnetz wirklich wieder sicher ist [98], dann installier bitte Freenet/Hyphanet [87]. Du gehörst zu unseren gewählten Vertretern und es ist essenziell für eine funktionierende Demokratie, dass du deinen Kommunikationsmitteln vertrauen kannst.
(weitere Werkzeuge, die dein Rechner beherrschen sollte, sind Tor [99] und i2p [100]. Freenet/Hyphanet ist nicht perfekt und kann nicht alle Probleme lösen, daher sollten wir auch andere Mittel zur Verfügung haben. Allerdings ist Freenet/Hyphanet [87] das Werkzeug mit dem stärksten Fokus auf Sicherung freier Kommunikation.)
Die Erweiterung am Vortag verletzt laut Halina Wawzyniak die Geschäftsordnung des Bundestages, die eine Information über die Tagesordnung 3 Tage vor der Sitzung vorschreibt. Erweiterungen sind nur zulässig, wenn keine einzige Fraktion widerspricht, doch die Linke und die Grünen haben widersprochen. Der Widerspruch der Opposition zur Erweiterung wurde von den Regierungsfraktionen widerrechtlich ignoriert [101]. ↩
»Es stellt daher eine Verletzung von Rechten eines Abgeordneten dar, wenn dieser erforderliche Informationen so spät erhält, dass er nicht mehr in der Lage ist, sich fundiert mit diesen zu befassen und sich vor der Beratung oder Abstimmung eine Meinung zu dem Vorgang zu bilden.« — Bundesverfassungsgericht, Urteil vom 22. September 2015 - 2 BvE 1/11, 111 [102] ↩
Trotzdem ist die Verfassungsklage von Digital Courage gegen die Vorratsdatenspeicherung 2015 [103] umso wichtiger: Wenn wir starke Mittel aufgeben, weil andere versuchen, sie zu entwerten, verlieren wir an Handlungsmöglichkeiten. ↩
→ Kommentar zu Journalismus: Chancen für Mistkratzer [104] von DRadio Wissen [105].
Um die eigenen Informanten online wirklich zu schützen, können Journalisten mit ihnen über Hyphanet kommunizieren.
Dort kann niemand wissen, wer etwas bestimmtes geschrieben oder gelesen hat, aber es ist gesichert, dass die Veröffentlichende immer die gleiche ist.
Und entsprechend können Journalisten die Identität einer Informantin einmal offline prüfen und dann über Hyphanet in Kontakt bleiben. Die Informantin ist so selbst dann geschützt, wenn der Computer des Journalisten beschlagnahmt werden sollte.
Daher sollte Hyphanet-Kenntnis zum Handwerkszeug aller Journalisten gehören.
→ https://www.hyphanet.org [87]
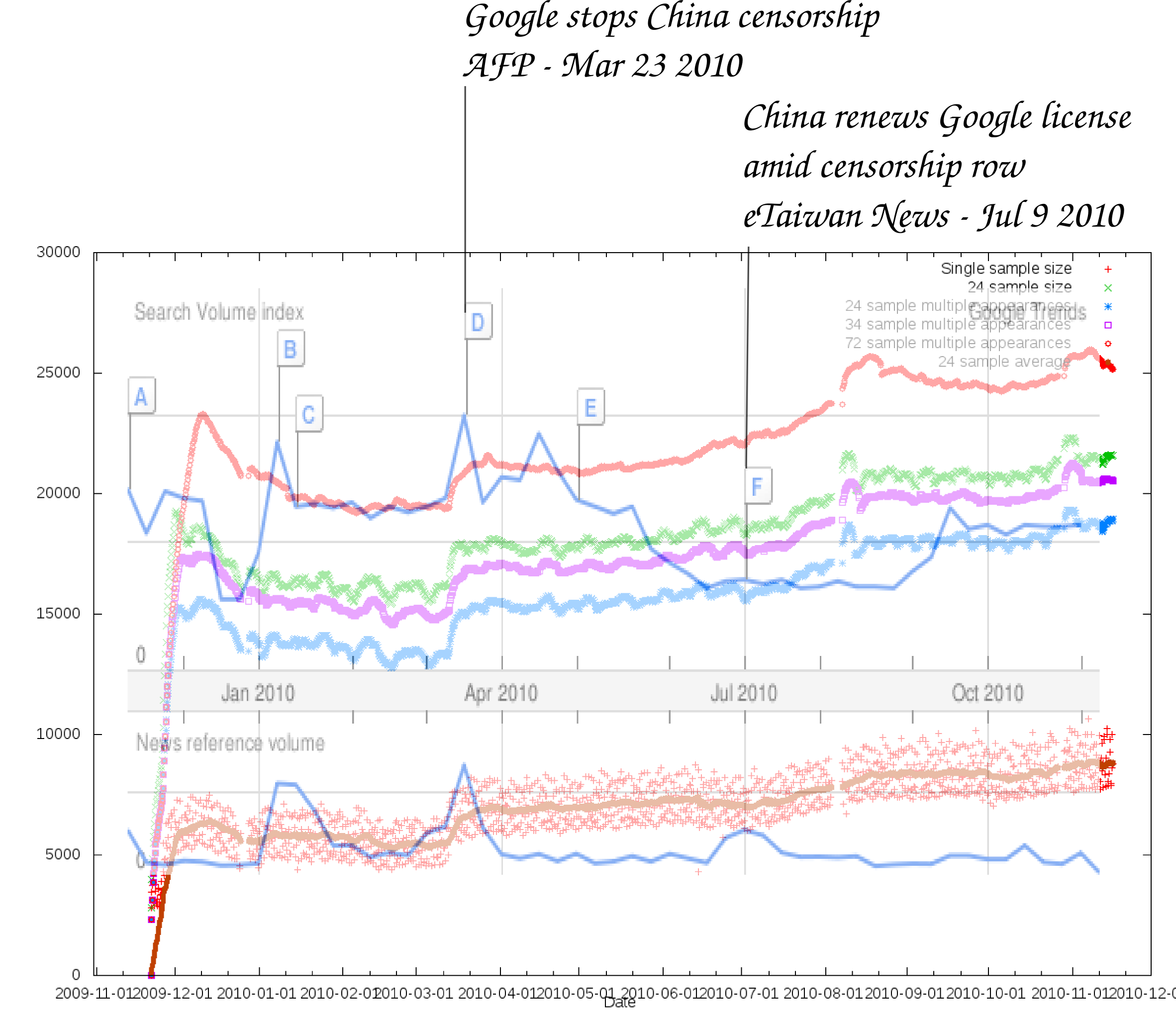
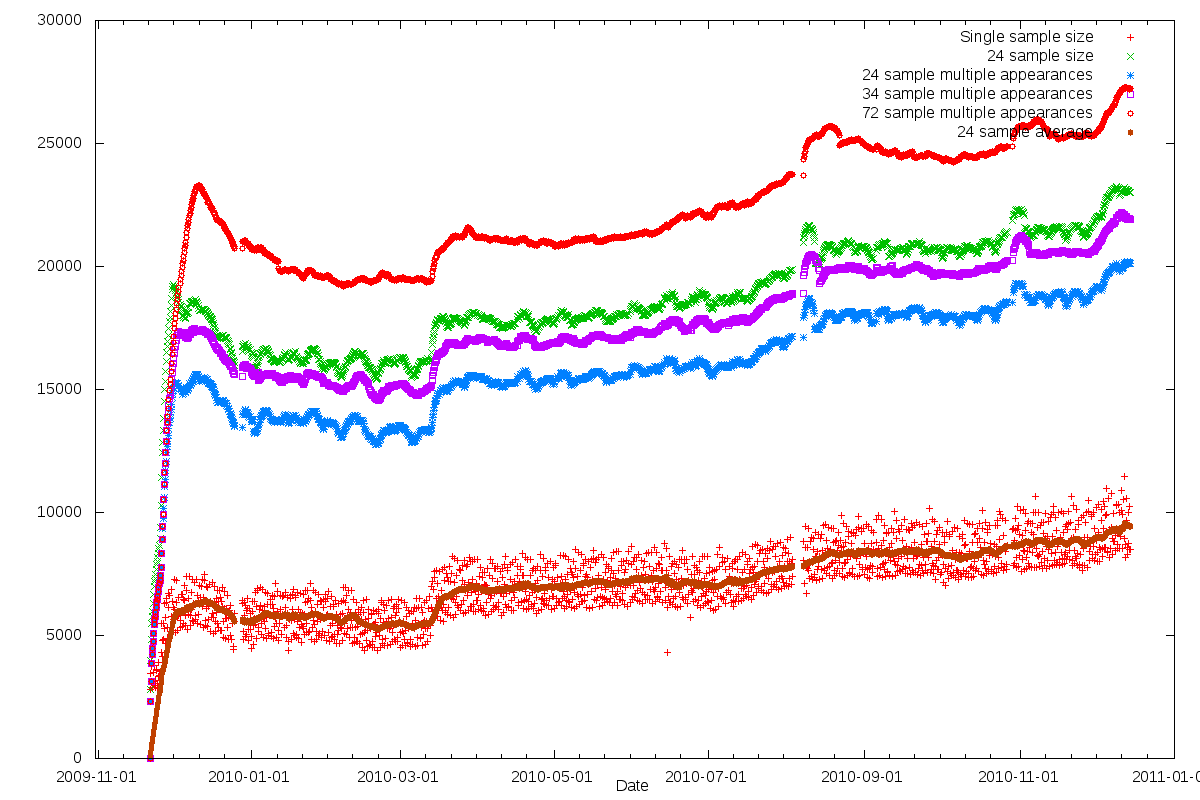
Ich habe eine kleine Grafik erstellt, die die Google News/Trends zu Zensur [106] und die Zahl der Freenet [68]-Nutzer gegenüberstellt. Das Ergebnis ist sehr aussagekräftig:
 [107]
[107]
Die zwei blauen Linien sind von Google Trends, oben die Anzahl der Suchanfragen, unten die Erwähnungen in Zeitungen. Die anderen Linien stammen von Freenet Graphs [108] mit Daten von Freenet Statistics [109] (die beiden Links brauchen ein lokal laufendes Freenet, um zu funktionieren).
Die rote Linie oben ist die Gesamtzahl unterschiedlicher anonymer Freenet-IDs, die in 15 Tagen mehrfach gesehen wurden. Die grüne Linie sind die IDs, die mindestens einmal in 5 Tagen gesehen wurden (alle 5 Stunden wird eine Stunde lang gesucht). Die Lila Linie zeigt die Anzahl der IDs, die in 7 Tagen mehr als einmal gesehen wurden (also mehr einmal oder mehr als fünf Stunden online waren). Die blaue zeigt das gleiche für 5 Tage. Und die rote Linie ganz unten zeigt die Anzahl von IDs, die in einer Stunde gesehen wurden. Das ist also die Zahl der Nutzer, die zu jeder Zeit online sind.
Die beiden wichtigsten Punkte, die mir daran auffallen: Als Google aufgehört hat, in China zu zensieren, ist die Zahl der regelmäßigen Freenet-Nutzer sprunghaft um knapp 2000 gestiegen (von 5000 auf 7000) und als Google seine chinesische Lizenz erneuert bekommen hat, begann ein fast 2 Monate anhaltendes langsameres aber insgesamt fast genauso starkes Wachstum von etwa 7000 auf 8200 Nutzer. Dass die Gesamtzahl der Nutzer in der gleichen Zeit nur etwas stärker gestiegen ist (von etwa 20000 auf etwa 22000, bzw. von 23000 auf 25000) deutet an, dass vor allem lange laufende Knoten dazugekommen sind.
Die Daten lassen also den plausiblen Schluss zu, dass Freenet spätestens seit April 2010 für seinen eigentlichen Zweck genutzt wird: Um in repressiven Staaten der Zensur zu entgehen. Freenet ist also bereits heute ein Garant der Redefreiheit für etwa 4000 Leute. Und so wie sich die westlichen Staaten zur Zeit entwickeln, kann es gut sein, dass es bald auch in in unseren Breiten als Garant der Redefreiheit notwendig sein wird. Wikileaks wurde effektiv ohne Anklage und Prozess zensiert, und anderen könnte es sehr leicht genauso ergehen.
Neuere Daten zeigen übrigens, dass auch die Zensur von Wikileaks einen deutlichen Zustrom von Nutzern brachte:
 [110]
[110]
Immerhin gibt es die cables von Wikileaks inzwischen mindestens zweimal in Freenet :)
(der kleine Bruch in den Linien kommt übrigens nur von einem kurzzeitigen Ausfall des Statistikrechners. Freenet lief problemlos weiter)
Nachdem ich jetzt erzählt habe, was andere machen: Wie sieht es mit dir aus? Willst du mit einem eigenen Freenet-Knoten mithelfen, Zensur auszuhebeln? → http://freenetproject.org/download.html [111]
Die Installation geht schnell und schmerzlos. Das Netz braucht allerdings ein paar Stunden, um an Geschwindigkeit zu gewinnen (dein Knoten optimiert sich, solange du ihn laufen lässt, fortwährend). Wenn du dem Netzwerk helfen willst, schau, ob du deinen Knoten durchgehend laufen lassen kannst (mindestens 16 Stunden am Tag); dann funktioniert die Optimierung besser, du hast also auch höhere Geschwindigkeiten :)
Und wenn du ein paar Freunde hast, die auch mitmachen wollen, könnt ihr euch direkt über das Darknet [112] verbinden. Dadurch gewinnen eue Freenet-Knoten nochmal massiv an Sicherheit dazu, und wenn jeder von deinen Freunden nochmal zwei oder drei andere Freunde für Freenet gewinnen kann, habt ihr bald ein nur über Freunde verbundenes Netz, das auch von außen kaum mehr zu entdecken ist. Klickt einfach auf den „einen Freund hinzufügen [113]“-Link in euren jeweiligen Knoten, da steht alles erklärt (der Link hier führt direkt auf euren lokalen Knoten und funktioniert nur, wenn ihr schon ein Freenet lokal am laufen habt).
Viel Spaß in einer zensurfreien Welt!
| Anhang | Größe |
|---|---|
| freenet_graphs-2010-11-17-network_size-associated-google-trend.png [114] | 22.56 KB |
| freenet_graphs-2010-11-16-with_trend.png [107] | 321.32 KB |
| freenet_graphs-2010-11-17-network_size.png [115] | 28.75 KB |
| freenet_graphs-2010-11-16-with_trend_small.png [116] | 124.08 KB |
| freenet_graphs-2010-12-15-network_size.png [110] | 29.34 KB |
| freenet_graphs-2010-12-15-network_size_small.png [117] | 9.59 KB |
Kannst du in wenigen Worten beschreiben, warum mit Freenet sicher zu kommunizieren ist?
— Falk Flak
Bei Freenet gibt es zwei Arten sicher zu kommunizieren:
Du kannst dir ein Pseudonym erschaffen [118], unter dem du in Freenet-Internen Foren [90] schreiben und anderen Nutzern anonyme, aber spamgeschützte E-Mails [119] schreiben kannst. Die Daten werden dafür direkt zwischen Freenet Nutzenden über mehrere Schritte ausgetauscht, es gibt also keinen zentral kontrollierten Server. Du kannst Daten hochladen [120], die auch dann noch verfügbar sind, wenn du offline bist, aber nur für diejenigen, denen du den Link dazu gegeben hast.
Du verbindest dich direkt mit Freunden [73]. Von außen kann sichtbar sein, dass ihr euch kennt, aber nicht wann und über was ihr redet. Die Daten, die Freenet für den Normalbetrieb austauscht, sehen genauso aus wie Kommunikation zwischen dir und deinen Freunden, verdecken sie also.
Eine kurze Präsentation dazu: Freenet Nutzen: Technische Lösungen für freie Kommunikation im Internet [121]
Es gibt auch einen längeren Vortrag zu Freenet aus der Chaotischen Viertelstunde bei Noname e.V. [122]:
Sone ermöglicht twitter-ähnliche Kurznachrichten über Freenet [68]. Damit bietet es vollständig anonymes und skalierendes Microbloggen. Es ist noch im Beta-Stadium, funktioniert für mich aber bereits sehr gut.
[123]
(click for full size)(→ Setup auf English [124] - Freenet Social Networking Guide ←)
Zum Installieren braucht ihr ein laufendes Freenet → freenetproject.org [68]
Dann einfach das Plugin WoT aktivieren und Sone auf der Plugin-Seite [125] aus dem Freenet laden:
USK@nwa8lHa271k2QvJ8aa0Ov7IHAV-DFOCFgmDt3X6BpCI,DuQSUZiI~agF8c-6tjsFFGuZ8eICrzWCILB60nT8KKo,AQACAAE/sone/-1/sone-current.jar
Dazu benötigt ihr noch eine WoT-ID (erstellen [126]).
Meine öffentliche ID ist:
USK@6~ZDYdvAgMoUfG6M5Kwi7SQqyS-gTcyFeaNN1Pf3FvY,OSOT4OEeg4xyYnwcGECZUX6~lnmYrZsz05Km7G7bvOQ,AQACAAE/WoT/74
Ihr könnt sie im WoT eintragen auf WoT/KnownIdentities [127].
In Sone bin ich auf
http://127.0.0.1:8888/Sone/viewSone.html?sone=6~ZDYdvAgMoUfG6M5Kwi7SQqyS-gTcyFeaNN1Pf3FvY
Bei Fragen, oder sollte irgendwas nicht laufen, könnt ihr mich über GNU Social [128] oder über twitter [129] erreichen.
PS: Sone wird aktuell sehr schnell weiterentwickelt. Folgt einfach der „sone“ ID, um Neuigkeiten mitzubekommen → viewSone.html?sone=nwa8lHa271k2QvJ8aa0Ov7IHAV-DFOCFgmDt3X6BpCI [130]
PPS: Die Lizenz ist die GPLv3 [131] und der Quellcode ist unter https://github.com/Bombe/Sone/ [132].
| Anhang | Größe |
|---|---|
| 2011-04-06-freenet-sone.png [123] | 116.3 KB |
| 2011-04-06-freenet-sone_small.png [133] | 49.03 KB |
→ Auf Golem.de wurde heute ein … mäßig guter Artikel zu Freenet [134] veröffentlicht. Die Zusammenfassung ist „Hauptsächlich Schmuddelinhalte, viele von 2008, mehrere Minuten Ladezeit, begrenzter Speicherplatz und wenig Anonymität außer mit Darknet“. Das hier ist meine höfliche Antwort.
Update: Nachdem ich mich auf Twitter beschwert habe, hat der Autor versprochen [135] die im Artikel völlig fehlenden Kommunikationsprogramme zu erwähnen. Doch das einzige, was ich finde, ist die Zeile „So gibt es beispielsweise Foren (FMS), Microblogging-Dienste (Sone) oder Chat-Programme (FLIP), die nachgerüstet werden können.“ unter der Überschrift „Daten werden in Schlüsseln gespeichert“ - also da, wo niemand nach Kommunikationsprogrammen suchen würde. So sieht eine Minimalkorrektur aus, wenn man die Wirkung des Artikels nicht von Fakten trüben lassen will. Informieren, dass was fehlte? Änderungshinweis? Fehlanzeige. Nichtmal einen Kommentar im eigenen Forum war es wert.
Was im Beitrag fehlt sind die Bereiche, in denen Freenet-Nutzer sich praktisch austauschen: Die Foren (FMS), Microblogging (Sone) und Chat (FLIP).
Für neue Nutzer sind die nicht gleich sichtbar (Zusatzsoftware), aber sie sind der Grund, warum wenig in Blogs steht: In den Plugins und Foren findet die ganze Interaktivität statt.
Trotzdem listet Nerdageddon über 300 Seiten, die seit 2013 hochgeladen oder aktualisiert wurden, allerdings keine einzige von 2008 - ich weiß also nicht, woher die Information mit den alten Seiten kommt.
Wer Hintergrund will: Freenet Sozial Networking Guide [136] („soziale“ Anwendungen) oder Nerdageddon [137] (Seiten in Freenet)
Eine Ladezeit von Minuten für eine Webseite in Freenet habe ich schon lange nicht mehr erlebt. 5 bis 30 Sekunden trifft es eher. Wobei mit FLIP (Chat) 60s für eine komplette Round-Trip-Time reichen, also bis eine Antwort auf eine Frage eintreffen kann.
Der begrenzte Speicherplatz ist aktuell „etwa 140 Terabyte [138]“ und steigt automatisch wenn neue Leute dazukommen.
Und die begrenzte Anonymität in Freenet, weil es mit moderatem Aufwand möglich ist, die IPs aller Freenet Nutzer zu finden, gilt wie im Tor FAQ beschrieben [139] genauso auch für Tor. Das als „wenig Anonymität“ hervorzuheben ist damit eine offensichtliche Irreführung, die hoffentlich in zu großem Vertrauen auf Tor wurzelt.
Zusätzlich zu der im Artikel verlinkten Liste mit möglichen Schwachstellen [140] gibt es übrigens noch die allgemeine Security Summary [141] und die Opennet Attacks [142]. Aus der Offenlegung der für die Entwickler denkbaren Schwachstellen auf fehlende Anonymität zu schließen ist allerdings voreilig, solange diese Anonymität nicht mit anderen Diensten verglichen wird.
PS: Ich würde Golem um eine Richtigstellung bitten. Jeder Autor und jede Autorin ist natürlich frei, den Fokus eines Artikels zu wählen, aber sofort erkennbare Irreführungen sollten nicht sein. Das alles hier habe ich auch in den Kommentaren zum Artikel geschrieben, der Autor weiß es also spätestens jetzt.
PPS: Der Autor findet das nicht, weil das bei ihm so aussah. Meine Fragen zu Testmethode und Konfiguration wurden bisher ignoriert:
@zambaloelek [143] @golem [144] wie habt ihr es denn getestet?(dass Dateien von 2008 meist nicht mehr da sind ist zu erwarten - habt ihr neue getestet?)
— A. Babenhauserheide (@ArneBab) February 25, 2015 [145]@zambaloelek [143] @golem [144] wie viel Bandbreite habt ihr Freenet gegeben (Abschätzung davon: Wie viele Verbindungen hattet ihr? Über 20?)
— A. Babenhauserheide (@ArneBab) February 26, 2015 [146]PPPS: Die Aussage im Artikel „Es gibt auch kein einzelnes Darknet, sondern eine Vielzahl von Darknets, in denen sich Teilnehmer treffen, die sich gegenseitig vertrauen“ erweckt den Eindruck, die Darknets wären voneinander abgeschottet. Das stimmt so nicht: Auch wenn es möglich ist, viele kleine Darknets zu schaffen, ermöglicht es Freenet gleichzeitig, diese kleineren Darknets über das offene Netz zu verbinden. Wenn auch nur eine Person in dem Darknet eine Verbindung ins nicht versteckte Netz hält, können alle im Darknet auf alle Inhalte in Freenet zugreifen und auch Inhalte hochladen. Wenn genügend Leute Freenet nutzen, dürften die kleineren Darknets außerdem laut der immer wieder bestätigten Kleine-Welt-Hypothese [147] auf „natürliche Art“ verbunden werden: Die vereinen sich zu einem großen Darknet.
Nachdem die Politik immer mehr auf Zensur von allem möglichen drängt, gibt es die Gefahr, dass das internet zu einem vollständig kontrollierten Raum wird und Redefreiheit völlig verschwindet, weil Alle ihre Aussagen vor dem Onlinestellen selber auf mögliche Zensurgefahr prüfen - und damit zensieren.
Das hat mit der Impressumspflicht angefangen, die sagt, dass jede Seite ein Impressum tragen muss, obwohl der Betreiber für die Polizei sowieso leicht zu ermitteln ist.
Dann ging es weiter mit Abmahnwellen.
Und jetzt kommt die direkte und nicht prüfbare Zensur.
Da die Entwicklung nicht so aussieht, als könnten wir sie in den nächsten Jahren rückgängig machen, sollten wir eine Möglichkeit haben, unseren Protest gegen die Zensur in einer zensursicheren Umgebung zu organisieren.
Freenet [148] (das Programm, nicht der Provider) bietet dabei ein sicheres Baumhaus, in dem die Redefreiheit gewahrt bleibt. Es lebt auf den Rechnern der Beteiligten, und solange ein Beitrag Leute interessiert, kann er nicht entfernt werden. Gleichzeitig kann niemand herausfinden, von wem die Inhalte (Webseiten) geschrieben wurden und wer sie liest.
Wenn es im Darknet-Modus genutzt wird, kann außerdem niemand (ohne massiven Aufwand) herausfinden, ob jemand an Freenet teilnimmt, denn jeder kennt nur seine direkten Kontakte.
Und es ist frei lizensiert und für Windows, MacOSX und GNU/Linux verfügbar, so dass jeder sich an der Entwicklung beteiligen kann, wenn sie ihm wichtig ist (und er programmieren kann).
In anderen Ländern wurden schon zensurkritische Weblogs zensiert. Die Wahrscheinlichkeit ist recht hoch, dass das bei uns auch passiert.
(ich habe diesen Beitrag ursprünglich im Heise.de Forum geschrieben [149] - als Kommentar zu einem Beitrag, darüber, dass Zypries das Recht auf Privatkopie in Frage stellt und rechtlich durchsetzbare "Good-Internet-Kodices" will [150].
Mein Vortrag beginnt bei 5:56 [151].
Ich bin dabei, den Text zu transkribieren, aber es wird noch etwas dauern, bis ich fertig bin. Sobald ich fertig bin, gibt es das als Untertitel-Datei. Was ich bisher habe als Text:
(Es beginnt Wolfgang)
Unser jährlicher SUMA Award, den wir seit 7 Jahren vergeben,
soll Arbeiten oder Projekte im Internet auszeichnen, welche für die Zukunft der digitalen Welt Wesentliches leisten.
Nun ist natürlich die nächste naheliegende Frage, was ist denn wesentlich. Eine der Kernfragen der Menschheit.
Das ist sehr allgemein formuliert, und man muss es natürlich mit einem Wort spezieller formulieren.
Und da steht jedes Jahr ein anderes Thema im Vordergrund. Für das vergangene Jahr 2014 war die Ausschreibung definiert als
Ideen zum Schutz gegen Überwachung im Netz
Nun kann man Gottseidank sagen, dass es sehr viele sehr gute Ideen gegen Überwachung im Netz gibt.
Es gibt so viele gute Ideen, dass wir mit der Jury fast überfordert waren. Wir haben gut 50 Vorschläge gekriegt.
Und aus diesen vielen guten Vorschlägen auszuwählen, das hat länger gedauert als es je gedauert hat.
Ich will diese 50 jetzt aber nicht aufzählen und auch später nicht vorstellen.
Es kann auch gut sein, wenn die sich mal weiterentwickeln, dass die eine oder andere davon in späteren Jahren
nochmal zur Entscheidung ansteht und dann auch einen SUMA Award gewinnt.
Also wenn jemand unter ihnen zu den Einreichenden gehörte, behalten Sie das Projekt bitte im Auge.
Und wenn die Thematik wieder in die Richtung geht, schlagen Sie das Projekt nochmal vor.
Darüber hinaus sollte jeder wissen, dass Jeder oder Jede Projekte oder Arbeiten für den Award vorschlagen kann.
Das können eigene Arbeiten sein, das können aber auch andere Arbeiten oder Projekte sein, die sie einfach nur gut finden.
Wenn es unter die Thematik des Awards passt.
Auf der Webseite suma-awards.de (ich will jetzt nicht weiter rumklicken) kann man nachlesen, was die Bedingungen sind.
Der Preis ist mit 2500 Euro dotiertund SUMA e.V. wird den Preisträger auch in jeder erdenklichen Weise immateriell fördern.
Es lohnt sich also durchaus.
Nun also zum diesjährigen Preisträger.
Bisher hoffe ich mal, dass die Geheimhaltungspflicht hier durchgeschlagen hat und dass es keine Leaks oder Wikileaks gegeben hat.
Der Preisträger weilt unter uns aber wahrscheinlich ist er unerkannt.
Ich verrate ihn aber immer noch nicht ein bisschen spannend machen gehört dazu.
Gesucht war also für den Award ein Projekt, welches für die Zukunft der Digitalen Welt
Wesentliche Ideen zum Schutz gegen Überwachung bietet.
Und selbst wenn ich Ihnen jetzt den Namen sage werden die wenigsten wahrscheinlich was damit anfangen können.
Sie werden diesen Namen überhaupt nicht kennen. Und genau das will dieser Award ändern.
Denn dieses Projekt hat das gewaltige Potenzial gegen Überwachung im Netz.
Also der Preisträger heißt, und jetzt, wenn wir jetzt Musik haben, Musik an
Das Freenet Project
Was die Sache aber kompliziert macht.
Denn erstens ist das Freenet wirklich etwas kompliziertes
und zweitens segelt mehreres unter dem Namen Freenet.
Bei Wikipedia findet man 4 Bedeutungen des Wortes Freenet.
Zum Ersten gibt es einen Internet-Anbieter in Deutschland, Die Freenet Aktiengesellschaft. Die hat den Preis nicht gewonnen.
Zum Zweiten gibt es auch eine Funkanwendung, die auf gut Deutsch die Freifunknetze genannt werden. Auch die sind nicht Preisträger.
Drittens die Bedeutung des Wortes Freenet als weltweite Netz-Gemeinschaft des non-profit Internetzugangs. Auch nicht Preisträger.
Aber viertens gibt es ein peer-to-peer Netz unter der Addresse freenetproject.org und genau das, letzteres
Das peer-to-peer Netz Freenet Das erhält den SUMA-Award
Dieses Projekt wurde unabhängig voneinander von mehreren Personen in der Jury als Preisträger vorgeschlagen.
Ganz kurz, was ist das besondere daran?
Gleich kommt noch viel mehr, aber jetzt mal ganz kurz nur:
Freenet ist eine peer-to-peer Software, zentrale Server und ähnliche zentrale Strukturen werden konsequent vermieden.
Also Dezentralisierung, Redundanz, Verschlüsselung, und dynamisches Routing sind Wesensmerkmale.
Freenet wird als Freie Software unter GNU General Public Licens entwickelt
und das reguläre Internet wird nur als Übertragungsfunktionalität genutzt.
Es ist sozusagen ein eigenes Netz im Netz.
Wir kommen ja ganz allmählich vom Allgemeinen zum ganz Konkreteren.
Als die SUMA Award Jury den Preis beschlossen hatte, bestand eine Schwierigkeit darin, einen Repräsentanten diesen Netzes zu finden
Denn Freenet ist ja auch eine Art Darknet. Ein Netz, das vorwiegend unsichtbar für den Rest des Internet ist.
Die Verwendung von Klarnamen ist auch nicht selbstverständlich.
aber nach einigen Mühen ist es uns gelungen, in Deutschland jemanden zu finden
der uns in die Geheimnisse dieses Netzes einweihen kann.
Lieber Herr Babenhauserheide Bitte kommen Sie doch jetzt mal nach vorne.
Ich habe hier einen Briefumschlag in dem zwei wesentliche Dinge drin sind.
Einmal den SUMA Award
Zweitens vielleicht noch den Scheck mit dem Preisgeld.
Nun möchte ich selber auch noch viel mehr internes über das Freenet erfahren.
Dann werde ich jetzt aufmerksam zuhören.
(Hier übernimmt Arne)
Also erstmal danke für den Preis.
Ich hab lange überlegt, was ich dazu wirklich sagen könnte, aber ich finde ehrlich gesagt keine wirklichen Worte, die es beschreiben können.
Danke.
Das Preisgeld wird für uns wahrscheinlich ermöglichen, unseren Teilzeitentwickler, der am Web of Trust arbeitet
und damit einige der kritischen Dienste weiter voranbringt für ein bis zwei Monate zu bezahlen
dafür werden wir es auch verwenden zumindest vorraussichtlich
es geht also in die Gesamtspenden, die für das Freenet Projekt da sind, mit ein.
 [68]
[68]Diese E-Mail habe ich im September an viele meiner Freunde geschickt,12 weil ich gemerkt habe, dass ich elektronisch fast nichts Persönliches mehr geschrieben habe.3 Wenn ihr das gleiche Problem habt, fühlt euch frei, meinen Text anzupassen und an eure Freunde zu schicken. Einen mit minimalen Anpassungen verschickbaren Text findet ihr unter 2014-11-01-ueber-freenet-verbinden-mail.html [152].4
Die 6 eingerückten Absätze am Anfang enthalten die essenziellen Infos, wie ich sie für eine gute Freundin zusammengefasst habe. Die ursprüngliche Mail kommt danach.
Die Kurzform ist: Ich zensiere inzwischen meine Mails, sogar wann ich wem schreibe - nicht mehr nur aus Vorsicht, sondern auch emotional motiviert.
Freenet ermöglicht es, unsichtbare Nachrichten zu schreiben. Es ist zwar sichtbar, dass eine Verbindung besteht, aber nicht wie und wann sie genutzt wird. Und wenn es v.a. dafür genutzt wird, braucht es auch wenig Leistung.
Der Rest der Mail zeigt nur, wie es geht:
- Auf https://freenetproject.org [80] Freenet herunterladen und installieren,
- im Wizard „nur Freunde“ wählen und dann
- auf http://127.0.0.1:8888/addfriend/ [113] den Textblock5 in das Textfeld kopieren.
- Dann mir einfach schicken, was Freenet auf der Seite hier zeigt: http://127.0.0.1:8888/friends/myref.txt [153] (an eine Mail anhängen oder einfach in den Text der Mail kopieren)
Sobald ich das bei mir eingetragen habe, sind wir verbunden. Wir können uns dann einfach über die Freundesseite schreiben:
- Schreiben: http://127.0.0.1:8888/friends/
- Lesen: http://127.0.0.1:8888/alerts/
Hi,
Ich kommuniziere mehr und mehr über Freenet,6 v.a. mit Darknet-Kontakten, also Leuten, die ich persönlich kenne. Und das würde ich auch mit euch gerne machen. Dabei wird nämlich komplett verborgen, dass wir uns überhaupt unterhalten: Jede Nachricht untereinander wird in der allgemeinen Verschlüsselten Kommunikation von Freenet versteckt.
Wenn euch das schon überzeugt und ihr keine 2 Seiten Begründung lesen wollt, springt einfach vor zu Freenet Installieren: Uns zu verbinden braucht nur 5 Minuten und eine Antwort per E-Mail.
Letzte Woche habe ich die Kommunikation über Freenet genutzt, um mit anderen Freenet-Unterstützern an einem Artikel zu schreiben, der “confidential” sein sollte - also wirklich vorher noch nicht veröffentlicht. Dadurch fielen die meisten unserer üblichen Kooperationsmöglichkeiten weg: Piratepad (das ist ganz öffentlich), E-Mail (da ist öffentlich, dass wir gemeinsam an etwas arbeiten - Metadaten halt), IRC (öffentlich), auch alle Web-Kooperations-Dienste (effektiv öffentlich), usw.
Das Dokument einfach in Freenet hochzuladen und dann per node-to-node Nachricht (N2N) auszutauschen hat dagegen sehr gut funktioniert.
Leider sind das aber vor allem Leute, mit denen ich technisches zusammen mache. Gemeinsames Basteln an Kreativem und Unterhaltungen zu Kreativem fehlen da bisher fast völlig.
Deswegen fände ich es toll, wenn wir uns über Freenet verbinden könnten. Wenn wir im reinen Darknet-Modus arbeiten braucht es wenig Leistung und wenig Bandbreite, bietet aber schon alles, was wir brauchen, um unsere Kommunikation komplett zu verstecken. Es kann zwar noch viel mehr als das, aber es ist dieses für Freenet sehr grundlegende Feature, das mir im normalen Netz fehlt: Ich kann euch endlich wieder völlig unsichtbare Nachrichten schicken.
In E-Mails würde ich dagegen zum Beispiel nichts über Sachen schreiben, die mich bei der Arbeit stören. Da könnte ich das auch gleich auf meine Webseite stellen. Das ist zwar objektiv gesehen etwas übertrieben, entspricht aber inzwischen meinem Gefühl was Kommunikation angeht - und entsprechend wenig verwende ich E-Mails (u.ä.) für persönliche Kommunikation.
Frei mein Selbst in der Öffentlichkeit zu leben ist ein inhärenter Widerspruch, solange es auch nur einen einzigen intoleranten Menschen gibt. Offline haben wir drei Möglichkeiten:
- Ich kann in der Öffentlichkeit Frei sein, wenn ich ein Pseudonym verwende.
- Ich kann mein Selbst in der Öffentlichkeit leben, wenn ich mein eigenes Wesen ausreichend einschränke.
- Oder ich kann Frei mein Selbst leben, solange ich unter Freunden bin.
Im Netz haben die meisten Leute nur die Zweite Möglichkeit. Freenet gibt uns 1 und 3 zurück: Pseudonyme und vertrauliche Kommunikation unter Freunden.
Wenn ihr euch über Freenet mit mir verbinden wollt, geht einfach auf https://freenetproject.org [80] und drückt auf den grünen Install-Knopf.
Klickt euch dann wie üblich durch den Installer. Am Ende sollte euer Browser aufspringen und den Freenet Einrichtungs-Assistenten zeigen.
Ihr habt hier zwei Möglichkeiten:
Dann klickt euch durch die Warnungen (ja, ihr kennt mindestens eine Person, die Freenet verwendet) und wählt jeweils entweder die normale Antwort (wirklich „normal“ genannt) oder die vorausgewählte. Wenn ihr mit dem Assistenten durch seid, wird Freenet sich beschweren, dass ihr noch keine Freunde habt. Das sollten wir schnell ändern.
Ladet euch erst den Anhang "noderef-arne.txt" meiner E-Mail runter.8 Dann geht auf http://127.0.0.1:8888/addfriend/ [113], wählt die Datei aus und klickt auf den Knopf “hinzufügen”. Abschließend ladet von der gleichen Seite die Datei „Meine Knotenreferenz“ herunter ( http://127.0.0.1:8888/friends/myref.txt [153] ) und schickt sie mir per Mail. Sobald ich die Datei bei mir hinzugefügt habe, verbinden sich unsere Rechner, und wann immer wir beide online sind, können wir wirklich versteckte Nachrichten austauschen.
Um mir dann eine versteckte Nachricht zu schicken, geht einfach auf http://127.0.0.1:8888/friends/ [154] und klickt auf meinen Namen: Damit beginnt ihr eine node-to-node Nachricht (N2N). Wenn ihr mir eine Datei schicken wollt, klickt auf Filesharing->Upload a File ( http://127.0.0.1:8888/insertfile/ [155] ) und ladet sie als “canonical key” hoch. Dieser Upload ist für die Außenwelt unsichtbar. Sobald er fertig ist, schickt mir einfach den Link per node-to-node Nachricht (N2N) (der Link wird in den uploads als CHK@... gezeigt).9
Ich hoffe, dass möglichst viele von euch dabei sind!
(natürlich könnt ihr euch untereinander auf die gleiche Art verbinden)
Liebe Grüße,
Arne
PS: Zusätzlich zu den einfachen N2N-Nachrichten hat Freenet eine ganze Reihe Plugins für größere Interaktivität - Foren, Microblogs, usw. Viele davon brauchen das Web of Trust plugin für Spamverhinderung, und das frisst zur Zeit noch viel Leistung. Wenn ihr keine öffentlichen Pseudonyme braucht, könnt ihr es einfach aus lassen. Dann bleiben auch Laptop-Lüfter leise :)
Wenn ihr diese Mail an eure Freunde schicken wollt, um euch mit ihnen zu verbinden, könnt ihr einfach meinen Text kopieren und an die E-Mail eure „noderef“ einfügen.
Einen mit minimalen Anpassungen verschickbaren Text findet ihr unter 2014-11-01-ueber-freenet-verbinden-mail.html [152]
Solange ihr Freenet [80] am Laufen habt, könnt ihr eure noderef jederzeit von http://127.0.0.1:8888/friends/myref.txt [153] herunterladen. Um Verwirrung zu vermeiden, benennt sie am Besten als noderef-[EUER_NAME].txt.
Wenn ihr bessere Texte dafür schreibt als den hier, wäre es toll, wenn ihr sie mir per Mail schickt [75] - und mir erlaubt, sie hier zu veröffentlichen, damit andere sie finden und verwenden können.
Natürlich wäre es besser, diese E-Mail zu verschlüsseln und sicherzustellen, dass wir eine sauber Kette von Signaturen haben. Aber das ist nur notwendig, wenn wir verstecken wollten, dass wir Freenet nutzen. Um zu verstecken, wann wir uns unterhalten, ist es nicht notwendig. Wir können stattdessen einfach irgendwann mal prüfen, ob der Identity-Schlüssel unserer Noderefs wirklich richtig ist (steht in der ersten Zeile der noderef). Wenn nicht, hat jemand unsere E-Mails abgefangen und geändert. Ich halte es allerdings für sehr unwahrscheinlich, dass das passiert: Das wäre die nächste tolle Story for Panorama und würde allen Überwachungsgegnern massiven Zündstoff geben. Als Panorama die Überwachung von Tor-Nutzern aufgedeckt hat, war das für die Überwacher schmerzhaft:
Quellcode entschlüsselt: Beweis für NSA-Spionage in Deutschland [156]
Abfangen und verändern der E-Mails von normalen Bürgern würde vermutlich noch mehr einschlagen. Das wäre ein aktiver Bruch des Postgeheimnisses und ein Eingriff in die Privatsphäre. Und natürlich auch eine Urheberechtsverletzung ☺ (mir als altem Tauschbörsennutzer macht es immer wieder Spaß, auf irrigen Paradoxa herumzureiten, in die sich ein Staat mit einem zum alleinigen Maßstab erkorenen Urheberrecht bringt ☺) ↩
Genauer gesagt habe ich die Mail an diejenigen meiner Freunde geschickt, bei denen ich denke, dass ich sie nicht verschrecke, wenn das System nicht gleich richtig funktioniert. ↩
Danke NSA, GCHQ, BND und wer sonst noch alles überwacht. Eure normative Zensur funktioniert. Die Schere im Kopf ist da, zumindest bei mir. Und ich hasse das. Deswegen ergreife ich Maßnahmen dagegen. ↩
Die Mail an Freunde sollte eine “noderef” im Anhang haben. Wenn ihr Freenet [80] am Laufen habt, könnt ihr eure noderef jederzeit von http://127.0.0.1:8888/friends/myref.txt [153] herunterladen. Um Verwirrung zu vermeiden, benennt sie am Besten als noderef-[NAME].txt - immerhin werden Leute hoffentlich viele davon austauschen. ↩
Ausge-X-te Version meines Textblocks (steht in der Mail)
identity=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
lastGoodVersion==XXXXXXXXXXXXXXXXXXXXXXX
location==XXXXXXXXXXXXXXXXXXXXXXXX
myName=ArneBab
opennet=false
sig=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
sigP256=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
version==XXXXXXXXXXXXXXXXXXXXXXX
ark.number=XXXX
ark.pubURI=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
auth.negTypes==XXXXXX
dsaGroup.g=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
dsaGroup.p=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
dsaGroup.q=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
dsaPubKey.y=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
ecdsa.P256.pub=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
physical.udp==XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
End ↩
Freenet [80] ist freie Software und wird seit 14 Jahren entwickelt - bleibt uns also vermutlich erhalten. Eine Kurzfassung seiner Möglichkeiten findet ihr in den Folien [122] zu einem Vortrag beim Chaostreff Heidelberg (Info [157], Video [158]). ↩
Plugins können die Rechnerlast erhöhen, v.a. das Web of Trust. Das Web of Trust bietet dezentrale Spamvermeidung, braucht aber zur Zeit noch viel Rechenzeit. Wenn ihr keine öffentlichen Pseudonyme braucht, könnt ihr es einfach aus lassen. Dann bleiben im Darknet-Modus auch Laptop-Lüfter leise :) ↩
noderef ist die Kurzform von Node Reference, also eine Datei, die auf einen Knoten des Freenet-Netzes verweist. Euer Freenet kann mit diesem Verweis versuchen, sich zu mir verbinden. Dann prüft allerdings mein Freenet, ob es auch einen Verweis auf euren Knoten gespeichert hat. Wenn ja, bestätigt es die Verbindung. Unsere Rechner wissen also, mit wem sie reden wollen und reagieren nur auf Kontanfragen, wenn sie selbst einen Verweis auf den anderen Rechner in der Liste ihrer Freunde haben. ↩
Wenn wir nicht beide online sind, wird die Nachricht normalerweise in eine Warteschlange eingereiht und übermittelt, sobald beide online sind. Das klappt aber leider nicht immer (wenn beide offline gehen, kann die Nachricht verschwinden). Uns sollte das nicht treffen, weil mein Freenet fast immer online ist. ↩
| Anhang | Größe |
|---|---|
| 2014-11-01-ueber-freenet-verbinden-mail.txt [159] | 13.53 KB |
| 2014-11-01-ueber-freenet-verbinden-mail.html [152] | 14.06 KB |
Beispiel-E-Mail mit der ich meine Freunde1 zu Freenet [80] einlade. Fühlt euch frei, sie zu verwenden und weiterzugeben - gerne auch eure eigenen Fassungen.
Freenet ermöglicht es uns, unsichtbare Nachrichten zu schreiben.2 Zusätzlich kannst du darüber mit Pseudonym3 schreiben. Warum das wichtig ist habe ich in einer Präsentation zum SUMA-award festgehalten: Freenet nutzen: Technische Lösungen für freie Kommunikation im Internet [160] (ab Folie 4 - ab Folie 7 praktische Lösungen)
Um dich mit mir zu verbinden:
Sobald ich den Text dann auch bei mir eingetragen habe, sind wir verbunden. Wir können uns von da an einfach über die Freundesseite schreiben:
Diese Nachrichten sind echt vertraulich: Niemand kann sehen was, wann oder ob wir uns geschrieben haben, weil der normale Datenaustausch von Freenet unsere Nachrichten maskiert.
¹: Wenn du willst, dass Freenet schneller ist, kannst du stattdessen "(auch) mit Fremden verbinden" wählen. Das ist nicht so sicher aber viel praktischer :) - und unsere Nachrichten sind immernoch wirklich vertraulich.
²: Hier ist der Textblock für das Textfeld auf http://127.0.0.1:8888/addfriend/ :
identity=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
lastGoodVersion==XXXXXXXXXXXXXXXXXXXXXXX
location==XXXXXXXXXXXXXXXXXXXXXXXXXX
myName=ArneBab
opennet=false
sigP256=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
version==XXXXXXXXXXXXXXXXXXXXXXX
ark.number=XXXX
ark.pubURI=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
auth.negTypes=10
ecdsa.P256.pub=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
physical.udp==XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
End
(in der E-Mail stehen anstelle der X die entsprechenden Werte)
Liebe Grüße,
Arne
PS: Klartextfassung, die du direkt in E-Mails kopieren kannst (du musst nur den Textblock durch das ersetzen, was Freenet dir unter http://127.0.0.1:8888/friends/myref.txt zeigt):
Freenet ermöglicht es uns, unsichtbare Nachrichten zu
schreiben. Es ist zwar sichtbar, dass eine Verbindung
zwischen uns besteht, aber nicht wie, wann und wofür sie
genutzt wird.
Zusätzlich kannst du darüber mit Pseudonym
schreiben. Warum das wichtig ist habe ich in einer
Präsentation zum SUMA-award festgehalten:
http://www.draketo.de/proj/freenet-funding/suma-slides.pdf (ab
Folie 4 - ab Folie 7 praktische Lösungen)
Um dich mit mir zu verbinden:
1. Lade auf https://freenetproject.org Freenet herunter
und installiere es,
2. wähle im Wizard, der dann aufgeht, „nur Freunde“¹ und
3. kopiere unter http://127.0.0.1:8888/addfriend/ den
Textblock am Ende meiner E-Mail² in das Textfeld.
4. Schick mir dann den Text, den Freenet auf dieser Seite hier
zeigt: http://127.0.0.1:8888/friends/myref.txt (häng die Datei an
eine E-Mail an oder kopier’ den Ihnalt einfach in den Text der
E-Mail)
Sobald ich den Text dann auch bei mir eingetragen habe, sind wir
verbunden. Wir können uns von da an einfach über die
Freundesseite schreiben:
* Schreiben: http://127.0.0.1:8888/friends/
* Lesen: http://127.0.0.1:8888/alerts/
Diese Nachrichten sind echt vertraulich: Niemand kann sehen
was, wann oder ob wir uns geschrieben haben, weil der normale
Datenaustausch von Freenet unsere Nachrichten maskiert.
¹: Wenn du willst, dass Freenet schneller ist, kannst du
stattdessen "(auch) mit Fremden verbinden" wählen. Das ist
nicht so sicher wie nur Verbindungen zu Freunden aber viel
praktischer :) - und unsere Nachrichten sind immernoch
wirklich vertraulich.
²: Hier ist der Textblock für das Textfeld auf
http://127.0.0.1:8888/addfriend/ :
identity=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
lastGoodVersion==XXXXXXXXXXXXXXXXXXXXXXX
location==XXXXXXXXXXXXXXXXXXXXXXXXXX
myName=ArneBab
opennet=false
sigP256=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
version==XXXXXXXXXXXXXXXXXXXXXXX
ark.number=XXXX
ark.pubURI=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
auth.negTypes=10
ecdsa.P256.pub=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
physical.udp==XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
End
Liebe Grüße,
Ich lade Leute zu Freenet ein, die ich (a) aus anderen Gruppen kenne und bei denen ich (b) nicht denke, dass sie ihren Freenet-Knoten hacken würden, um mich auszuspionieren. Dazu gehören langjährige Freunde, Arbeitskollegen, Vereinsmitglieder, Leute die ich schon lange aus Online-Spielen oder -Foren kenne, usw. Etwas Interesse für ihre Privatsphäre müssen sie logischerweise auch haben. ↩
Unsichtbare, vertrauliche Nachrichten zwischen Freunden heißen in Freenet node-to-node Nachrichten (N2NTM). Es ist bei diesen Nachrichten zwar sichtbar, dass eine Verbindung zwischen uns besteht, aber nicht wie, wann und wofür sie genutzt wird. ↩
Pseudonym heißt, dass du eine anonyme Identität hast, mit der du wiederholt schreiben kannst. Andere wissen nur, dass du beim zweiten Artikel der oder die Gleiche bist wie beim Ersten, aber nicht wer du bist. ↩
→ Kommentar [161] zu Freie Schriften – Anspruch und Wirklichkeit [162] von Gerrit.
Danke für die Zusammenfassung.
Ich würde gerne die Lizenzprobleme, die andere hier kurz erwähnt haben, nochmal hervorheben.
Wir haben zu zweit Stunden gebraucht, um auch nur eine Sammlung von 12 echt freien Schriften zu finden, die für unser Rollenspiel [163] tauglich sind.1 Und das auch nur dank Font-Squirrel.
Frei heißt dabei explizit: Kompatibel zur GNU GPL.
Am Ende läuft das alles auf BSD oder GPL lizensierte Schriften hinaus. Alles mit einer Custom-Lizenz ist no-go. „Freeware-Schriften“ (will heißen „gefunden aber keine Lizenz auffindbar“) gehen auch nicht.
Ich habe bei einer von denen mal selbst recherchiert und das Ergebnis war, dass der Autor sagte „nutzen ja, aber weitergeben auf keinen Fall“…. Will heißen: Tolle Schrift gefunden, tolle Schrift gelöscht. Zum Glück noch nicht im Versionsverwaltungssystem eingecheckt, sonst hätte ich echte Probleme gehabt (Paranoia zahlt sich aus)…
Im Endeffekt fehlten dann bei dem echt freien Hattori Hanzo noch deutsche Umlaute und das „ß“, so dass ich selbst Hand anlegen musste - als Hobby-ist leider keine ganz einfache Aufgabe, und ich bin sicher, dass Schriftkennern direkt auffallen wird, dass das „ß“ nicht perfekt in den Schriftstil passt.
Aber wir brauchten nutzbare, schöne und lesbare Schriften, und die ganzen MS core- und Apple-„ist doch toll, wenn eure Nutzer auch einen Mac haben“-Schriften sind leider zwar hochqualitativ aber unfrei und damit noch stärker no-go als Schriften mit unklarer Lizenz.
→ Kommentar zum Artikel Open Source ist tot [165] von Stefan Wienströer, in dem er sich über anmaßende Benutzer beklagt, die von ihm gratis Telefonsupport fordern….
Hi Stefan,
Lass dich bitte von so ein paar Idioten nicht unterkriegen. Wenn ich ein Programm geschrieben hätte, das so viele Leute toll finden, dass sogar Leute dabei sind, die Telefonsupport wollen, würde ich einfach antworten: „Du willst Telefonsupport? Kein Ding: 20€ die Stunde, dann machen wir das. Verfügbar Montags und Donnerstags 18:30 bis 20:00 Uhr“.
Die Leute kriegen schließlich auch was dafür, und wenn du erstmal so weit bist, dass Leute dein Programm kommerziell einsetzen, hast du einen Weg, um damit Geld zu verdienen: Für diejenigen ist es dann nämlich bares Geld wert, dass dein Programm immer besser wird.
Ich hatte allerdings gerade die andere Situation: Ich schreibe mit ein paar anderen ein freies Rollenspielsystem und wollte zum Gratisrollenspieltag einen Flyer dazu rausbringen. Da ich selbst schlecht die ganzen Druckkosten stemmen konnte, habe ich einfach rumgefragt, ob mich jemand unterstützen könnte und binnen 4 Tagen waren über 200€ an Spenden zusammen.
Klar ist das nicht genug, um davon zu leben, aber es zeigt, dass Leute bereit sind, freie Projekte mit Geld zu unterstützen: 1w6.org/flyer/graswurzel2012 [166]
Und ich stehe damit nicht alleine: Drei weitere Hobby-Rollenspielentwickler haben das auch gemacht und ähnliche Unterstützung erlebt.
Im Endeffekt denke ich, dass freie Software einfach andere Finanzierungsstrukturen braucht. Vielleicht ein halbjährliches Projekt bei Startnext, um die nächste Entwicklungsphase zu finanzieren.
Das ist zum Beispiel, wie sich pypy finanziert: Sie sammeln Spenden für große neue Features (aktuell: automatische parallelisierung, numpy, python3 - alle drei wurden gestartet, nachdem sie zu 30% finanziert waren): pypy.org/py3donate.html [167]
Klar, dafür braucht man eine kritische Masse. Aber um die zu erreichen, ist freie Lizensierung vermutlich der beste Weg.
"Mit dem GNU Hurd können Nutzer alles in ihrem System ändern, das niemand anderen beeinträchtigt."
Und das ist eine Möglichkeit, Freiheit in einer Gemeinschaft zu definieren: "Mach was du willst, solange du damit niemand anderem schadest."
Im Gegensatz dazu benötigen die meisten aktuellen Systeme (GNU/Linux, MacOSX, Windows, ...) root Zugang um z.B. ein neues Dateisystem zu installieren.
Bevor der Einwand kommt: Ich kenne FUSE, und ja, damit ist auch vieles möglich. Der Unterschied ist, dass FUSE auf Linux aufgesetzt ist, während translators im GNU/Hurd tief in's Design integriert sind. D.h. sie fühlen sich deutlich eleganter an. Und inzwischen können sie auch in Lisp geschrieben werden :)
Zusätzlich ermöglichen es subhurds, Prozesse in Umgebungen mit anderen Rechten zu starten, so dass z.B. gefährliche Programme abgeschottet werden können.
Und ich kann einem Programm, das bestimmte Rechte braucht, diese Rechte einfach geben während es läuft (addauth -p PID -g GRUPPE). "Verdammt, ich bin nicht in der Drucker-Gruppe" => "sudo addauth -p APP -g printer".
Ich selbst hacke nicht auf Kernelebene (eigentlich sollte hier kein "noch" rein, aber das Leben spielt manchmal seltsame Spiele ´;) ), aber ich starte meine Rechner nicht allzu gerne neu, und ich mag es, einfach ein neues Dateisystem mounten zu können, und ich mag auch einige der verrückteren Dinge, die mit dem GNU/Hurd möglich sind (Ideen für Nischen [168]).
Was ich bisher im GNU/Hurd mache ist v.a. Zeug wie die Suche nach Nischen für den Hurd [168] (mit vielfachem Dank an das KDE Marketing Team [169], von dem ich einige der Dinge gerlernt habe, die ich hier nutze! Schaut doch mal bei ihnen vorbei [170]) und der Hurd GSoC 2008 code_swarm [171].
Meine Freiheit ist mir wichtig, im Leben und in Tech, und der GNU/Hurd ist ein Schritt in Richtung Freiheit.
-> GNU/Hurd [172]
Das eigentlich Schlimme an DRM (Digitaler Rechte Minimierung) ist nicht (nur), dass es vielleicht Inhalte geben könnte, bei denen der Künstler entscheidet, wie sie genutzt werden dürfen, sondern dass zur Umsetzung von DRM der Computer mit dem die Inhalte genutzt werden können, vollständig kontrolliert werden muss.
Und damit müssen alle Computer vollständig kontrolliert werden, damit bei ein paar Inhalten die Künstler komplett kontrollieren können, was mit ihnen passiert.
Werden sie das nämlich nicht, dann wird das DRM immer umgangen werden, und sei es durch den Anschluss eines Kassettenrekorders an den Audioausgang (auch das planen sie übrigens zu verhindern. Dann haben Computer keine normalen Audioausgänge mehr, sondern nur noch digitale Ausgänge, bei denen bei jedem Vorgang erst geprüft wird, ob das Gerät auch für die Nutzung mit diesem Rechner und diesen Inhalten zugelassen ist).
Und das Recht, darüber zu bestimmen was ich tun kann, sollte eigentlich niemand haben.
Es geht aber noch einen Schritt weiter.
Wenn nämlich DRM implementiert wird, dann darf es keine freien Geräte mehr geben, die sich auf irgendeine Art mit einem unfreien Gerät verbinden können. Das heißt: Damit DRM funktioniert muss es illegal gemacht werden, mit GNU/Linux an geschützte Medieninhalte zu kommen (weil die Lizenz unter der der größte Teil von GNU/Linux steht, die GNU Public License, es nicht erlaubt, dem Nutzer bestimmte Nutzungsmöglichkeiten der Software zu verbieten).
Also muss Freie Software von jeglicher "geschützter" Kommunikation ausgeschlossen werden, zum Beispiel indem es verboten wird, Inhalte mit anderen als den erlaubten Programmen zu öffnen.
Also dürfte ich irgendwann keine Word Dokumente mehr öffnen.
Oder könnte nicht mehr ins Internet, weil der "geschützte" Server mich nicht mehr verbinden lassen würde.
Und wenn dir das als unrealistisch erscheint, dann schau einfach, wieviele Leute trotz offensichtlicher Einschränkungen immernoch Windows verwenden.
Zur Zeit haben die großen Medienfirmen alle Macht auf ihrer Seite, um DRM zu verbreiten, und auch „schwaches DRM“ lässt sich nicht integrieren, ohne auf lange Sicht zur vollständigen Kontrolle des Rechners zu kommen (ich denke, die PR Techniken um dahin zu kommen, kannst du dir selbst vorstellen).
Kurz: Jede wie auch immer geartete DRM-Technik wird am Ende die vollständige Kontrolle von privaten Computern nach sich ziehen.
Daher muss DRM meiner Meinung nach schon jetzt gestoppt werden.
Und als Alternative zu massivem DRM Einsatz sehe ich die Kulturflatrate als effektives und faires Vergütungsmodell für Musik, die meiner Meinung nach genau das leistet, was ich von ihr erwarte. Sie sorgt dafür, dass
* Ich unkompliziert an die Musik komme, die ich will, und
* Die Künstler, die ich höre, Geld bekommen.
Und das mit minimal möglichem Aufwand, denn das Mitschneiden von Downloadzahlen ist nicht wirklich schwer (wird z.B. von BigChampagne schon gemacht:
http://www.bigchampagne.com/ [173] ).
Die Aufgabe der Plattenfirmen wird dann wieder werden, die Spreu vom Weizen zu trennen und Stars nicht mehr zu machen, sondern zu finden. Denn dafür zahle ich auch gerne mal was (z.B. ein Abodienst, in dem man Infos zu guten Bands bekommt, von einer Privatperson betrieben, die damit ihren Lebensunterhalt verdient).
Der Weg dahin geht meiner Meinung nach übrigens auch über freie Lizenzen [27], weswegen auch jedes meiner Textschnipselchen auf dieser Seite unter freien Lizenzen steht.
Damit zahlen dann Musikhörer, weil sie Musik gut finden, die sie gehört haben und weil sie wollen, dass die Künstler noch mehr gute Musik produzieren.
Ja, dafür muss sich unsere Konsumkultur ändern.
Und ja, ich glaube, dass das nicht nur möglich ist, sondern auch passieren wird, wenn wir es schaffen zu vermeiden, in eine komplette Kontrollgesellschaft zu geraten, egal ob die Kontrolle vom Staat kommt oder von mächtigen Firmen (wobei mir in einer Demokratie der Staat lieber ist. Dessen Macht wird immerhin noch halbwegs durch Wahlen legitimiert).
Gentoo ist die GNU/Linux Distribution meiner Wahl: http://gentoo.org [174]
Es gibt mir Flexibilität, installiert aus den Quellen und seine Paketverwaltung (Portage) baut auf Python auf.
Und es hat mich noch nie so kalt erwischt wie das ppc Kubuntu das ich meiner Frau installiert habe ("da muss man nicht dran rumbasteln"), das ich gerade nach dem zweiten dist-upgrade Komplettcrash (mit jeweils 4-6 Stunden Aufwand um es wieder zum Laufen zu bringen) durch ein Gentoo ersetze (das im Gegensatz zu meinem nicht auf Spielereien sondern auf Stabilität gebaut wird).
Um mein Gentoo mit minimalem Wartungsaufwand aktuell zu halten verwende ich tägliche und wöchentliche Cron-Scripte.
Das tägliche Update läuft über pkgcore [175], um wichtige Sicherheitsupdates zu installieren:
pmerge @glsa
Damit installiert mein Rechner die Gentoo Linux Security Advisories, d.h. die wichtigsten Sicherheitsupdates (Damit das Script läuft brauchst du pkgcore: "emerge pkgcore")
Anmerkung: Es könnte sinvoll sein, den lafilefixer zu diesen Skripten hinzuzufügen Quelle [176]).
Das folgende Skript ist mein tägliches update (in /etc/cron.daily/update_glsa_programs.cron )
\#! /bin/sh
\### Update the portage tree and the glsa packages via pkgcore
\# spew a status message
echo $(date) "start to update GLSA" >> /tmp/cron-update.log
\# Sync only portage
pmaint sync /usr/portage
\# security relevant programs
pmerge -uDN @glsa > /tmp/cron-update-pkgcore-last.log || cat \
/tmp/cron-update-pkgcore-last.log >> /tmp/cron-update.log
\# And keep everything working
revdep-rebuild
\# Finally update all configs which can be updated automatically
cfg-update -au
echo $(date) "finished updating GLSA" >> /tmp/cron-update.log
Und hier ist mein aktuelles wöchentliches Cron (in /etc/cron.weekly/update_installed_programs.cron):
\#!/bin/sh \### Update my computer using pgkcore, \### since that also works if some dependencies couldn't be resolved. \# Sync all overlays eix-sync \## First use pkgcore \# security relevant programs (with build-time dependencies (-B)) pmerge -BuD @glsa \# system, world and all the rest pmerge -BuD @system pmerge -BuD @world pmerge -BuD @installed \# Then use portage for packages pkgcore misses (inlcuding overlays) \# and for *EMERGE_DEFAULT_OPTS="--keep-going"* in make.conf emerge -uD @security emerge -uD @system emerge -uD @world emerge -uD @installed \# And keep everything working emerge @preserved-rebuild revdep-rebuild \# Finally update all configs which can be updated automatically cfg-update -au
Ich habe gestern die Installation von Gentoo auf dem iMac meiner Frau begonnen.
Gestern habe ich die 2008.0 Universal-CD gebrannt und den iMac damit gebootet, die letzten 15 Minuten habe ich damit zugebracht, den "Gentoo" Eintrag auf meiner Seite zu schreiben, also sind wir gerade bei etwa
T=30 Minuten
Der tar-ball ist ausgepackt. Ich formatiere die Platten nicht neu - vielleicht kann ich so die Daten aus Kubuntu erhalten (ja, ich habe ein Backup der wichtigen Daten). update: Hat geklappt. Alle Daten sind noch da.
Bisher hat alles reibungslos geklappt - das einzige Manko ist, dass in den docs noch lynx als Browser empfohlen wird, die CD aber stattdessen links2 hat. Muss ich noch einen Bugreport aufmachen.
T ~ 60 Minuten
Alle vorherige Kubuntu Software entfernt (rm -r /usr /lib /lib64 ..., /home ausgespart!), den stage tarball und portage snapshot installiert, changeroot ausgeführt, portage aktualisiert und die notwendige Konfiguration geschrieben - es wird ein Desktop Profil.
Jetzt kommt der Kernel.
T ~ 2 Stunden
Ich habe statt dem Befehl "genkernel -genzimage all" einfach "genkernel all" genutzt, weil der erste nicht funktioniert hat. Vielleicht ein Bug in der Anleitung?
Von der Stunde musste ich selbst nur etwa 10 Minuten was machen, den Rest hat der Rechner mit zweimal kompilieren des Kernels verbracht (einmal falsch wegen hoffentlich falschem Befehl).
T ~ 4 Stunden
Es war nicht mehr allzu viel zu tun. yaboot wollte mit "yaboot -b /dev/hda2" gestartet werden, weil meine apple bootpartition auf /dev/hda2 liegt.
Dann habe ich noch die locale eingestellt (/etc/locale.gen braucht "de_DE.UTF-8@euro UTF-8", damit /etc/env.d/02locales "de_DE.utf8@euro" nimmt).
Ein bisschen musste ich noch Programme bauen, aber das macht mein Rechner ohne dass ich ihn überwachen muss.
Ich muss aktuell noch beim booten "Linux video=ofonly" eingeben, wenn ich die Konsolen sehen will, weil ich noch nicht den richtigen Grafikmodus habe. Ich hoffe, ich kann das bald fixen. Bis dahin stört es nicht. Der X-Server funktioniert und kdm wird sauber angezeigt, sobald der Rechner fertig gebootet ist.
Und jetzt gerade läuft das "emerge -uDN world", um alle bisherigen Programme zu aktualisieren. Als nächstes werden dann xorg-x11 und kde-meta emerged :)
Erstmal wird es noch kde 3.5.x, weil 4.1.2 für ppc noch nicht in testing ist.
Update: Inzwischen läuft alles. Ich musste noch ein paar Programme nachinstallieren (z.B. Firefox und OpenOffice), aber damit ist die Installation abgeschlossen. Alle alten Daten und KDE Einstellungen funktionieren weiterhin, trotz der Neuinstallierung.
Die gesamte Installation hat etwa 2 Tage gedauert - davon alles bis auf die ersten 4 Stunden und etwas Konfiguration (z.B. X via xorgcfg und WLAN) reine compile-Zeit.
Was meiner Frau noch fehlte waren gimp, openoffice, mozilla-firefox und k3b. Ich brauchte noch sudo, screen, cfg-update, eix, euses, gentoolkit und portage-utils. :)
WLAN habe ich über net-wireless/b43-fwcutter , net-wireless/bcm43xx-fwcutter und wpa_supplicant zum Laufen bekommen. Glücklicherweise hatte ich von meiner alten installation noch eine Kopie der Apple WLAN Firmware auf der Platte.
Update 2009-07: xorg braucht für Tastatur und Maus jetzt x11-drivers/xf86-input-evdev.
Update: Infos zur installation von WLAN auf den alten G3 iMacs Flatscreen gibt es im Gentoo Wiki [177].
Ich habe mein Haupt-Tastaturlayout auf Neo [178] umgestellt und die Tastatur umgebaut [179]. Da ich etwas suchen musste, bis ich herausgefunden habe, wie ich es auch in KDM das Neo-Layout nutzen kann, schreibe ich es hier.
Damit das hier funktioniert, musst du "evdev" als Tastaturtreiber nutzen.
Als ersten Schritt muss eine Tastaturlayout-Dateien in /etc/hal/fdi/policy/ sein. Wenn da keine keymapfdi Datei liegt, kopier dazu einfach den folgenden Befehl in die Konsole [180]:
sudo cp /usr/share/hal/fdi/policy/10osvendor/10-keymap.fdi \
/etc/hal/fdi/policy/
Dann schau in die Datei /etc/hal/fdi/policy/10-keymap.fdi und änder die Zeilen
<merge key="input.xkb.layout" type="string">de</merge> <merge key="input.xkb.variant" type="string" />
so dass sie das folgende enthalten (nur die zweite ist geändert):
<merge key="input.xkb.layout" type="string">de</merge> <merge key="input.xkb.variant" type="string">neo</merge>
Voilà, dein X-Server fängt jetzt mit dem Neo-Layout an, und auch KDM nutzt das Neo Layout.
Ausführlichere Informationen und Hintergrund gibt es im Gentoo Leitfaden zum Xorg 1.5 update [181].
Effektiv heißt es: Du verwendest jetzt die Neo-Variante.
Notiz: Damit das hier funktioniert, musst du Neo bereits installiert haben. Falls du es noch nicht hast, findest du im Neo-Wiki einen Beitrag zum installieren und einrichten von Neo unter GNU/Linux [182].
Vorsicht: Um nicht am Ende mit nicht-eingebbaren Passwörtern dazusitzen, solltest du dir für den Anfang entweder vorher ein Neo-Layout ausdrucken (zum Beispiel den Aufsteller [183]), oder deine Tastatur umbauen, damit du nachschauen kannst, wo die Tasten liegen, falls du es mal vergessen solltest.
Entwurf eines einfachen Systems um Identitätsdiebstahl durch Übernahme von Login-Accounts zu verhindern: Lade beim Anmelden deinen öffentlichen GnuPG Schlüssel hoch. Wird dein Acount übernommen, weist du deine Identität mit einer signierten E-Mail nach.
Durch OpenID wird es Stück für Stück unnötig, sich hunderte Passwörter und Nutzernahmen zu merken.
Gleichzeitig wird aber auch ein einzelner Login immer wichtiger, und ich kann schon mit der Übernahme eines einzelnen OpenID Accounts auf hunderten anderer Seiten die Identität des bestohlenen Nutzers annehmen.
Ganz verhindern können wir die Account-Übernahme nicht, denn im allgemeinen gilt, dass die Sicherheit eines Systems nur um den Preis geringerer Bequemlichkeit gesteigert werden kann.
Also konzentrieren wir uns auf den nächsten Schritt: Der Account wurde übernommen und das Passwort geändert. Jetzt will ich dem Anbieter nachweisen, dass ich derjenige bin, der den Account erstellt hat.
Statt nun irgendein neues System aufzusetzen, nutzen wir einfach ein bekanntes und sicheres: GnuPG: Gnu Privacy Guard [76].
Dabei hat jeder einen privaten und einen öffentlichen Schlüssel. Der öffentliche Schlüssel kann, wie der Name schon sagt, einfach veröffentlicht werden, ohne dass die Sicherheit des Nutzers leidet. Wer den öffentlichen Schlüssel hat, kann verschlüsselte E-Mails an den Besitzer des privaten Schlüssels schicken, und er kann digitale Unterschriften des Besitzers des privaten Schlüssels prüfen.
Wenn nun mein Account gestohlen wurde, kann ich einfach eine mit meinem privaten Schlüssel unterschriebene Mail an den Seitenbetreiber schicken und sagen "mein Account ist kompromittiert. Bitte geben sie mir neue Login-Informationen." Der Seitenbetreiber prüft dann meine digitale Unterschrift mit dem öffentlichen Schlüssel, den ich hinterlegt habe. Wenn sie gültig ist, erstellt er neue Login-Infos (und schickt sie mit meinem öffentlichen Schlüssel verschlüsselt an mich).
Die Abfrage kann problemlos automatisiert werden, so dass nichtmal ein Mensch auf der Seite des Anbieters sitzen muss, das System also gut hochskaliert.
Da der private Schlüssel mit einem Passwort geschützt ist, gibt auch die kurzzeitige Übernahme des Computers nicht direkt die Möglichkeit, Accounts zu übernehmen.
Dazu kommt, dass GnuPG seit Jahrzehnten im Einsatz ist und von den verschiedensten Sicherheitsexperten geprüft wurde - von anonymen Hackern bis zum Bundesamt für Sicherheit in der Informationstechnik (das GnuPG sogar eine Weile lang unterstützt hat). Und auch das BKA hat letztens herausgefunden, dass GnuPG wirklich sicher sind, als sie sich an GnuPG verschlüsselten Dateien die Zähne ausgebissen haben [184].
Wir sollten es nutzen, um unsere elektronische Identität zu schützen.
Schau es dir doch mal an [185]. Vielleicht hast du ja Lust das System zu erstellen :)
Verschiedenes über das K Desktop Environment [186], oder wir auch immer du KDE nennen willst, denn es ist inzwischen weit mehr als ein Desktop.
Meine Alternativen sind bisher:
Oder in Langform:
Und das passt für mich sehr gut.
Aber was ist es nun? Am einfachsten finde ich den Satz: „KDE ist das, was ich von meinem Rechner sehe, wenn ich nicht in die Konsole tauche.“
Doch wie gesagt: Es ist weit mehr als das. Das sieht der Normaluser allerdings zum Glück kaum. Die wichtigste Eigenschaft von KDE ist für mich, dass Ich damit gut arbeiten kann, und dass es das tut, was ich von ihm will.
Ich teste nun schon länger KDE 4, aber erst heute ist es meine Normalumgebung geworden.
Es hat noch einige Macken, aber es fühlt sich so viel angenehmer an, dass ich nicht mehr zurück zu KDE 3.5 will.
Gut, ich kann noch keine Mails abrufen, so dass ich doch dann und wann zurück müssen werde, aber ich habe vor ab jetzt alles mit KDE 4 zu machen, das damit bereits geht, denn ich fühle mich einfach wohl darin.
Ich habe es mir in meinem Gentoo installiert, sobald KDE 4.0 verfügbar war (es war fertig um 22:31:34 am 22.01.2008), und vorher häufiger die Subversion Version getestet.
Und der Unterschied von der SVN Version zum Release ist gewaltig!
Als Fazit kann ich aber einfach sagen, dass sich KDE 4.0 noch mal sehr viel glatter und angenehmer anfühlt als KDE 3.5, und das Amarok2 Preview läuft :)
Der Unterschied ist ähnlich gewaltig, wie der als ich damals von MacOS9 auf MacOSX gewechselt bin, und ich habe das Gefühl, dass es mir den Komfort wiedergibt, den ich damals aufgegeben habe, als ich von Mac weiter zu Linux gewechselt bin, weil mir Apple meine eigenen Entscheidungen zu sehr eingeschränkt hat (was ist der SInn dahinter Configdateien binär zu machen, außer den Nutzer an Änderungen zu hindern?).
Viel Spaß beim Testen, falls auch ihr einen Blick auf KDE 4 werfen wollt!
Für den Fall, dass es euch interessiert, wie es bei mirnun aussieht, habe ich euch einen Screenshot angehängt: KDE4.0 mit Systemsettings und Dolphin [187].
Ich habe die Fraben auf "Stone Orchid" umgestellt (etwas dunkler), weil ich damit die Fensterrahmen angenehmer finde und das Gefühl habe, besser damit arbeiten zu können.
Ansonsten ist es ein Standard KDE 4 Desktop mit Systemsettings und Dolphin.
Aber erinnert euch daran, dass die Programmierer sagen, dass es noch nicht für den Produktiveinsatz genutzt werden sollte - ich werde mich auf jeden Fall daran erinnern, wann immer Fehler auftreten. :)
Viel Spaß!
| Anhang | Größe |
|---|---|
| 2008-02-06-fullscreen-settings-dolphin.png [187] | 522.48 KB |
Gestern (und vorgestern) hat mein KDE 4.1 rc1 problemlos gebaut, und ich habe nun einen wundervollen Desktop vor mir, und den möchte ich euch nicht vorenthalten.
Klickt auf das Bild, um es in voller Schönheit (und Auflösung) zu sehen :)
 [188]
[188]
Abgesehen von dem tollen Aussehen scheint auch so gut wie alles zu funktionieren, obwohl ich Kontact noch nicht eingerichtet habe und deswegen darüber noch nichts sagen kann (ich will KDE4 erstmal zum Arbeiten haben, und davon halten mich Mails zu effizient ab :) ).
Einziges Manko bisher: Plasma widgets aus dem Netz laden funktioniert noch nicht.
Aber der Arbeitsfluss ist klasse, und ich hätte nicht gedacht, das Folder-View so praktisch ist!
Nebenbei: Installiert in Gentoo via Portage (Overlay) [189].
| Anhang | Größe |
|---|---|
| 2008-06-24-desktop.png [188] | 559.04 KB |
| 2008-06-24-desktop-small.png [190] | 109.65 KB |
Ich dachte, es wäre mal wieder an der Zeit für einen aktuellen Screenshot:
 [192]
[192]
Klick einfach auf das Bild, um es in voller Größe und Schönheit zu sehen :)
Was ich nutze:
Mit den Plasmoids:
Die Hintergrund-Farbe ist #2E3436 (aus der Oxygen Palette).
| Anhang | Größe |
|---|---|
| screenshot-dragons-ghost-gpl.png [192] | 777.12 KB |
Und mal wieder ist es Zeit für einen Screenshot, diesmal von KDE SC 4.5 release candidate 1 [199]:
 [200]
[200]
Klick einfach auf das Bild, um es in voller Größe und Schönheit zu sehen :)
Im Gegensatz zu meinem Screenshot von KDE 4.3.3 [201] nutze ich diesmal fast nur Standardeinstellungen, weil ich wieder stärker sehen will, wie sich das Standard-KDE entwickelt.
„Quell“ und „Projekte“ sind Ordneransichten, in denen ich Aliase (symlinks) zu meinen meistzugegriffenen Ordnern angelegt habe. In Quell sind das Ordner zu wichtigen Kategorien meiner Ordnerstruktur (Quell ist auch mein Startordner in Dolphin) und in Projekte zu Projekten, an denen ich aktuell arbeite.
Der Hintergrund ist wieder das Drachen-Wallpaper [202] auf Grundlage des Logos, das Trudy Wenzel [203] für das freie 1w6-System [163] gezeichnet hat (andere Auflösungen: 800x600 bis 2560x1600 [204]) mit #000433 als Hintergrundfarbe.
Das Bild unten rechts ist das „Bilderrahmen“ Plasmoid und stammt ursprünglich aus Battle for Wesnoth [205], einem freien Strategiespiel. Alle 5 Minuten wechselt das Bild zufällig zu einem der Wesnoth-Bilder, die wir für das freie 1w6-Rollenspielsystem verwenden [206] (1w6-System [163]).
Unten links ist das Plasmoid „Wetterbericht“, eingestellt auf ‚Mannheim, Baden-Württemberg (google)‘.
Unten rechts dann „Notizen“, und in der Mitte über der Hüfte des linken Drachen „Luna“, das mir immer die aktuelle Mondphase anzeigt (weil ich das einfach interessant und schön finde).
Schlussendlich ist noch die Kontrollleiste etwas schmaler, weil ich so stärker das Gefühl habe, dass sie eine Interaktionsstruktur ist (und ich dadurch Programmfenster nach links unten schieben kann, so dass sie von keinen anderen überlappt werden – fürs Verschieben von Dateien sehr praktisch :) ).
Die Icons sind einfach Standard-Oxygen.
Installiert ist das ganze über den kde-testing-overlay [207] in Gentoo [174]: emerge layman && layman -a kde && emerge @kde-4.5
Den Screenshot habe ich mit ksnapshot gemacht: Alt-F2 → ksnapshot.
Und das wars auch schon – ich hoffe, die Infos waren interessant für dich! Wenn ja, würde ich mich über einen Kommentar [208] freuen! (und sei er nur „schönes setup“ :) ).
Viel Spaß mit KDE [186]!
| Anhang | Größe |
|---|---|
| 2010-06-30-plasma-drak.png [209] | 879.52 KB |
| 2010-06-30-KDE-4.5-rc1-plasma-drak.png [200] | 879.52 KB |
| 2010-06-30-KDE-4.5-rc1-plasma-drak-small.png [210] | 144.16 KB |
Hier finden sich Sachen zu KDE in Gentoo.
update: kdelibs 4.3.1 sind jetzt amd64 stable. Damit ist KDE 4.3 die Standard-KDE-Version in Gentoo.
-> http://gentoo-portage.com/kde-base/kdelibs [211]
Inzwischen ist KDE 4.1 im portage tree.
-> http://forums.gentoo.org/viewtopic-t-708282.html [212]
In den Gentoo Foren:
Um KDE 4.1 (und spätere via SVN) in Gentoo zu testen, nutzt einfach layman, wie im Forum Thread beschrieben.
Dann viel unmasken und keyworden...
English alternative: My favourite Scheme feature: named let [214]. With more implementation details.
Ich habe dank Pythonista in Scheme-Land [215] von Let-Rekursion [216] gelesen. Bis vorgestern fand ich sie noch sinnlos kompliziert.
Das hat sich alles geändert, als ich wirklichen Code damit geschrieben habe - zum Beispiel die Fibonacci-Folge (syntax: wisp [217]1 für Guile Scheme [218]2) (eigentlicher Augenöffner [219]):
define : fib n let rek : (i 0) (u 1) (v 1) if : >= i : - n 2 . v rek (+ i 1) v (+ u v) ; else
Um Let-Rekursion zu beschreiben, werde ich diese Funktion jetzt zu einer Schleife in Python transformieren und mich zu immer eleganteren Formulierungen vortasten, bis ich wieder bei dem gerade gezeigten Code bin; dann aber mit Hintergrundwissen darüber, wodurch er elegant wird, mit dem Verständnis, was genau er tut, und mit einem Gefühl dafür, wie viel diese Eleganz ausmacht - und warum sie erstrebenswert ist.
Da ich selbst bis vor 2 Tagen nicht wirklich verstanden hatte, was Let-Rekursion ist und was sie bringt, will ich sie erklären.
Ich versuche an einem einfachen Beispiel zu beschreiben, wie sie funktioniert und was sie so besonders macht: Nehmen wir ein Programm, das Glieder aus einer Fibonacci-Folge berechnet. Die 1. Zahl ist eins, die 2. ist eins, die 3. ist die 1. + die 2., die vierte ist die 2. + die 3., usw.
\(f_n = f_{n-1} + f_{n-2}\) für \(n \geq 2\) mit \(f_1 = f_2 = 1\)
Meine Beispiele sind in Python [220] (meiner „Muttersprache“), solange sich die Funktionalität in Python abbilden lässt.
In Schleifen-Notation würde die Fibonacci-Funktion z.B. so aussehen:
def fib(n): if n in (1, 2): return 1 u = 1 v = 1 for i in range(n-2): tmp = v v = u+v u = tmp return v
Hier sehen wir deutlich, wie viel unnötiger Code benötigt wird (boiler plate): tmp, for, n= und v=.
Versuchen wir das also rekursiv:
def fibrek(n, i=0, u=1, v=1): if i >= n-2: return v return fibrek(n, i+1, v, u+v)
Das ist schon viel kürzer, aber dafür haben wir keine klare API mehr: Wer diese Funktion von außen nutzt, sieht Parameter, die eigentlich nicht genutzt werden sollten. Und das kann Verwirrung stiften, was Fehler provoziert.
Um das API-Problem zu beheben können wir in Python eine Hilfsfunktion verwenden:
def _rek(n, i, u, v): if i >= n-2: return v return _rek(n, i+1, v, u+v) def fibrek2(n): return _rek(n, 0, 1,1)
Jetzt haben wir wieder eine saubere API der Funktion, aber eine im ganzen Modul sichtbare Hilfsfunktion, die nur in einer einzigen echten Funktion genutzt wird. Das Ergebnis ist ein vollerer Namensraum, der wieder zu Fehlern führt - erst recht mit der ganzen Code-Vervollständigung, die heutzutage üblich ist.
Aber es gibt noch Hoffnung: Wir können die Hilfsfunktion innerhalb der Hauptfunktion definieren:
def fibrek3(n): def rek(i=0, u=1, v=1): if i >= n-2: return v return rek(i+1, v, u+v) return rek()
Als Besonderheit wird hier das n implizit übergeben: Die Funktion rek hat es im Namensraum, weil es zur Zeit ihrer Definition in ihrem Namensraum war.
So sieht das ganze schon sehr schön aus. Was nur noch stört ist der Funktionsaufruf rek() am Ende: Den brauchen wir eigentlich nicht. Stattdessen bräuchten wir eine Möglichkeit, einen explizit-rekursiven Abschnitt der Funktion zu definieren, der automatisch aufgerufen wird.
Und genau das ist Let-Rekursion.
Um den letzten Schritt dorthin zu gehen, muss ich allerdings wirklich auf Scheme wechseln - im Interesse der Lesbarkeit für Nicht-Schemer in wisp-syntax.1, 2
define : fib n let rek : (i 0) (u 1) (v 1) if : >= i : - n 2 . v rek (+ i 1) v (+ u v)
(Die Ähnlichkeit zum vorhin definierten Python-Code sollte klar machen, was der Code tut)
Diese Funktion hat einen sauberen Namensraum und klare Strukturen, und sie vermeidet jegliche unnötige Syntax.
Und das ist Wahnsinn.
Go Scheme!
Zum Abschluss zeige ich jetzt noch den Code, der mich dazu gebracht hat, diesen Artikel zu schreiben.
Dieser Code hat mir die Eleganz und Macht der Let-Rekursion vor Augen geführt.
Die definierte Funktion entfernt die Einrückung einer Zeile Text und gibt die Tiefe der Einrückung zurück. Anders als lstrip(), betrachtet sie Unterstriche am Anfang der Zeile als Einrückung und arbeitet auf einem port, aus dem ich nur einzelne Zeichen lesen kann.
Sie ist Teil meines (noch nicht fertigen) Whitespace-Lisp [217] Parsers in Guile-Scheme.
define : skipindent inport let skipper : inunderbars #t indent 0 nextchar : read-char inport ; when the file ends, do not do anything else when : not : eof-object? nextchar ; skip underbars if inunderbars if : char=? nextchar #\_ ; still in underbars? skipper . #t ; still in underbars? + indent 1 read-char inport ; else, reevaluate without inunderbars skipper #f indent nextchar ; else: skip remaining spaces if : char=? nextchar #\space skipper . #f + indent 1 read-char inport begin unread-char nextchar inport . indent
Den Code zu schreiben hat mir das Gefühl gegeben, frei zu sein: Keine Definitionen um der Struktur willen, sondern nur genau das, was ich brauchte - und völlig natürlich in die normale let-Syntax eingebunden, die ich schon kannte.
| Anhang | Größe |
|---|---|
| 2013-08-11-So-let-rekursion.org [222] | 6.87 KB |
| 2013-08-11-So-let-rekursion-fib.w [223] | 124 Bytes |
| 2013-08-11-So-let-rekursion-fib.scm [224] | 130 Bytes |
| 2013-08-11-So-let-rekursion-fibloop.py_.txt [225] | 143 Bytes |
| 2013-08-11-So-let-rekursion-fibrek.py_.txt [226] | 99 Bytes |
| 2013-08-11-So-let-rekursion-fibrek2.py_.txt [227] | 133 Bytes |
| 2013-08-11-So-let-rekursion-fibrek3.py_.txt [228] | 136 Bytes |
| 2013-08-11-So-let-rekursion-skipindent.w [229] | 937 Bytes |
| 2013-08-11-So-let-rekursion-skipindent.scm [230] | 972 Bytes |
Alle Inhalte auf dieser Seite sind frei lizensiert, solange nicht explizit etwas anderes dabei steht. (Warum das wichtig ist)
Das bedeutet, dass Sie meine Werke verwenden dürfen wie Sie wollen (sogar kommerziell), solange Sie anderen (und mir) das gleiche mit all den Werken erlauben, die Sie mit Hilfe meiner Werke erschaffen und dabei auch sagen von wem die Ursprungswerke kommen.
Um sie zu nutzen, können Sie beispielsweise einfach diesen Lizenztext dazulegen (z.B. als html-Seite) und einen Link darauf setzen. Alternativ schreiben Sie einfach sichtbar auf Ihr Werk:
Urheber: [Ihr Name sowie andere Beitragende] ([Jahr]) und Arne Babenhauserheide ([Jahr]). Verfügbar unter freien Lizenzen inklusive der GPLv2 or later, der cc BY-SA, der GNU FDL ohne invariante Abschnitte, Art Libre und der Lizenz für Freie Inhalte. Einzelheiten: lizenz.draketo.de [232]
Genauer bedeutet das: Meine Werke dürfen unter den folgenden freien Lizenzen genutzt werden (Ausnahme: Vollständige Programme sind nur unter der GPL verfügbar, nur von mir geschriebene Programmschnipsel unter all diesen Lizenzen). Der erste Link führt jeweils auf den deutschen Lizenztext:
(ab jetzt verzichte ich hier auf das Sie).
Programme stehen dabei nur unter der hier genannten GPL, sonstige Inhalte sind unter allen vier Lizenzen verfügbar.
Ich behalte mir die Relizensierung jeglicher Inhalte auf dieser Seite unter weitere Lizenzen vor. Allerdings müssen dafür in Frage kommende Lizenzen die weiter unten genannten grundlegenden 4 Freiheiten gewährleisten.
Ich nutze fünf Lizenzen, weil zur Zeit im Bereich freier Kultur viel geschieht und ich will, dass so viele Leute wie möglich meine Werke nutzen können. Ich kann noch nicht vorhersehen, welche der Lizenzen sich herausbilden wird. Da jede von ihnen Stärken und Schwächen hat, kann ich aktuell keiner den Vorzug geben. Ich hoffe, dass sie sich zu einer einzigen verbinden und als eine der bisherigen Lizenzen weiterleben.
Wenn Du mit meinen Werken arbeiten willst, übernimm' bitte alle vier Lizenzen. Du musst es nicht, aber du kannst damit einen Beitrag leisten, um für die Zukunft Fragmentierung zu vermeiden.
Falls Du sie unter einer anderen freien Lizenz nutzen willst, schreib mir einfach [75].
Du darfst meine Werke verwenden wie du willst (sogar kommerziell), solange du anderen (und mir) das gleiche mit all den Werken erlaubst, die du mit Hilfe meiner Werke erschaffst und dabei auch sagst von wem die Ursprungswerke kommen.
Die Werke müssen unter der jeweiligen Lizenz bleiben.
Wenn du damit arbeitest, stell' die Ergebnisse bitte unter alle vier Lizenzen, wenn es dir möglich ist (ich weiß, dass ich mich wiederhole, aber der Punkt ist wichtig, und ich möchte nicht, dass er überlesen wird).
Bei Werken völlig ohne Lizenz ist unklar, wie sie genutzt werden dürfen, und in Deutschland gilt in dem Fall erstmal, dass sie nicht genutzt werden dürfen.
Daher sollte bei jedem eigenen Werk explizit gesagt werden, welche Rechte die Nutzer des Werkes haben, vor allem im Internet, wo die Rechtslage ohne explizite Lizenzen sehr viel weniger klar ist, als in der Offline-Welt.
Und bei jedem fremden Werk sollte geklärt werden, welche Rechte man damit hat, v.a. wenn man es kauft.
Freie Lizenzen sorgen dafür, dass jede Person das Werk frei nutzen darf, solange sie dabei niemand anderem die Freiheit einschränkt. In der freien Softwaregemeinde ist das als die „4 Freiheiten“ bekannt. Ich habe sie für Texte übersetzt:
Jedes nicht frei lizensierte Werk nimmt dem Nutzer dieses Werkes und der Gesellschaft einen Teil dieser Freiheiten.
Während unfreie Software den Menschen die Freiheit der Nutzung ihres Computers einschränkt, nehmen ihnen unfreie Kulturelle Werke die Freiheit der Nutzung ihrer kulturellen Umgebung, und damit einen Teil der Freiheit gemeinsamen Denkens und Schaffens.
Daher gibt es auf meiner Seite seit dem Neudesign nur noch frei lizensierte Werke. Ich will nicht verantwortlich dafür sein, dass Andere Teile ihrer Freiheit aufgeben.
Viel Spaß beim freien Bearbeiten meiner Werke!
Einschränkung: Ich bin (leider) so pragmatisch, dass ich dieses Prinzip wohl verletzen würde, wenn ich meinen Lebensunterhalt mit meinen Werken verdienen müsste und merken würde, dass es mit diesen Prinzipien nicht geht.
Daher kämpfe ich jetzt dafür, dass es irgendwann jedem möglich ist, mit freien Werken seinen Lebensunterhalt zu verdienen (zum Beispiel, weil niemand mehr unfreie Werke kauft). So kann ich es vielleicht mir, zumindest aber Anderen in der Zukunft ermöglichen, dass sie ihren Lebensunterhalt ethisch richtig verdienen. - Zwillingsstern alias Arne Babenhauserheide alias Draketo
Explizit ist das die folgende zusätzliche Erlaubnis: As additional permission under GNU GPL version 3 section 7, you may distribute these works without the copy of the GNU GPL normally required by section 4, provided you include a license notice and a URL through which recipients can access the Corresponding Source and the copy of the GNU GPL. ↩
→ Geschrieben auf heise.de [241].
GPL: Freie Werke von Beitragenden auf Augenhöhe.
BSD: Vogelfreie Werke von Schenkenden.
Sowohl in BSD-Lizenzen als auch in der GPL steht „die Lizenz dieses Teils muss erhalten bleiben“.
BSD [242] Lizenzen sagen „mach was du willst, lass nur hier den Lizenzheader drin.“ International heißt das „Permissive“, präziser wäre „Lax“.
Die GPL [243] sagt „mach was du willst, aber du musst das, was du daraus machst, unter die gleiche Lizenz stellen.“ International heißt das „Copyleft“.
(das war die Kurzform - der Rest sind rechtlich notwendige Details um das zu ermöglichen)
Wenn ich etwas veröffentliche, dann unter der GPL, denn wenn jemand von meiner Gratisarbeit profitiert, um etwas eigenes zu schaffen, dann will auch ich wieder von dem profitieren, was er daraus erstellt.
Und da potenziell hunderte von Leuten daran arbeiten (siehe Wikipedia), genügt ein "ich will dann auch" nicht, sondern muss ersetzt werden durch "alle Nutzer haben die gleichen Rechte wie der ursprüngliche Autor".
Bei der GPL stehen sich alle Autoren auf Augenhöhe gegenüber. Alle haben die gleichen Rechte. Das nennt sich dann „freie Werke“ – sie sind frei und sie bleiben frei.
Bei BSD Lizenzen stellen sich die Autoren als Schenker hin, die am Ende oft die Gelackmeierten sind, weil viele Leute nichts zurückgeben.1 Das nennt sich "vogelfreie Werke" - sie sind vogelfrei und jeder kann sie einfach nehmen.
Die OpenBSD-Leute haben sogar ein Lied, in dem sie sich darüber beklagen, dass andere sich der BSD-Lizenz entsprechend verhalten: "100001 1010101" [244] (beachtet den Comic neben dem Text) — das Lied ist klasse, und der Comic zeigt schön das Problem von Vogelfreien Lizenzen: Am Ende regen sie sich doch auf, wenn jemand etwas nimmt, ohne etwas zurück zu geben. ↩
Dank dem GNU Head redrawn [245] und Neo-Tastatur.de [246] habe ich eine Tastatur, die meine Begeisterung für freie Software zeigt: Mit GNU [247], Plussy [4] und Infinite Hands [248]. Außerdem enthält sie die für wissenschaftliches Schreiben praktischen mathematischen und griechischen Zeichen, die Neo [178] bietet. Aber genug geschrieben: Geben wir der Tastatur das Rampenlicht, das sie verdient ;-)

 [249]
[249]
 [250]
[250]
 [251]
[251]
| Anhang | Größe |
|---|---|
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-0.JPG [252] | 26.38 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-1.JPG [249] | 75.8 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-2.JPG [250] | 129.51 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-3.JPG [251] | 104 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-1-thumb.JPG [253] | 42.36 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-2-thumb.JPG [254] | 37.49 KB |
| neo-tastatur-mit-gnu-plussy-und-infinite-hands-3-thumb.JPG [255] | 28.82 KB |
Mercurial [256] ist ein verteiltes Versionsverwaltungssystem.
Mit ihm kann man Zwischenstände von der Arbeit an Dokumenten speichern und jederzeit wieder zu ihnen zurückgehen.
Außerdem können mit Mercurial viele Leute zusammen an einem einzelnen Projekt arbeiten und ihre Arbeit automatisch zusammenführen lassen, ohne dass dafür jeder ständig mit den anderen verbunden sein muss.
Eine Analogie zum Unterschied von zentralisiertem VCS (SVN) und DVCS (Mercurial)
Bei SVN sagst du einem Beamten, was du gerne hättest und er gibt dir genau das. Bei Mercurial holst du dir einfach die ganzen Akten nach Hause und lässt dir von deinem Rechner immer raussuchen, was du grade brauchst. Dank effizienteren Algorithmen meist ohne nennenswert größener Platzverbrauch, allerdings viel schneller da du nicht mit anderen Rechnern reden musst.
Warum und wie ich es nutze
Ich verwende es inzwischen für so gut wie all meine Dokumente, und ich habe das Gefühl, dass sich dadurch mein Arbeitsfluss deutlich verbessert hat (vor allem bei meinen statischen Webseiten, aber dazu in einem anderen Artikel mehr).
Und alles was ich brauche ist ein simples
$hg init
$hg add
um mein Repository zu starten, und dann ein
$hg commit -m "Zusammenfassung meiner Änderungen in einer Zeile"
um die Änderungen zu sichern und auch jedesmal auf den Stand zurückgehen zu können.
Und diese extrem kurze Zusammenfassung zu schreiben vergegenwärtlicht mir auch nochmal, was ich eigentlich geleistet habe.
Wenn ich die Sachen Anderen geben will, gehe ich einfach auf http://bitbucket.org [257], erstelle da ein Projekt und mache ein
$hg push https://NUTZER:PWD@bitbucket.org/NUTZER/PROJEKT/ [258]
und schon können andere es sich holen mit
$hg clone https://bitbucket.org/NUTZER/PROJEKT/ [259]
Und sie können dann eigene Änderungen einpflegen und es wieder "push"en, wenn sie mir ihre Änderungen geben wollen. Sie können sogar die Änderungen automatisch packen und mir per Mail schicken, wenn ich ihnen keinen direkten Zugriff auf das Repository geben will:
$hg bundle PROJEKT.bundle
Es speichert automatisch die Änderungen zu meinem Repository (es sei denn, der Nutzer gibt etwas anderes an) und ich kann mir dann überlegen, ob ich die Änderungen einpflege, und auch welche ich davon übernehmen will.
Wenn ich sie einpflege, sieht mein's danach so aus, als hätte der andere Nutzer direkt bei mir gearbeitet (enthält aber weiterhin auch meine Änderungen).
Anders gesagt: Mercurial zu verwenden ist verdammt praktisch.
Note: This tutorial is for the old TortoiseHG (with gtk interface). The new one works a bit differently (and uses Qt). See the official quick start guide [260]. The right-click menus should still work similar to the ones described here, though.
Wenn du TortoiseHG [261] installiert hast, kannst du dir das Repository auf den Rechner laden, indem du in einem Ordner rechtsklickst und im Menü "TortoiseHG" die Option "Clone" wählst (Aktuell brauchst du für den Dialog noch Windows, die anderen gibt es auch in GNU/Linux).
Rechtsklick-Menü, Windows:

Clone, GNU/Linux:
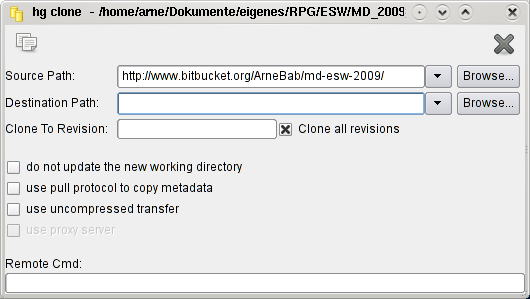
In dem Dialog gibst du einfach die URL des Repositories ein, also z.B.
http://www.bitbucket.org/ArneBab/md-esw-2009 [262]
ein (das ist auch direkt die Adresse des Repositories im Netz).
Wenn du dich auf bitbucket.org [257] anmeldest, findest du eine clone-Adresse direkt auf der Seite, über die du auch Änderungen hochladen kannst (sie enthält deinen Login - ich kann dir auf der Seite "push" Zugang geben).
Du hast damit zwei grundlegende Möglichkeiten: Änderungen lokal speichern, zwischen den Änderungen vor und zurück wechseln, und Änderungen mit anderen synchronisieren (ich vermute ich erzähle dir gerade zum Gutteil reduntantes Zeug, aber ich schreibe dann doch lieber zu viel als zu wenig - wenn ich schon viel zu selten zum Schreiben komme :) ).
Um Änderungen zu speichern, kannst du einfach im Rechtsklick Menü (in dem Ordner) "HG Commit" wählen. Wenn Dateien HG noch nicht bekannt sind, musst du sie mit "Add Files" einfügen (Die Checkbox neben der Datei anklicken), damit du sie committen kannst.
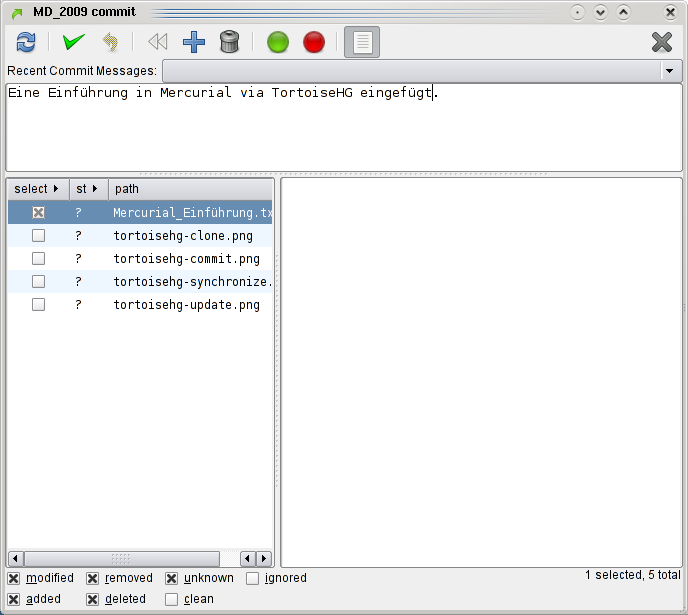
Um zu früheren Änderungen zurück zu gehen, kannst du im "TortoiseHG" Menü "Checkout Revision" nutzen. In dem Dialog kannst du dann die Revision auswählen, zu der du willst, und das Icon links oben nutzen, um die Dateien im Ordner auf die Version zu bringen.
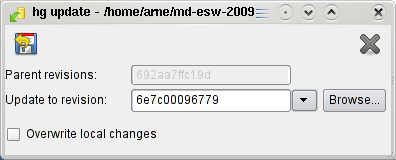
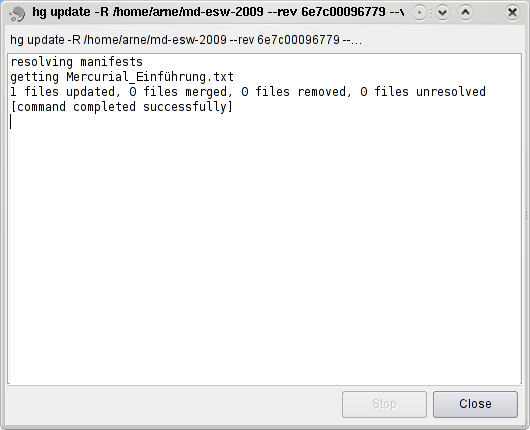
Synchronisieren kannst du, indem du rechtsklickst und im Menü "TortoiseHG" den Punkt "Synchronize" wählst. In dem aufspringenden Dialog kannst du "pushen" (Updates ins Netz laden - Pfeil hoch mit Strich drüber), "pullen" (Daten auf deinen Rechner ziehen - Pfeil runter mit Strich drunter), und z.B. schauen, was du pullen würdest. Ich denke, dass den Dialog zu nutzen schnell natürlich wird.
Viel Spaß mit TortoiseHG [261]! :) - Arne
PS: Es gibt dazu im Netz auch eine englische Einführung in TortoiseHG [263] und einen englischen Überblick zu DVCS [264].
PPS: md-esw-2009 ist ein Repository in dem Baddok und ich eine gemeinsame Runde Mechanical Dream [265] geplant haben.
PPPS: Auf meinen englischen Seiten [266] habe ich nun auch eine englische Version dieses Artikels [267].
| Anhang | Größe |
|---|---|
| tortoisehg-clone.png [268] | 29.84 KB |
| tortoisehg-commit.png [269] | 41.75 KB |
| tortoisehg-synchronize.png [270] | 47.43 KB |
| tortoisehg-synchronize-pull.png [271] | 39.09 KB |
| tortoisehg-update.png [272] | 18.84 KB |
| tortoisehg-update-result.png [273] | 23.33 KB |
| Es gibt inzwischen einige schöne Vergleiche von verschiedenen verteilten Versionsverwaltungssystemen im Netz, und da ich sie sowieso lese, habe ich hier jetzt eine Linkliste erstellt. | There is now a nice collection of comparisions between distributed version tracking systems, and since I read them anyway, I decided to create a list of links. |
Links zu Leuten, die schreiben, warum sie sich für Mercurial entscheiden haben.
I just did a test with the provided Python 2.x repos from the DVCS PEP [287] for Python to check the performance of Bazaar and Mercurial.
(this is a slightly changed version of a mail posted to the mercurial list: http://selenic.com/pipermail/mercurial/2008-November/022199.html [288] )
All these tests are done only once with some mostly constant load, so they don't qualitfy as scientific tests, but they give a good impressing of the differences between Bazaar (bzr) and Mercurial (hg).
Versions:
- Bazaar 1.5
- Mercurial 1.0.2
These are the ones which are marked as stable in my Gentoo tree (amd64).
First test: initial cloning from the web.
With repositories containing the same changesets (roughly, since bzr tracks dir name changes) Mercurial is about 9 times faster than Bazaar.
$ time bzr branch http://code.python.org/python/trunk [289]
No handlers could be found for logger "bzr"
[13868] 2008-11-05 11:36:44.358 INFO: Branched 40626 revision(s).
Branched 40626 revision(s).
real 24m0.446s
user 12m47.623s
sys 0m15.842s
$ time hg clone http://code.python.org/hg/trunk/ [290] python-hg-trunk
requesting all changes
adding changesets
adding manifests
adding file changes
added 40556 changesets with 86253 changes to 8166 files
updating working directory
3922 files updated, 0 files merged, 0 files removed, 0 files unresolved
real 2m40.237s
user 1m34.721s
sys 0m13.027s
>>> (24.0 + 0.44 / 60 ) / ( 2 + 40.237 / 60 )
8.989434400294563
And hg only uses about half as much space as bzr for the repository data (with bzr 1.5 that is - that was the stable version in my Gentoo tree as of 2008-10-31):
$ du -hs python-bzr-trunk/.bzr python-hg-trunk/.hg
214M python-bzr-trunk/.bzr
111M python-hg-trunk/.hg
Second test: a full log.
A full bzr log takes about 2.5 times as long as a full hg log in the cloned python 2.x repositories (so hg log is about 2.5 times faster than bzr log):
$ time bzr log
...
real 1m10.258s
user 0m37.236s
sys 0m2.250s
$ time hg log
...
real 0m27.886s
user 0m12.737s
sys 0m0.482s
>>> (1 + 10.258/60) / (27.886 / 60)
2.519472136555978
As I understand it, the new revlog in C should give Mercurial another nice speedup here (am I right in that?).
Third test: local clones.
A local clone in Mercurial is about 11 times faster than a local clone in bzr.
$ time bzr branch python-bzr-trunk/ python-bzr-trunk2
...
real 11m36.265s
user 8m38.400s
sys 0m11.145s
$ time hg clone python-hg-trunk python-hg-trunk2
...
real 0m59.759s
user 0m23.321s
sys 0m5.455s
A second run (backwards, with hot filesystem caches) gave even stronger results:
$ rm -r clone python-hg-trunk
$ time hg clone python-hg-trunk2 python-hg-trunk
real 0m38.779s
user 0m23.394s
sys 0m4.635s
With bzr I first cloned backwards to heat up the filesystem caches and then cloned again:
$ rm -r python-bzr-trunk
$ bzr branch python-bzr-trunk2 python-bzr-trunk
$ rm -r python-bzr-trunk2
$ time bzr branch python-bzr-trunk python-bzr-trunk2
...
real 12m8.374s
user 8m44.747s
sys 0m10.782s
Result: bzr is unusable for quick local clones of not-so-small projects.
Sidenote:
$ #cold copy of .hg
$ time cp -r python-hg-trunk/.hg tmp-hg
real 0m53.981s
user 0m0.077s
sys 0m3.486s
# hot copy of .bzr
$ time cp -r python-bzr-trunk/.bzr tmp-bzr
real 0m25.738s
user 0m0.012s
sys 0m1.368s
# hot copy of .hg
$ rm -r tmp-hg
$ time cp -r python-hg-trunk/.hg tmp-hg
real 0m14.702s
user 0m0.085s
sys 0m6.241s
To alleviate some doubts about system load: this is what top gave while I did the first local clone of the bzr repo:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
23202 arne 21 1 359m 255m 3412 R 70.1 12.7 1:39.33 bzr
CPU load due to bzr moved between 60% and 80% while cloning.
The general load on the system while running bzr commands was about the same as while running hg commands (I compiled stuff with niceness 11 = low priority).
Result: So Mercurial is far faster than bzr, while being a lot more newbie friendly than git (especially when the newbies are former svn users - Python currently uses svn).
I repeatet my test [291] with the provided Python 2.x repos from the DVCS PEP [287] for Python to check the performance of Bazaar and Mercurial.
All these tests are done only once with some mostly constant load, so they don't qualify as scientific tests, but they give a good impression of the differences between Bazaar (bzr) and Mercurial (hg).
Versions:
- Bazaar 1.10
- Mercurial 1.1
This comparision should be fair since Bazaar 1.10 is more recent, but Mercurial 1.1 is a major release.
You can do all these tests yourself using the script from the hg-vs-bzr-unscientific repository:
hg clone http://www.bitbucket.org/ArneBab/hg-vs-bzr-speedtest-unscientific/ [292]
cd hg-vs-bzr-unscientific
./test.sh
First test: Initial cloning from the web.
With repositories containing the same changesets (roughly, since bzr tracks dir name changes and hg doesn't) Mercurial is more than 6 times as fast as Bazaar. But there might be a better way to serve bzr repositories, so this isn't perfectly decisive. But since local cloning in Mercurial is 6.7 times faster, the reason for the higher speed is likely to be in the client.
Second test: Repository size
A Mercurial repository needs about half the space of a Bazaar repository, even though they contain roughly the same data. Manual repacking in Bazaar doesn't change this size significantly (213M instead of 214M).
Third test: A full log.
Here Mercurial is about 2.2 times as fast as Bazaar: 13s instead of 30s.
Fourth test: Local clones
Local cloning in Mercurial is about 6.7 times faster than in Bazaar: about 38s instead of 4min 14s.
Fifth test: Local clones with shared repository and forced hardlinks (bzr)
As suggested in the Mercurial Mailinglist, I reran the local cloning test for Bazaar using a shared repository and forced hardlinks. With this Bazaar needed just 4.5s for a local clone, without hardlinks about 12s, so by using shared repositories the local cloning becomes quite fast in Bazaar (as long as you restrict yourself to the shared repository).
| Test | Mercurial | Bazaar | Result |
|---|---|---|---|
| Initial clone | 1m23.699s | 8m52.962s | Mercurial is about 6 times faster |
| Repository size | 111M | 214M | Mercurial needs roughly half the space |
| full log | 0m12.907s | 0m29.207s | Mercurial is about 2.2 times faster |
| local clone | 00m37.642s | 4m14.102s | Mercurial is about 6.7 times faster |
| local clone with hot buffers | 0m32.744s | 3m44.461 | Mercurial is about 6.8 times faster |
| local clone with hot buffers and shared repository and hardlinks (bzr) | 0m32.744s | 0m4.546s | Bazaar is about 7.2 times faster (but you must create your clones in the shared repository) |
This is a clean run of the script plus two reruns of the last test: hot copy of .bzr and .hg, since there was an error in the script.
$ ./test.sh
bzr --version
No handlers could be found for logger "bzr"
Bazaar (bzr) 1.10
Python interpreter: /usr/bin/python 2.5.2
Python standard library: /usr/lib64/python2.5
bzrlib: /usr/lib64/python2.5/site-packages/bzrlib
Bazaar configuration: /home/arne/.bazaar
Bazaar log file: /home/arne/.bzr.log
Copyright 2005, 2006, 2007, 2008 Canonical Ltd.
http://bazaar-vcs.org/ [293]
bzr comes with ABSOLUTELY NO WARRANTY. bzr is free software, and
you may use, modify and redistribute it under the terms of the GNU
General Public License version 2 or later.
hg --version
Mercurial Distributed SCM (version 1.1)
Copyright (C) 2005-2008 Olivia Mackall
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
initial clone bzr
time bzr branch http://code.python.org/python/trunk [289] python-bzr-trunk
No handlers could be found for logger "bzr"
[18778] 2008-12-13 12:39:35.629 INFO: Branched 40761 revision(s).
Branched 40761 revision(s).
real 8m52.962s
user 5m52.733s
sys 0m10.519s
initial clone hg
time hg clone http://code.python.org/hg/trunk/ [290] python-hg-trunk
requesting all changes
adding changesets
adding manifests
adding file changes
added 40690 changesets with 86495 changes to 8167 files
updating working directory
3921 files updated, 0 files merged, 0 files removed, 0 files unresolved
real 1m23.699s
user 1m0.614s
sys 0m9.797s
comparing repository sizes
du -hs python-bzr-trunk/.bzr python-hg-trunk/.hg
214M python-bzr-trunk/.bzr
111M python-hg-trunk/.hg
time for a full bzr log
time bzr log >/dev/null
No handlers could be found for logger "bzr"
real 0m29.207s
user 0m28.022s
sys 0m0.378s
time for a full hg log
time hg log >/dev/null
real 0m12.907s
user 0m12.385s
sys 0m0.244s
bzr local clone
time bzr branch python-bzr-trunk/ python-bzr-trunk2
No handlers could be found for logger "bzr"
| [=============================================== ] Copying content texts 3/5^[18796] 2008-12-13 12:45:55.641 INFO: Branched 40761 revision(s).
Branched 40761 revision(s).
real 4m14.102s
user 3m23.507s
sys 0m6.860s
hg local clone
time hg clone python-hg-trunk python-hg-trunk2
updating working directory
3921 files updated, 0 files merged, 0 files removed, 0 files unresolved
real 0m37.642s
user 0m21.634s
sys 0m5.216s
clone with hot filesystem buffers, hg
rm -r python-hg-trunk
time hg clone python-hg-trunk2 python-hg-trunk
updating working directory
3921 files updated, 0 files merged, 0 files removed, 0 files unresolved
real 0m32.744s
user 0m21.820s
sys 0m4.431s
clone with hot filesystem buffers, bzr
rm -r python-bzr-trunk
bzr branch python-bzr-trunk2 python-bzr-trunk
No handlers could be found for logger "bzr"
[18802] 2008-12-13 12:51:30.879 INFO: Branched 40761 revision(s).
Branched 40761 revision(s).
rm -r python-bzr-trunk2
time bzr branch python-bzr-trunk python-bzr-trunk2
No handlers could be found for logger "bzr"
[18816] 2008-12-13 12:55:16.111 INFO: Branched 40761 revision(s).
Branched 40761 revision(s).
real 3m44.461s
user 3m22.856s
sys 0m5.401s
hot copy of .bzr
cp -r python-bzr-trunk/.bzr /tmp/tmp-bzr
rm -r tmp-bzr
rm: Entfernen von „tmp-bzr“ nicht möglich: Datei oder Verzeichnis nicht gefunden
time cp -r python-bzr-trunk/.bzr /tmp/tmp-bzr
real 0m2.979s
user 0m0.012s
sys 0m1.271s
hot copy of .hg
cp -r python-hg-trunk/.hg /tmp/tmp-hg
rm -r tmp-hg
rm: Entfernen von „tmp-hg“ nicht möglich: Datei oder Verzeichnis nicht gefunden
time cp -r python-hg-trunk/.hg /tmp/tmp-hg
real 0m8.213s
user 0m0.079s
sys 0m2.476s
rm -r python-bzr-trunk python-bzr-trunk2 python-hg-trunk python-hg-trunk2 /tmp/tmp-hg /tmp/tmp-bzr
# testing the hot copy of .bzr and .hg again, but this time really deleting /tmp/tmp-*
$ rm -r /tmp/tmp-* ; time cp -r python-hg-trunk/.hg /tmp/tmp-hg ; time cp -r python-bzr-trunk/.bzr /tmp/tmp-bzr ;
real 0m3.183s
user 0m0.079s
sys 0m2.250s
real 0m2.139s
user 0m0.014s
sys 0m1.593s
$ rm -r /tmp/tmp-* ; time cp -r python-hg-trunk/.hg /tmp/tmp-hg ; time cp -r python-bzr-trunk/.bzr /tmp/tmp-bzr ;
real 0m3.921s
user 0m0.059s
sys 0m2.691s
real 0m3.350s
user 0m0.013s
sys 0m1.632s
An additional test with a bzr optimized workflow gives the following results:
bzr optimized local cloning test using a shared repo.
time bzr init-repo bzr
No handlers could be found for logger "bzr"
Shared repository with trees (format: rich-root-pack)
Location:
shared repository: bzr
real 0m0.442s
user 0m0.328s
sys 0m0.069s
cd bzr
time bzr branch http://code.python.org/python/trunk [289] python-bzr-trunk
No handlers could be found for logger "bzr"
[26234] 2008-12-15 11:55:14.502 INFO: Branched 40773 revision(s).
Branched 40773 revision(s).
real 10m39.557s
user 5m28.317s
sys 0m9.968s
check the size after repacking
bzr pack
No handlers could be found for logger "bzr"
rm .bzr/repositry/obsolete_packs/*
rm: Entfernen von „.bzr/repositry/obsolete_packs/*“ nicht möglich: Datei oder Verzeichnis nicht gefunden
du -hs .bzr
213M .bzr
time bzr branch python-bzr-trunk python-bzr-trunk2 --hardlink
No handlers could be found for logger "bzr"
[26879] 2008-12-15 13:07:07.532 INFO: Branched 40773 revision(s).
Branched 40773 revision(s).
real 0m4.546s
user 0m3.682s
sys 0m0.737s
cd ..
rm -r python-* /tmp/tmp-hg /tmp/tmp-bzr bzr/
To alleviate some doubts about system load, I stopped all other operations besides this test, konqueror and kmail. During the inital bzr clone top gave me the following (on my system everythign I start from an X session has niceness 1 so X doesn't bog down core processes):
top - 12:31:07 up 1 day, 2:36, 5 users, load average: 0.70, 0.99, 0.95
Tasks: 146 total, 3 running, 143 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 2.0%sy, 97.7%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Mem: 2060384k total, 1146140k used, 914244k free, 103944k buffers
Swap: 5111796k total, 4048k used, 5107748k free, 112700k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18778 arne 21 1 209m 89m 3960 R 94.7 4.4 0:14.24 bzr
15922 arne 21 1 416m 134m 42m S 3.3 6.7 4:40.40 konqueror
7591 root 21 1 651m 310m 6568 S 1.0 15.4 21:54.84 X
Bazaar once managed to get a local clone in a shared repository with forced hardlinks done in just 2.598 seconds, but every subsequent run gave results in the range of 4.3s to 4.8s, so that speed wasn't repeatable and I used a medium value for evaluation (about 4.5s).
This definitely shows the danger of unscientific tests: You don't know how unsure the results are - the difference in this case was about 50%, with the variance yet to be determined.
So Mercurial is far faster than bzr when it comes to cloning (except when using bzr with a shared repository), especially for the initial clone, and a good deal faster in generating the log, while being a lot more newbie friendly than git (especially when the newbies are former svn users - Python currently uses svn).
Update: Python decided to switch to Mercurial [294].
Some folks in #mercurial @ freenode.net just repeated the tests, so we have now a bit more stable data [295].
The evaluation shows the following:
So Mercurial is faster than Bazaar for the initial cloning and for free cloning (Bazaar takes almost 10 mintes for the initial clone while Mercurial finishes after just 2 minutes), while Bazaar is faster when cloning in a shared repository.
Also Mercurial is more than 2 times as fast as Bazaar in generating the log, while Bazaar is faster at annotating.
Additionally Mercurial consumes about half as much diskspace as Bazaar.
The biggest difference is in integrity checking, though, where all testers stopped Bazaar after up to 17min, since it didn't even check a fraction of the repository in that time. Mercurial on the other hand finished after just one minute.
English: A speed test for Mercurial and git (in german). -> Links to other tests [296]. Update: I wrote a new test for use in server applications, since they are the only place where a difference of 30-60ms really matters: hg vs. git for server applications [274].
Ich habe ein paar Testsskripte geschrieben, um die lokale Leistung von Mercurial und GIT vergleichen zu können.
Update: Ich habe einen neuen Test für die Nutzung in Serverprogrammen geschrieben, weil dort der Unterschied um 30-60ms wirklich etwas ausmacht: hg vs. git for server applications [274].
Was ich wissen wollte ist, wie schnell die Systeme jeweils bei lokalen commits sind (andere Operationen prüfe ich noch nicht), und wie sich ihre Leistung ändert, wenn ich die Anzahl der Dateien oder die Art der Änderungen variiere.
Meine Anregung dafür war der Mercurial-vs-Bazaar [297] Test
Ich nutze selbst fast ausschließlich Mercurial, daher kann es sein, dass ich ein paar Optimierungsmöglichkeiten von git übersehen habe. Ich habe bei Mercurial allerdings auch keine genutzt.
Meine Skripte dazu sind alle in einem Mercurial repository im Netz verfügbar: - http://freehg.org/u/ArneBab/python_tests/
Die Testergebnisse genügen nicht wissenschaftlichen Standards, weil
Bei den Tests war git in den meisten Fällen schneller als Mercurial, vor allem mit wenigen Dateien.
Bei vielen Dateien kam die Geschwindigkeit von Mercurial näher an git heran.
Die Tests, die ich gemacht habe sind:
Bisher hat sich git in Tests mit 2 Dateien als um den Faktor 4 bis 5 schneller erwiesen.
Mit 200 Dateien war es noch um den Faktor 2.5 bis 4 schneller.
Gleichzeitig haben die Daten im Mercurial Ordner nur etwa halb so viel Platz eingenommen, wie in git (ohne repack).
Mit 2000 Dateien war git nur noch um den Faktor 2 bis 2,6 schneller. Das git repo hat dabei knapp 100 MiB belegt hat und das Mercurial repo nur knapp 80 MiB.
Struktur der Ergebnisse: = Für 2 Dateien =
init: - git: 0.01423661708831787 s - Mercurial: 0.13704051971435546 s
initial_commit: - git: 0.086095404624938962s - Mercurial: 0.32350056171417235 s
commit_after_append_small: - git: 0.084930634498596197 - Mercurial: 0.31660361289978028
commit_after_append_of_many_lines: - git: 0.086296844482421878 - Mercurial: 0.31294920444488528
commit_after_append_of_one_long_line: - git: 0.08749730587005615 - Mercurial: 0.32180678844451904
= Für 2000 Dateien =
[git, hg], time in seconds, mean value.
init [0.063668489456176758, 0.14365851879119873] - Factor: 2.25635192571
initial_commit [1.5152170658111572, 3.1502538919448853] - Factor: 2.07907762064
commit_after_append_small [1.4661256074905396, 3.7556029558181763] - Factor: 2.56158335727
commit_after_append_of_many_lines [16.113877415657043, 42.500172019004822] - Factor: 2.63748885031
commit_after_append_of_one_long_line [15.808947086334229, 38.482058048248291] - Factor: 2.43419487953
Anmerkungen:
Ich habe gerade einen sehr schönen Vergleich der Versionsverwaltungssysteme Mercurial und Bazaar gefunden.
Für alle, die sich nicht durch einen langen Artikel wühlen wolllen:
Mercurial ist in den meisten Tests 2-5x schneller als Bazaar.
Der volle Artikel:
http://sayspy.blogspot.com/2006/11/bazaar-vs-mercurial-unscientific.html [277]
Falls ihr gerne eine Übersetzung der kritischen Teile hättet, schreibt es bitte.
Nebenbei: Ich nutze Mercurial, um meine Programme und meine Texte (Rollenspielzeug, Lieder, Gedichte und Geschichten) zu verwalten, und es ist ein tolles Gefühl jederzeit zurückgehen oder einfach schauen zu können, was ich wann gemacht habe.
Es gibt mir ein Gefühl der Sicherheit.
Egal, was ich ändere, solange meine Platten bleiben, kann ich es jederzeit rückgängig machen.
Und eine Sicherheitskopie anlegen ist so einfach wie
hg clone . {Zielordner}
Sie zu aktualisieren und nur rüberzukopieren ist ein einfaches
hg push {Zielordner in dem eine Sicherheitskopie ist}
--- Nachtrag ---
Ich habe jetzt auch eigene Tests durchgeführt und viele andere gesammelt:
Leistungstests und Vergleiche, DVCS: Mercurial (HG), Git, Bazaar(bzr), ... [296]
-> Webseiten auf den FTP-Server laden wird einfach "hg push".
Ich schreibe seit langem eigene Webseiten, und die Notwendigkeit, sie jedesmal von Hand auf den Server hochzuladen, wenn ich etwas geändert hatte, war mir seit Jahren ein Dorn im Auge.
Vor kurzem habe ich nun angefangen, die Webseiten mit Mercurial als Versionsverwaltung zu bearbeiten, und Mercurial hat eine sehr praktische Funktion: Hooks (also Anker).
Damit kann ich einen Befehl ausführen, wenn ich in meiner Versionsverwaltung eine bestimmte Handlung ausführe.
Ich verwende sie, um meine Webseiten direkt auf den FTP-Server zu kopieren, sobald ich Änderungen in Mercurial "push"e.
Das heißt, sobald ich eine Webseite so weit aktualisiert habe, dass ich sie veröffentlichen will, gehe ich nur kurz in die Konsole und tippe
hg push
und schon landet meine Webseite automatisch aktualisiert auf meinem FTP-Server.
Und wenn ich nichts geändert habe, merkt Mercurial das und ruft den FTP nichtmal auf.
Damit es auch bei euch funktioniert, braucht ihr nur Mercurial und lftp. Ich bin mir sicher, es geht auch ohne lftp, aber damit geht es bei mir gut, und es war schnell installiert. Warum sollte ich mir die Arbeit machen, wenn es andere schon für mich gemacht haben?
-> Mercurial: http://www.selenic.com/mercurial/ [298]
-> lftp: http://linux.maruhn.com/sec/lftp.html [299]
Danach müsst ihr nur noch das folgende in hgrc im Repository der Webseite eintragen (in ".hg/hgrc" - Zeilen, die mit "#" anfangen, sind Kommentare):
default-push müsst ihr noch für euch anpassen. Bei mir nimmt es mein Mercurial repo auf freehg.org
------ ------ Datei ------ ------
[paths]
# default-push = http://USER:PASSWORD@freehg.org/u/ArneBab/erynnia/ [300]
[hooks]
# Update my website automatically when I push the repo.
# Explanations: lftp -c 'COMMAND'
# COMMAND:
# open CMD -u USER,PASSWORD FTP_SERVER
# CMD:
# -R: Reverse -> local_source remote_source
# -X GLOB: Glob: Shell-style -< exclude the .hg dir
outgoing = lftp -c 'open -e "mirror -R -X .hg/ ABSOLUTER_PFAD_LOKAL RELATIVER_PFAD_FTP" -u USER,PASS ftp://FTP_SERVER [301] '
------ ------ /Datei ------ ------
Und schon ist es nur noch "hg push", um die Webseiten zu aktualisieren.
Und es wird nur hochgeladen, was sich geändert hat (dank lftp).
Effektiv ist das ein "push content to FTP" mit Mercurial.
Viel Spaß!
PS: Wenn du Webseiten mit noch weniger Aufwand basteln willst, kannst du deine Webseiten auch mit pyMarkdown_Minisite [302] schreiben, einem Projekt, das ich gestartet habe, weil ich nicht alles in HTML kodieren und trotzdem einfache und schön aussehende Webseiten haben wollte. Die Technik in diesem Artikel nutze ich dabei zum automatischen hochladen der Seiten.
Eine wirklich wirklich peinliche Situation…lies’ selbst:
„Verdammt, warum ist das so langsam? habe ich irgendwo im Code was zerschossen?“
(suchen, suchen,
am Kopf kratzen,
weitersuchen)
„Selbst das Bauen dauert ewig. Läuft da gerade ein anderer teurer Prozess?“
(`top`)
„Hm, eigentlich alles in Ordnung. Moment: Java?!? Warum läuft auf dem Unirechner ein Freenet [148]???1 Das gehört hier nicht her. Ich brauche jedes bisschen Ram für die Simulation!“
(`pkill java`)
„Hm, ist immernoch nicht schneller…“
„…“
„Arg!“
(`hostname`)
„Verdammt!“
(`ssh …`; nochmal…)
Wer das nicht kennt, war noch nicht via SSH auf einem viel schnelleren Rechner und hat irgendwann vergessen, auf seinen Rechnernamen zu achten :)
PS: Die Daten synchronisiere ich via Mercurial [303], so dass auch die Daten gleich sind :)
Als ich das Freenet gesehen habe, hätte mir schon klar sein müssen, dass ich nicht auf einem Uni-Rechner sein kann: Das lasse ich nur zu Hause laufen. ↩
Ich fange gerade an, Python zu lernen.
Hier finden sich meine Erfahrungen mit Python, und die Programme, die ich damit schreibe.
Ich versuche meine Texte allgemeinverständlich zu schreiben und meinen Code sauber zu kommentieren und hoffe, dass sie für dich damit nützlich sind.
Und wenn du schon python3 installiert hast, probier doch mal das hier:
python3 -c "import antigravity;print(antigravity.__doc__)"
...dazu hätte ich gerne docs ;)
Ich habe einen kleines Programm geschrieben, das einen interagierenden Schwarm von Blobs zeigt.
Jeder der Blobs sucht sich am Anfang einen Partner und nähert sich ihm.
Wenn die beiden Partner sich zu nahe kommen, flieht einer von ihnen und sucht sich einen neuen Partner, dem er sich wieder annähert, bis er ihm zu nahe kommt.
Durch diese brechenden Zweierbeziehungen bleiben die Blobs zusammen, das heißt es entsteht ein Schwarmverhalten, obwohl jeder Blob nur an seinen aktuellen oder nächsten Partner denkt.
Das ganze ist in Python und pyglet (GUI) implementiert. Die einzige Abhängigkeit ist Python 2.5 [304].
Wenn du es anschauen willst, lade dir einfach den Blob Schwarm [305] herunter, entpacke sie und klick in dem Ordner die Datei blob_swarm.pyw an.
Alles andere sollte von selbst gehen.
Viel Spaß!
| Anhang | Größe |
|---|---|
| blob_swarm-0.2.tar.gz [306] | 556.85 KB |
| blob_swarm-0.3.tar.gz [305] | 855.62 KB |
Ein kleines Geschenk, das ich meiner Frau zum (bzw. am) Valentinstag 2008 geschrieben habe.
In seiner Gänze kann es allerdings in diesem Screenshot nicht genossen werden. Um das ganze animiert zu haben, musst du schon das Programm runterladen :) (es braucht nur Python [307] (>=2.5) ).

-> Blob Valentine 0.3 herunterladen [308]
| Anhang | Größe |
|---|---|
| blob_valentine-0.3.tar.gz [308] | 255 KB |
| blob_valentine_screenshot-2008-02-15.png [309] | 209.4 KB |
Hier führe ich Links und Texte, die meiner Meinung nach (mMn) essenziell für Python-Programmierer sind.
Die Liste wird sich wohl langsam erweitern.
Allgemein ist der Link zu den python Tools im SVN wichtig. Er enthält so interessante Dinge wie pygettext.py (das ich vorher stundenlang gesucht habe)...
Angefangen mit Übersetzung (l10n) und Internationalisierung (i18n), vll. irgendwann auch Multinationalisierung (m17n).
Hier teste ich kurz, wie lange ein selbstgeschriebenes Programm zum summieren einer Liste von Zahlen braucht und vergleiche sie mit der mitgelieferten Funktion sum().
Vorsicht: Die Daten hier sind von 2008. → Nachtrag 2016
Die Funktionen, die ich nutze sind:
def summieren(liste): """Summiere alle Zahlen der Liste manuell.""" # erst brauchen wir einen Zähler, # auf den wir alle Zahlen aufsummieren. gesamt = 0 # Dann summieren wir # alle Zahlen der Liste zu dem Zähler. for x in liste: # Das heißt, wir erhöhen ihn # für jede Zahl in der Liste um die Zahl. gesamt += x # und geben ihn dann zurück. return gesamt
und
def summieren(liste): """Summiere alle Zahlen der Liste mit sum().""" return sum(liste)
Die benötigte Zeit teste ich, indem ich die Funtion in einem doctest jeweils 100001 mal ablaufen lasse und prüfe, wie lange python braucht, um das Skript zu auszuführen.
Die vollständigen Quelltexte habe ich an die Seite angehängt.
Die Aufrufe sind damit:
time python summieren_selbst.py # Selbstgeschriebener Code
time python summieren_sum.py # Eingebaute Funktion
Und ich erhalte die Ergebnisse:
$ time python summieren_selbst.py
real 0m7.536s
user 0m7.430s
sys 0m0.030s
$ time python summieren_sum.py
real 0m4.362s
user 0m4.260s
sys 0m0.070s
Damit braucht meine selbstgeschriebene Summierfunktion etwa 74% länger als die eingebaute.
Fazit: Ich konnte mir bestätigen, dass es besser ist, die eingebaute Funktion zu nutzen, statt sie selbst zu schreiben. Der eingebaute Code ist effizienter.
Nachtrag 2016: Wenn die Geschwindigkeit der Summe wirklich kritisch für dein Programm ist, dann lagere sie aus. In Fortran und C++ braucht ein Programm für die gleiche Aufgabe nur 10-20% der Laufzeit (Vorsicht: Zwischen diesem Text und dem Nachtrag lagen 8 Jahre Entwicklung. Der Python-Code braucht jetzt nur noch 0.2s, der angehängte Fortran-Code [316] braucht 0.02s und der C++-code 0.07s. PyPy führt den neuen angehängten Python-code [317] in 0.07s aus). Im angehängten C++-code [318] habe ich statt 100000-mal über die gleiche Liste zu summieren über eine 100000-mal so lange Liste mit Zufallszahlen summiert, damit der Compiler nicht 99999 der Rechnungen als offensichtlich unnötig wegoptimiert ☺.
| Anhang | Größe |
|---|---|
| summieren_sum.py.txt [319] | 476 Bytes |
| summieren_selbst.py.txt [320] | 749 Bytes |
| summe.cpp_.txt [318] | 767 Bytes |
| summe.f90__.txt [321] | 221 Bytes |
| summen.py_.txt [317] | 301 Bytes |
| summen.f90 [316] | 307 Bytes |
Ich habe getestet, ob es einen Geschwindigkeitsunterschied zwischen zwei Arten des for loops über eine Liste von tuples gibt:
liste_von_tuples = [(1, 2), (3, 4), (5, 6)]
Es gibt 100.000 tuple, und jeder tuple enthält 2 Zufallszahlen.
Art 1:
for i in liste_von_tuples: res.append(i[1])
Art 2:
for i, j in liste_von_tuples: res.append(j)
Ich hatte erwartet, dass die zweite Art schneller ist, da bei Art 1 eine Zuweisungsoperation von zwei Werten und danach eine Auswahloperation und eine Zuweisungsoperation nötig sind, während bei Art 2 die Auswahloperation wegfällt.
Der Test bestätigte meine Ansicht.
Art 1 braucht bei der Liste mit 100.000 Tuples von je 2 Zufallszahlen zwischen 4% und 12% länger.
Fazit: Bei for loops über tuple, sollte Art 2 verwendet werden:
for i, j in liste_von_tuples: res.append(j)
Die verwendete und ausführlich kommentierte Testdatei ist angehängt.
Anmerkung: Meine Python Tests können jetzt auch mit Mercurial heruntergeladen werden: http://bitbucket.org/ArneBab/python_tests/ [322]
Ideen und Patches wären cool :)
| Anhang | Größe |
|---|---|
| for-loops-geschwindigkeitstest.py [323] | 5.57 KB |
Ich habe mein erstes Programm mit PyQt [324] erstellt.
In guter Programmier-Tradition heißt es "Hallo Welt!", und zeigt einfach "Hallo Welt!" an.
Ich habe es allerdings recht ausführlich kommentiert, so dass ich denke, dass es PyQt-Neulingen ein paar interessante Einzelheiten zeigen und Programmier- und Python-Neulingen ein paar einfache erste Einsichten geben kann.
Ich habe es angehängt, stelle den Code aber auch diekt auf diese Seite, denn Python Code ist schön genug, dass ich ihn offen auf die Webseite stellen kann.
-----
#!/bin/env python
# encoding: utf-8
#######################################################
# #
# Hallo Welt! #
# - Mein Erstes PyQt-Programm mit Kommentaren #
# #
# Copyright (C) 2007, Arne Babenhauserheide, GPL #
# #
# This program is free software; you can #
# redistribute it and/or modify it under the terms of #
# the GNU General Public License as published by the #
# Free Software Foundation; either version 2 of the #
# License, or (at your option) any later version. #
# #
# This program is distributed in the hope that it #
# will be useful, but WITHOUT ANY WARRANTY; without #
# even the implied warranty of MERCHANTABILITY or #
# FITNESS FOR A PARTICULAR PURPOSE. See the GNU #
# General Public License for more details. #
# #
# You should have received a copy of the GNU General #
# Public License along with this program; if not, #
# write to the Free Software Foundation, Inc., 51 #
# Franklin Street, Fifth Floor, Boston, MA 02110-1301 #
# USA. #
# #
#######################################################
# Erst holen wir das System-Framework. "sys"
# Qt Programme brauchen von ihm die
# Kommandozeilenparameter.
import sys
# Dann die benötigten Qt-Klassen.
# Erstens das grundlegende Widget für Programme
# QApplication
from qt import QApplication
# und Zweitens einen Knopf, den wir beschriften wollen
# QPushButton
from qt import QPushButton
# und dann noch Signal und Slot,
# damit ein Druck auf den Knopf
# das Programm beenden kann.
from qt import SIGNAL, SLOT
# Jetzt können wir uns das Programm app definieren
# und ihm die Kommandozeilenparameter übergeben:
app=QApplication(sys.argv)
# Der Knopf ist ähnlich schnell geschrieben.
# Er erhält den Text "Hallo Welt!\nIch kann
# (ein bisschen) PyQt!"
# Das \n erzeugt einen Zeilenumbruch.
# Einfallsreicherweise nennen wir ihn "button".
button=QPushButton("Hallo Welt!\nIch kann (ein bisschen) PyQt!", None)
# button=QPushButton(u"Hallo traumrose!\nIch liebe Dich!\nKüsst du mich?", None)
# Jetzt machen wir ihn zum Haupt-Widget
# des Programmes "app",
# so dass er auf der obersten Ebene liegt:
app.setMainWidget(button)
# Dann sagen wir ihm, dass er angezeigt werden soll.
button.show()
# Kurz vor dem Abschluss fügen wir noch
# als kleine Spielerei
# etwas Interaktivität hinzu:
# Das Programm soll sich beenden,
# wenn der Knopf gedrückt wird.
# Dafür verbinden wir das Signal "pressed()"
# des Knopfes "button"
# mit dem Slot "quit()" des Programmes app.
app.connect(button, SIGNAL("pressed()"),
app, SLOT("quit()"))
# Als letztes führen wir das GUI-Programm aus.
# Erst hier wird der Knopf wirklich sichtbar.
app.exec_loop()
# Um das zu testen kannst du das Programm einfach
# Schritt für Schritt in der Python-Shell ausführen.
# Das beendet mein erste Programm.
# Ich hoffe, Du hattest Spaß beim Lesen!
Für meine Plotroutinen brauche ich oft Funktionen, die eine Liste an Messwerten durchgehen und nur diejenigen zurückgeben, die einem bestimmten Kriterium entsprechen. Wenn dabei die Anzahl der Messwerte in die Millionen geht, kann alleine schon die Liste der ungefilterten Messwerte den Arbeitsspeicher des Rechners sprengen.
Ich könnte jetzt einfach eine Funktion schreiben, die alle Werte liest, filtert und nur die Relevanten zurückgibt.
Das könnte dann etwa so aussehen:
def naivefilter(filepath, name): """Get only the relevant values.""" values = [] with open(filepath) as f: for line in f: if line.startswith(name): values.append(line) return values
Wirkt im Kleinen noch übersichtlich. Aber sobald wir die Anzahl der Filterkriterien erhöhen - oder andere Eingabewerte brauchen - wird die Funktion unübersichtlich. Und unübersichtlicher Code ist unschön zu warten.
Um das Problem zu minimieren, nutze ich Iteratoren, die nur jeweils die benötigten Werte im Speicher zu behalten, aber von Funktion zu Funktion weitergegeben werden können. Damit kann ich die Logik zur Auswahl der Werte aus der auslesenden Funktion heraushalten und erhalte damit zwei schlanke Funktionen.
Das ganze sieht dann beispielsweise so aus:
def allvalues(filepath): """Get all values from the file.""" with open(filepath) as f: for line in f: yield line
def valuesforstation(filepath, name): """Get all the values from a file which come from the given station.""" return tuple(line for line in allvalues(filepath) if line.startswith(name))
Wirkt anfangs etwas länger, aber was passiert, wenn wir ein anderes Filterkriterium haben wollen?
Dann fügen wir einfach eine andere Filterfunktion hinzu:
def valueswithoutX(filepath, X): """Get all the values from a file which do not contain the value X.""" return tuple(line for line in allvalues(filepath) if not X in line)
Damit haben wir das Auslesen und das Filtern der Daten sauber getrennt, ohne jemals alle Werte gleichzeitig im Speicher halten zu müssen.
Der Code ist wartbar, übersichtlich und effizient. Und damit ist er genau so, wie ich ihn haben will.
Und falls ihr euch fragt, warum ich am Ende einen tuple zurückgebe und keinen weiteren Iterator: Ich habe noch einen Caching-Dekorator, und der mag keine Iteratoren (weil die theoretisch unendlich viele Werte zurückgeben können und damit nicht immer gecacht werden können). Aber dazu kommen wir ein ander’ Mal…1 (bis dahin kann ich euch den Leitfaden zu Dekoratoren von Simon Franklin [325] empfehlen, wenn ihr mit fortgeschritteneren Techniken experimentieren wollt :) ).
PS: Ja, ich könnte auch eine Datenbank nutzen. Dann muss ich die allerdings füllen und aktuell halten und wäre so weiter weg von den Daten, auf denen ich eigentlich arbeite. Und die Gesamt-Aufgaben sind schon komplex genug, ohne einen weiteren Indirektionsschritt einzuführen…
PPS: Alle Codeschnipsel in Python [220], farbige Quelltext-Hervorhebung via M-x htmlize-region in emacs [326] mit inline-css (einstellbar über M-x customize-variable htmlize-output-type)
Soll heißen, dazu kommen wir vielleicht ein ander’ Mal, je nach meinem Zeitbudget… ↩
Ich habe einen kleinen Test gemacht, um zu schauen, wie die Speicherverwaltung von Python funktioniert.
Dafür habe ich eine Klasse erzeugt, die eine extrem lange Liste als Attribut hatte, so dass viel Ram verbraucht wurde.
Dann habe ich mehrfach eine Instanz dieser Klasse der gleichen Variable zugewiesen.
Das Ergebnis war, dass höchstens der doppelte Speicherbedarf einer einzelnen Instanz verbraucht wurde.
Außerdem habe ich herausgefunden, dass ein dict mit 3 Millionen unterschiedlichen Schlüsseln, die auf das gleiche Objekt zeigen (None), etwa doppelt so viel Ram braucht wie eine Liste, die diese Schlüssel als Werte hat.
Das Skript zum Testen habe ich angehängt und poste es auch nochmal hier.
Viel Spaß beim selbst mit Python spielen :)
#!/usr/bin/env python
# encoding: utf-8
"""This file tests the memory purging of python by creating an instance of a
class over and over again.
It shows, that the instance is created at only one of two places over and over
again, so the maximum additional memory consumed when replacing an
instance is the size of the instance
The reason seems to be that the instance is first created and then assigned
to the variable. Only after that, the previous object gets deleted.
This seems easy to understand, because this behaviour is necessary to allow
for recursive functions where the new value of the variable depends on its
previous value.
"""
# We want random, so that no optimizing of same objects can be done.
from random import random
# Now we create a memory hungry class.
class MemoryHungry(object):
"""MemoryHungry is a class which just has many attributes which consume
memory.
For me one instance of MemoryHungry takes about 140Mib with
number_of_atts=3,000,000 - bab.
When I use a dict where I assign keys with random names to the value None
(all the same object), this takes about 250MiB per instance. - bab
"""
def __init__(self, number_of_atts=3000000, mode="list"):
if mode == "list":
self.liste = [] #: list of random numbers
elif mode == "dict":
self.liste = {} #: dict with random numbers as keys
# We add random numbers to teh list to make sure, that no memory
# usage can be optimized by grouping same objects or similar.
for i in range(number_of_atts):
self.blah = random() #: temporary random number
# append self.blah to the list attribute of the class, so it consumes
# memory (as object of the list reassigning self.blah doesn't delete the
# value/instance of float):
if mode == "list":
self.liste.append(self.blah)
if mode == "dict":
self.liste[self.blah] = None
# None is only one object, so what takes space here are the keys.
# Also we create a class thirsty, which creates a float with the same content
# over and over again.
class MemoryThirsty(object):
"""MemoryThirsty is a class which just has many attributes which consume
memory.
For me one instance of MemoryThirsty only takes about 70Mib with
number_of_atts=3,000,000, which is half the amount taken by the same
number of random numbers -bab.
"""
def __init__(self, number_of_atts=3000000):
self.liste = [] #: List of random numbers
# We add random numbers to the list to make sure, that no memory
# usage can be optimized by grouping same objects or similar.
for i in range(number_of_atts):
self.blah = 0.111111111111111111111111111111111 #: just a floating point number
# append self.blah to the list attribute of the class, so it consumes
# memory (as object of the list reassigning self.blah doesn't delete the
# value/instance of float):
self.liste.append(self.blah)
### Self-Test ###
if __name__ == "__main__":
# Create a MemoryHungry instance and give it to a variable over and over again.
print "hunger"
for i in range(10):
# assign an instance of MemoryHungry to the variable hunger
hunger = MemoryHungry(mode="dict")
# And print the instance.
print hunger, i
pass
print "hunger done"
del hunger
print "thirst"
for i in range(10):
# assign an instance of MemoryHungry to the variable hunger
thirsty = MemoryThirsty()
# And print the instance.
print thirsty, i
del thirsty
# We're done. Say so.
print "done"
| Anhang | Größe |
|---|---|
| python_memory_cleaning_test.py.txt [327] | 3.56 KB |
→ Antwort auf Is it in this case : http://identi.ca/url/75523035 (see : [01:16] [328]1 — Julien-Claude Fagot, die eine Antwort war auf One more reason why you should not use “from bla import foo”: print __import__(obs.__class__.__module__).__file__ [329] — ArneBab
Datei: bla.py
def foo():
print "bla"
Interaktiver Test:
\>>> import bla \>>> bla.foo() bla \>>> def fu(): ... print "fu" ... \>>> fu() fu \>>> from bla import foo \>>> foo() bla \>>> bla.foo = fu \>>> bla.foo() fu \>>> foo() bla
Profifrage: Was passiert, wenn du from bla import foo nach bla.foo = fu ausführst?
Antwort:
\>>> import bla \>>> bla.foo() bla \>>> def fu(): ... print "fu" ... \>>> fu() fu \>>> bla.foo = fu \>>> bla.foo() fu \>>> from bla import foo \>>> foo() fu
Happy hacking!
dsop: if you use 'bla.foo', then yes, you can assign to bla.foo and you'll see the change. If you do 'from bla import foo', then your locally imported 'foo' will not 'see' changes to bla.foo. ↩
→ Kommentar zu „Shellshock“-Lücke bei Apple und Linux — Die erste Angrifsswelle läuft [330] in der Taz [331].
Es hat keine 2 Tage gedauert, bis der Bug gefixt war. Und jetzt werden gerade auch alle möglichen anderen Teile von Bash auf Herz und Nieren geprüft. Nicht nur von Hobbyisten, sondern auch von Firmen, die Freie Software nutzen und verkaufen.
Statt ewig auf einen einzelnen Hersteller warten zu müssen, wurden binnen Stunden erste Lösungen veröffentlicht und nach wenigen Tagen war das Problem durch Ad-Hoc Kooperationen der verschiedensten Programmierer gelöst. Jetzt muss der Fix nur noch in die verschiedensten Distributionen verteilt werden und Shellshock ist Vergangenheit.
Dadurch wird die GNU Bash [332] in Zukunft sicherer sein als je zuvor - vermutlich eine der sichersten Shells.
Zur Gefahr durch diesen Fehler: Es dauerte keine zwei Tage ihn zu beheben. Selbst im schlimmsten vorstellbaren Fall mit sofortigen massiven Angriffen gegen alle verwundbaren Server, die zu einem Ausfall des Stromnetzes geführt hätten, wäre der Bug behoben gewesen, bevor der Inhalt einer geschlossenen Tiefkühltruhe angetaut wäre (würde es länger dauern, wäre es kritisch, weil die Nahrungsmittelversorgung in Gefahr geriete).
Natürlich wäre es schön, wenn solche Bugs gar nicht erst aufträten, aber das ist unrealistisch. Software, die groß genug ist um nützlich zu sein, hat immer auch Bugs. Und die Reaktion auf diesen Bug war vorbildlich.
Das hier ist eine kleine Auswahl an Quellen, um eigene Spiele zu programmieren. Sie ist nicht vollständig, sollte aber ausreichen, um direkt anfangen zu können. Sie enthält nur freie Programme.
Lies "Hello World" oder "Think Python" oder Snake Wrangling: http://www.manning.com/sande/ [340] , https://greenteapress.com/wp/think-python-2e/ [341] https://github.com/pairochjulrat/swfk [342]
(Snake Wrangling gibt es auch als PDF [343] und auf Deutsch: Schlangengerangel für Kinder [344] — Quellen [345] )
Damit hast du sehr schnell die Grundkenntnisse, die du für den 2. Schritt brauchst:
Nimm Blender: http://www.blender.org/education-help/tutorials/#c836 [346]
Alternativ kannst du jetzt auch die Python Bibliotheken nutzen.
| Anhang | Größe |
|---|---|
| swfk-linux-by-nc-sa.pdf [344] | 1.6 MB |
Hier sammle ich Spielereien und Lösungen für die verschiedensten Probleme, denen ich im Lauf meiner Nutzung von freier Software (besonders von KDE) begegnet bin.
Nachdem nun die ARD ihre Artikel löschen muss [349] und bereits 80% der Rezepte gelöscht wurden [350], speichere ich jetzt alle ihre Rezepte auf meinem eigenen Rechner.
Da ich das mit den anderen bisher nicht gemacht habe, nutze ich wget [351], um das für die noch existierenden nachzuholen. Ich vermute, dass du das auch machen willst, so dass dir die Rezepte, für die du GEZ gezahlt hast, nicht gestohlen werden können.
Deshalb ist hier mein wget-Aufruf:
Einfach in eine shell kopieren (du brauchst dafür wget).
wget -mkE --no-parent http://www.swr.de/buffet/guten-appetit/
Fast das gleiche funktioniert auch bei anderen Seiten, die sie offline nehmen müssen.
Wenn du die Seite nicht vollständig willst, sondern lieber die Druckversion als PDF, kannst du auch etwa 10 PDFs auf der Download-Seite des Rezept-Archivs [352] runterladen.
Aber beeil dich, du weißt nicht, wann sie „dank“ unserer Landespolitiker auch die löschen müssen…
wget -rl1 -kE -A pdf http://www.swr.de/buffet/guten-appetit/-/id=257024/nid=257024/did=307880/xlslkj/index.html
Um in Amarok ein Hauptgerät einzurichten, muss es einfach in Einstellungen -> Audio Ausgabe eigetragen werden.
Damit das geht muss das Ausgabe-Modul auf Alsa gestellt und die Änderung angewendet werden.
Ein Eintrag für Soundkarte 1 (also die zweite Soundkarte, da die Liste bei 0 anfängt) sieht im einfachsten Fall so aus:
hw:1
Komplexere Konfigurationen können in einer Mail auf den kde mailinglisten nachgelesen werden:
http://mail.kde.org/pipermail/amarok/2006-October/001619.html [353]
Standardmäßig enthalten die Boxen:
Mono: default
Stereo: default
4 Channel: plug:surround40:0
6 Channel: plug:surround51:0
Die zweite Soundkarte könnte auch mit "plughw:1,0" unter Stereo angesprochen werden.
Ich hoffe, es hilft dir!
(und erspart dir die Stunden an Zeit und Nerven, die ich reingesteckt habe, bis ich die einfache Lösung gefunden hatte. Das Internet ist toll, wenn man weiß, nach was man suchen muss :) ... in meinem Fall: google "amarok alsa device" :) )
Ich habe heute mein X auf den freien radeonhd treiber umgestellt, und damit bin ich nun endlich wirklich frei!
Das muss natürlich heißen: Mein Computer nutzt nun nur noch freie Software, nachdem ich endlich die unfreien Graphikkartentreiber rausschmeißen konnte.
Ich hatte leider eine ATI X1300 Karte, die vom alten freien Radeon Treiber nicht unterstützt war.
Update: Der alte freie Radeon treiber unterstützt nun meine Karte in der testing version. Da er aktuell besser Beschleunigung bietet nutze ich zur Zeit also radeon statt radeonhd, aber radeonhd hat dafür den Weg geebnet.
Der neue RadeonHD Treiber unterstützt nun meine Karte, und ich bin glücklich endlich von dem unfreien Treiber weggekommen zu sein.
Der folgende Forenbeitrag hat mir geholfen, alles zum Laufen zu bekommen:
"Basically, I unmasked and emerged xf86-video-radeonhd and set the driver to radeonhd" (ganz unten auf der Seite)
- http://forums.gentoo.org/viewtopic-t-625940-highlight-radeonhd.html [354]
Und der Artikel zum radeonhd Treiber:
- http://forums.gentoo.org/viewtopic-t-606785-highlight-ati+screens.html [355]
Außerdem der passende Eintrag im Gentoo-Wiki:
- http://gentoo-wiki.com/HOWTO_DRI_with_ATi_Open-Source_Drivers [356]
Aber was ich eigentlich nur gemacht habe war:
Meinen Kernel mit Direct Rendering Manager aber ohne Radeo Treiber neu bauen:
Character devices --->/dev/agpgart (AGP Support) Direct Rendering Manager (XFree86 4.1.0 and higher DRI support)
Dann modules.autoload anpassen (ich habe ein nvidia board - Details im Gentoo-Wiki):
vim /etc/modules.autoload.d/kernel-2.6
# babcode: ATI drivers nvidia-agp agpart radeonhd
Die unfreien ATI-treiber rausschmeißen und radeonhd emergen:
emerge -C ati-drivers echo "x11-drivers/xf86-video-radeonhd" >> portage-keywords/hardware emerge x11-drivers/xf86-video-radeonhd
Und am Ende noch die xorg.conf anpassen:
/etc/X11/xorg.conf (*brr* fühlt sich das seltsam an ohne tab-vervollständigung :) )
In Section "Device" muss bei "Driver" "radeonhd" eingetragen werden.
(Ich hatte zwei Abschnitte, in denen ich das machen musste).
Damit habe ich zwar sicher noch nicht die schnellstmögliche EInstellung drin, aber mein Rechner läuft endlich nur noch mit freier Software!
Wenn ihr mehr Leistung rausholen wollt, könnt ihr sicher einige Tipps in den Gentoo Foren [357] und dem Gentoo Wiki finden.
Ich bin Frei!
Yay!
→ als Antwort [358] für PiHalbe geschreiben: „wie kann man an einem Rechner einfach von Skype/mumble/… aufnehmen? [359]“.
Zum Aufnehmen: pulseaudio, parecord. Gilt aber nicht als einfach :)
pactl list | grep -A2 'Quelle #' | grep 'Name:$' | cut -d" " -f2
oder besser:
LANG=C pactl list | grep -A2 'Source #' | grep 'Name:$' | cut -d" " -f2
Das gibt dir deine Geräte.
Bei mir gibt es das:
$ LANG=C pactl list | grep -A2 'Source #' | grep 'Name:' | cut -d" " -f2
alsa_output.pci-0000_00_14.2.analog-stereo.monitor
alsa_output.usb-M_Audio_MobilePre-00-MobilePre.iec958-stereo.monitor
alsa_input.usb-M_Audio_MobilePre-00-MobilePre.iec958-stereo
Dann in der .bashrc:
# record via pulseaudio, usage: `babrecord file.wav`
alias babrecord='parecord -r --format=float32le --file-format'
und in zwei shells:
babrecord [ich.wav] -d [gerät von oben]
babrecord [du.wav] -d [gerät von oben, das auf .monitor endet]
(gefunden via recording from pulseaudio [360] )
Bei mir sieht das so aus:
$ babrecord du.wav -d alsa_output.pci-0000_00_14.2.analog-stereo.monitor & babrecord ich.wav -d alsa_input.usb-M_Audio_MobilePre-00-MobilePre.iec958-stereo &
danach:
fg # in den Vordergrund holen)
Strg-C (Aufnahme stoppen)
fg
Strg-C
am Ende:
$ audacity ich.wav
(du.wav importieren)
fertig.
Ich lege mir seit Jahren in meiner bashrc aliase für komplexere Befehle an, und da ich denke, dass einige davon auch anderen Leuten nützlich sein könnten, habe ich mich entschieden meine bashrc zu veröffentlichen.
Vorher habe ich sie etwas aufgeräumt, damit sie auch lesbar ist, wenn man sie nicht selbst geschrieben hat :)
Wenn ihr Tipps und Ideen dafür habt, schreibt sie einfach in's Kommentarfeld, dafür ist das da :)
Die bashrc ist auch im Anhang zum herunterladen.
====== bashrc ======
# /etc/skel/.bashrc:
# This file is sourced by all *interactive* bash shells on startup. This
# file *should generate no output* or it will break the scp and rcp commands.
# This file is licensed under the LGPLv3 or higher.
# Copyright for the babtools section: © 2007 Arne Babenhauserheide
# colors for ls, etc.
eval `dircolors -b /etc/DIR_COLORS`
alias d="ls --color"
alias ls="ls --color=auto"
alias ll="ls --color -l"
alias grep="grep --color=auto"
alias opencd='eject cdrom0'
alias closecd='eject -t cdrom0'
alias startwmiix='WINDOWMANAGER=wmii startx -- vt8 :1 --nolisten tcp'
#alias emerge='emerge --nospinner --tree '
#### babtools - Miniskripte von Arne Babenhauserheide ####
alias babkernel='cp -v /usr/src/.config-babkernel /usr/src/linux/.config; LC_ALL=C nice genkernel --oldconfig --menuconfig --save-config --evms2 --bootloader=grub all && cp /usr/src/linux/.config /usr/src/.config-babkernel; '
alias babstartvnc='ps wwaux | grep auth | grep A: | sed s/root.*\\/var/\\/var/ | xargs x11vnc -auth'
alias babvncviewer='vncviewer -compresslevel 1 127.0.0.1'
alias babsync='nice layman -S; nice eix-sync ; emerge --regen'
alias babchroot32='xhost local:localhost ; linux32 chroot /mnt/gentoo32 /bin/bash; . /etc/profile ; env-update '
alias babquietportage='vim /usr/lib/portage/bin/emake'
alias babquickpkg_kde='eix -IS kde | grep "\[I\]" | sed "s/ \?\[[I0-9]\] \?//g" | xargs quickpkg'
alias babworldremerge='emerge -e system || until emerge --resume --skipfirst; do emerge -pq --resume >> /home/arne/emerge-remerge-fehler; nice rm -r /var/tmp/portage/* ; emerge --resume --skipfirst; done; emerge -e system || until emerge --resume --skipfirst; do emerge -pq --resume >> /home/arne/emerge-remerge-fehler; nice rm -r /var/tmp/portage/* ; emerge --resume --skipfirst; done; emerge -e world || until emerge --resume --skipfirst; do emerge -pq --resume >> /home/arne/emerge-remerge-fehler; nice rm -r /var/tmp/portage/* ; emerge --resume --skipfirst; done; emerge -e world || until emerge --resume --skipfirst; do emerge -pq --resume >> /home/arne/emerge-remerge-fehler; nice rm -r /var/tmp/portage/* ; emerge --resume --skipfirst; done;'
alias babworldupdate='babsync; emerge -utDN world || until emerge --resume --skipfirst; do date >> /home/arne/emerge-update-fehler; emerge -pq --resume >> /home/arne/emerge-update-fehler; emerge --resume --skipfirst; done '
alias babdate='ntpdate -u de.pool.ntp.org'
alias babmencode='mencoder -o Titel1.avi -oac copy -ovc lavc -lavcopts vcodec=mpeg4:mbd=1:vbitrate=1800:aspect=16/9'
alias babkde4merge='layman -s kde; cat /etc/portage/package.keywords/kde4 | sed s/^\#.*// | sed s/\\*\\*// | sed s/.*kdenetwork.*// | sed s/.*kde-base\\/kde*// | xargs emerge -tDN --oneshot || until emerge --resume --skipfirst; do date >> /home/arne/emerge-kde4-fehler ; emerge -pt --resume >> /home/arne/emerge-kde4-fehler; emerge --resume --skipfirst; done; rm /etc/env.d/44*; env-update;. /etc/profile '
alias babdep_rebuild='nice revdep-rebuild || until emerge --resume --skipfirst; do date >> /home/arne/emerge-kde4-fehler ; emerge -pq --resume >> /home/arne/emerge-update-fehler; nice rm -r /var/distfiles/* ; done'
alias babtar_wolshin='cd ~/Quell/eigenes/Uni/Theoretische\ Physik/TheoPhys2\ \(Elektrodynamik\)/Skript/Wolschin-Skript/; tar -czf theo2-skript-2007-src.tar.gz 2007*.tex stuff.tex skript.tex GPL.txt *.png *.svg pngtops.sh'
alias babjectpod='eject /dev/disk/by-label/Klangfeuer'
alias babdep-rebuild-verbose='revdep-rebuild; until emerge --resume --skipfirst >> /home/arne/emerge-revdep-rebuild; do date >> /home/arne/emerge-revdep-rebuild-fehler ; cat /home/arne/emerge-revdep-rebuild >> /home/arne/emerge-revdep-rebuild-fehler; emerge --resume >> /home/arne/emerge-revdep-rebuild || cat /home/arne/emerge-revdep-rebuild >> /home/arne/emerge-revdep-rebuild-fehler; done;'
#### /babtools ####
# Esperanto - Spanisch - Deutsch - Englisch
# export LANG=eo:es:de:en
# emerge über screen
# alias scremerge="sudo screen emerge --nospinner"
# Change the window title of X terminals
case $TERM in
xterm*|rxvt|Eterm|eterm)
PROMPT_COMMAND='echo -ne "\033]0;${USER}@${HOSTNAME%%.*}:${PWD/$HOME/~}\007"'
;;
screen)
PROMPT_COMMAND='echo -ne "\033_${USER}@${HOSTNAME%%.*}:${PWD/$HOME/~}\033\\"'
;;
esac
##uncomment the following to activate bash-completion:
[ -f /etc/profile.d/bash-completion ] && source /etc/profile.d/bash-completion
export PATH="/home/arne/bin:/usr/local/bin:$PATH"
# Firewire-Platte mounten:
# adds unicode support
#if [ $TERM = "linux" ]
#then
# /usr/bin/unicode_start
#fi
# This line was appended by KDE
# Make sure our customised gtkrc file is loaded.
export GTK2_RC_FILES=$HOME/.gtkrc-2.0
# D-Bus für KDE 4
if test -z "$DBUS_SESSION_BUS_ADDRESS" ; then
eval `dbus-launch --sh-syntax --exit-with-session`
fi
====== /bashrc ======
| Anhang | Größe |
|---|---|
| public-bashrc [361] | 4.73 KB |
Update: Diese Lösung hat mein Problem kurzfristig gefixt - nach einer Weile hatte ich wieder Probleme. Inzwischen habe ich mein System neu aufgesetzt und er läuft wieder.
Ich habe gerade Stunden damit zugebracht, meinen Drucker endlich wieder zum Laufen zu bringen.
Die Lösung war:
cd /dev/bus/usb
chmod o+w */*
ACHTUNG: UNSICHER!
Diese Lösung gibt jedem Nutzer im System Schreibrechte auf die USB-Geräte. Auf keinen Fall auf einem System mit nicht-vertrauenswürdigen Nutzern machen.
Hintergrund:
Probleme:
Einzellösungen und Versuche:
vigrkuser
Außerdem habe ich eine neue udev-regel Datei von SUSE reingehängt: 55-hpmud.rules
-> http://osdir.com/ml/printing.hplip.devel/2007-10/msg00009.html [362]
In Gentoo liegt sie übrigens bei /etc/udev/rules.d/70-hpmud.rules
Ich bin aber nicht sicher, ob das sinnvoll war.
Bitte schreibt, ob euch das hilft, oder ob ich Schritte vergessen habe (und wenn ja, welche).
UPDATE: Zur Zeit nutze ich das Cry-Layout:
- Layout-Bild mit Qualitätsvisualisierung [363]
- xmodmap [364] (aktivieren mit
setxkbmap lv ; xmodmap ~/crie.xmodmap)- xmodmap für Truly Ergonmic 105 [365]
- xmodmap für Truly Ergonomic 109 [366].
Ich habe ein kleines Python Programm [367] geschrieben, um das Neo Tastaturlayout [368] zu prüfen und mit evolutionären Codes zu verbessern.
Inzwischen hat es von verschiedenen Leuten Verbesserungen erfahren, daher ist das „Ich“ oben nur noch eingeschränkt richtig. Dank geht an die wundervolle Neo-Community [178]!
Es braucht Python 3 [304].
Seine Lizenz ist wie üblich GPL [27] (frei).
Das Ziel dabei ist, eine Belegung zu finden, die schnelleres und weniger belastendes Tippen ermöglicht und so hoffentlich hilft, Erkrankungen der Handgelenke durch viel Tippen zu vermeiden.
Ergebnisse der Optimierung schreibe ich dabei meist auf der Mailingliste der Neo-Gemeinschaft [369].
Einige weitere Informationen gibt es auf EvolvedLayouts [370] und Neo3 [371] im Neo-Wiki [372].
Um die Optimierung anschaulich zu machen, gibt der Optimierer Bilder der Buchstabenhäufigkeit und Bigrammübergänge aus (nach einem Design von Wolf).
Hier sind sie für einen Ausschnitt aus der Entwicklung der Tastaturbelegungen erstellt. Hellblaue Übergänge zwischen Buchstaben sind gut, dunkelblaue/lilane sind unschön und gelbe sing grausig.
Qwertz ist die alte, typische und offensichtlich schreckliche Tastaturbelegung (v.a. durch „de“ und „un“), die selbst ihr Erfinder wieder ändern wollte – Remington (der Hersteller der Tastaturen) verweigerte das aber [373]… sowas passiert, wenn man seine revolutionären Erfindungen verkauft…
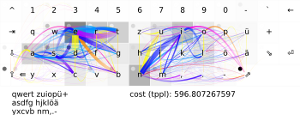
Dvorak ist die verbreitetste optimierte, aber durch z.B. „ei“ nicht für Deutsch geeignet. Sie wurde noch von Hand optimiert.
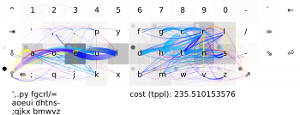
Neo 2 ist die aktuelle Belegung der Neo-Gemeinschaft [178]. Ihre Hauptschwäche sind die Fingerwiederholungen (z.B. „la“).
Haeik ist das Testlayout, das ich seit Februar 2011 nutze, um zu testen, ob es Probleme gibt, die erst bei höheren Tippgeschwindigkeiten auftreten. Seit Anfang März 2011 bin ich wieder bei über 300 Zeichen pro Minute und habe ein paar Anpassungen vorgenommen.
Tnrs ist ein aktuelles Ergebnis des Optimierers [367] (aktuell=2011-03-13).
Die Dicke der Übergänge zeigt die Häufigkeit an. Die Richtung wird durch die Transparenz gezeigt: Von durchsichtig zu vollständig sichtbar. Einwärtsbewegungen machen dabei einen Bogen nach oben, auswärts einen nach unten.
Der Grauton der Tasten gibt die Buchstabenhäufigkeit an und der kleine Punkt zeigt, wie oft das Zeichen am Wortanfang steht. Hell ist selten, dunkel ist oft.
Alle werden erstellt via
./bigramm_statistik.py --svg --svg-output neo2.svg -l "xvlcw khgfqß´
uiaeo snrtdy
üöäpz bm,.j"
(die Belegung wird zwischen den Anführungszeichen eingefügt)
Zur Zeit (2010-08-05) optimiert es auf
Details dazu findest du in der Quelldatei [374] (sollte auch ohne Programmierkenntnisse recht lesbar sein), weitere Informationen zur Optimierung auf EvolvedLayouts [370] und Neo3 [371] im Neo-Wiki [372].
| Anhang | Größe |
|---|---|
| dvorak_klein.png [375] | 37.4 KB |
| haeik_klein.png [376] | 38.43 KB |
| neo2_klein.png [377] | 38.19 KB |
| qwertz_klein.png [378] | 40.05 KB |
| tnrs_klein.png [379] | 37.7 KB |
→ http://draketo.de/deutsch/freie-kultur/licht/testament-fuer-freie-werke
Im Vollbesitz meiner geistigen Kräfte verfüge ich hiermit, dass nach meinem Tod all meine Werke, für die ich ausreichende Rechte habe, unter freien copyleft Lizenzen im Sinne der vier Freiheiten verfügbar sein sollen.
Das heißt, nach meinem Tod dürfen alle Werke, für die ich ausreichend Rechte habe, unter freie Lizenzen relizensiert werden, die den im Folgenden beschriebenen vier Freiheiten genügen und verlangen, dass alle abgeleiteten Werke unter den gleichen Lizenzen oder zumindest unter Lizenzen, die auch diesen Bedingungen genügen, verfügbar sein müssen.
Die genannten vier Freiheiten sind:
gezeichnet
Arne Babenhauserheide
--
Wenn auch ihr mit allen Werken, über die ihr verfügen könnt, zumindest nach eurem Tod freie Kultur unterstützen wollt, dann übernehmt dieses Testament auf eure Seite (es ist frei lizensiert [27]).
Dann schreibt es handschriftlich ab, setzt Ort, Zeit und Datum dazu und unterschreibt es (nach der letzten Zeile).
- (Rechtliche Grundlage [380])
Und wenn ihr einen Anwalt kennt, der bereit wäre, dieses Testament unentgeltlich zu prüfen, würde ich mich sehr freuen, wenn ihr mir von ihm schreibt, oder ihm einfach die Adresse diesser Seite gebt.
Ich habe die letzten Wochen mit dem html5 widget experimentiert und bin dabei auf die wundervolle Seite video for everybody [381] gestoßen.
Carmen von Video for everybody hat seinen Code inzwischen aktualisiert. Schau also am besten direkt auf video for everybody [381] vorbei.
Besonders interessant für mich war der code mit youtube integration, weil dadurch die Notwendigkeit entfällt, selbst einen Flash-Player zu hosten.
Um das nochmal zu wiederholen: Die aktuelle Version gibt es auf video for everybody [381].
Das Prinzip dahinter heißt "graceful degradation": Wenn jemand die bestmögliche Technologie nicht hat, wird automatisch und unsichtbar die zweitbeste Möglichkeit genutzt, und wenn er die nicht hat die nächste, bis am Ende ein Download-Link da steht, mit dem selbst Leute mit Textbrowsern die Videos herunterladen und dann z.B. als Text-Video ansehen [382] können.
Auf die Art kann wirklich Jede/r die Inhalte der Webseite nutzen. Jede/r beinhaltet hier Nutzer auch von iPhones uvm.
Ein Beispiel wie der Code dann aussehen kann (das Beispiel hier verwendet youtube als Quelle für das Flash-Video):
Camen von video for everybody hat den code unter cc-by freigegeben und mir auch per E-Mail nochmal bestätigt, dass ich ihn unter die GPL relizensieren (und daher hier verwenden) kann.
Ich habe daraus ein kleines generisches Codeschnipselchen [389] gebastelt.
Um es zu verwenden musst du nur
Du brauchst dafür außerdem die Videos nur im mp4 und im ogg theora Format (und auf youtube).
Wenn du also Videos auf deiner Seite wirklich sauber einbinden willst, dann lad den generischen Codeschnipsel [389] herunter, editier ihn und benutz ihn auf deiner Seite.
Da meine Schaffenshöhe hier sehr gering ist, kannst du ihn wie das Original auch unter cc-by verwenden, musst also nur sagen, dass er von Camen [393] stammt.
PS: Die Zeilenenden sind *nix-Stil ("\n"). Wenn du keine Zeilenumbrüche siehst, probier mal die Datei mit OpenOffice [394] als Text mit Unix-Zeilenenden und "UTF-8" als Kodierung zu öffnen.
| Anhang | Größe |
|---|---|
| video-done-right-generic.html [389] | 1.65 KB |
| htaccess [390] | 51 Bytes |
Im Institut verwenden wir sowohl Python 2 als auch Python 3. Bei Recherche zu den aktuellen Unterschieden (Python 3.5 im Vergleich mit Python 2.7) habe ich zwei schöne Artikel von Brett Cannon gefunden, dem aktuellen Verwalter von Python, und sie für meine Arbeitsgruppe zusammengefasst.
Die Artikel:
Die für uns relevanten1 Punkte sind:
Was Python3 verbesserte:
Warum 3 in nutzen (für uns relevantes, z.B. für neue Projekte):
Die Auswirkung dieser Aspekte ist nicht zu unterschätzen: Leichteres Debuggen und Vermeidung von Überraschungen und sperrigen Workarounds.
Ich habe sie zusammengefasst, da ich nicht erwarten kann, dass Wissenschaftler (oder andere Leute, die Python nur verwenden) die ganzen Artikel lesen, nur um zu überlegen, was sie machen, wenn sie mal wieder ein neues Projekt angehen wollen. ↩
Beispiel für print():
nums = [1, 2, 3]
with open("data.csv", "a") as f:
print(*nums, sep=";", file=f) ↩
Der Name „Freie Software“ in 62 verschiedenen Sprachen.
Etwa 8 Namen fehlen leider, weil mein Browser die Schriftzeichen nicht kopieren konnte.
Quelle: Artikel zu freier Software auf Wikipedia [399] -> Artikel in anderen Sprachen.
In identi.ca [400] und twitter [401] haben tzk [402], jargon [403], freezombie [404], chaosstar666 [405], akfoerster [406] und ich [407] Akronyme zu dem „Frei“ in Freier Software für verschiedene Sprachen gesucht. Was wir bisher haben:
Wenn du weitere schöne Versionen hast, würde ich mich über einen Kommentar, einen dent oder tweet freuen!
Wie es dazu kam:
Links:
[1] https://www.draketo.de/licht/freie-software/frei-free-libre-akronym
[2] http://www.perspektive89.com/2006/12/15/unfreie_software_eine_gefahr_fur_die_demokratie
[3] http://perspektive89.com/blogtags/freie_software
[4] http://fsfe.org
[5] https://www.draketo.de/english/songs/light
[6] https://www.draketo.de/english/free-software
[7] http://www.wolfire.com/humble
[8] http://twitter.com/Wolfire/status/13804312082
[9] http://twitter.com/Wolfire/status/13758133826
[10] http://www.wolfire.com/lugaru
[11] http://blog.wolfire.com/2010/05/Lugaru-goes-open-source
[12] https://twitter.com/Wolfire/status/13810903041
[13] https://www.draketo.de/light/english/a-humble-million
[14] http://vis.cs.ucdavis.edu/~ogawa/codeswarm/
[15] http://www.vimeo.com/1093745
[16] http://www.vimeo.com/1334189
[17] http://code.google.com/p/codeswarm/wiki/GeneratingAVideo
[18] http://www.gnu.org/software/hurd/
[19] http://www.bddebian.com/~wiki/community/weblogs/ArneBab/2008-07-12-codeswarm-movies-for-the-hurd/
[20] http://rakjar.de/shared_codeswarm/
[21] http://rakjar.de/shared_codeswarm/project_activity_battle_swarm.html
[22] http://rakjar.de/semi_regular_mercurial_codeswarms/
[23] https://www.draketo.de/english/free-software/by-sa-gpl
[24] https://wiki.creativecommons.org/4.0/Compatibility#Potential_compatible_licenses
[25] http://creativecommons.org/licenses/GPL/2.0/
[26] http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
[27] https://www.draketo.de/lizenzen
[28] http://creativecommons.org/licenses/by-nc-sa/3.0/de/
[29] http://creativecommons.org/license/cc-gpl
[30] http://creativecommons.org/license/cc-lgpl
[31] http://www.opensourcejahrbuch.de/download/jb2006/chapter_06/osjb2006-06-01-moeller
[32] http://1w6.org/deutsch/anhang/das-ein-w-rfel-system-jetzt-unter-der-gplv3#comment-261
[33] http://www.gnu.org/software/emacs/
[34] http://de.wikipedia.org/wiki/LISP
[35] http://www.lisperati.com/casting-spels-emacs/html/casting-spels-emacs-1.html
[36] http://de.wikipedia.org/w/index.php?title=Freie_Software&stableid=73122325#Die_Geburt_Freier_Software
[37] https://www.draketo.de/licht/freie-software/darum-emacs-markdown-mode
[38] https://www.draketo.de/light/english/simple-emacs-darkroom
[39] http://www.emacswiki.org/emacs/EmacsOnAndroid
[40] http://emacs-fu.blogspot.com/2010/04/creating-custom-modes-easy-way-with.html
[41] http://www.emacswiki.org/emacs/Rudel
[42] https://www.draketo.de/licht/freie-software/emacs-als-tagebuch
[43] http://www.emacswiki.org/
[44] http://www.emacswiki.org/emacs/ChurchOfEmacs
[45] http://www.vim.org/
[46] http://identi.ca/notice/92711157
[47] http://gnu.org/software/emacs
[48] http://www.emacswiki.org/emacs/MarkdownMode
[49] http://www.emacswiki.org/emacs/LineWrap
[50] https://www.draketo.de/files/2010-03-24-darum-emacs-markdown-mode.png
[51] https://github.com/wanderlust/wanderlust/issues/55
[52] https://www.draketo.de/files/emacs-init-tagebuch
[53] http://jblevins.org/projects/markdown-mode/markdown-mode.el
[54] http://jblevins.org/projects/markdown-mode/
[55] http://stackoverflow.com/a/14731479/7666
[56] http://stackoverflow.com/users/346725/vpit3833
[57] http://stackoverflow.com/users/1130121/konr
[58] https://twitter.com/konr/status/299484276293001217
[59] http://stackoverflow.com/users/1283394/stefan
[60] http://gnu.org/s/guile
[61] http://stackoverflow.com/a/14731479
[62] http://www.jstatsoft.org/v46/i03/
[63] http://www.jstatsoft.org/v46/i03/paper
[64] https://www.draketo.de/licht/freie-software/emacs
[65] http://orgmode.org
[66] https://www.draketo.de/files/org-mode-babel-to-table.png
[67] https://www.draketo.de/light/english/why-i-use-freenet
[68] http://freenetproject.org
[69] https://d6.gnutella2.info/freenet/USK@nwa8lHa271k2QvJ8aa0Ov7IHAV-DFOCFgmDt3X6BpCI,DuQSUZiI~agF8c-6tjsFFGuZ8eICrzWCILB60nT8KKo,AQACAAE/sone/63/
[70] https://d6.gnutella2.info/freenet/USK@xedmmitRTj9-PXJxoPbD7RY1gf9pKi0OcsRmjNPPIU4,AzFWTYV~9-I~eXis14tIkJ4XkF17gIgZrB294LjFXjc,AQACAAE/fmsguide/6/
[71] http://freenetproject.org/
[72] http://127.0.0.1:8888
[73] https://www.draketo.de/deutsch/freenet/frei-sprechen
[74] http://127.0.0.1:8888/friends/?mode=2
[75] https://www.draketo.de/contact
[76] http://gnupg.org
[77] https://www.draketo.de/inhalt/ich/pubkey.txt
[78] http://127.0.0.1:8888/seclevels/
[79] http://wiki.freenetproject.org/Steganography
[80] https://freenetproject.org
[81] https://www.draketo.de/deutsch/freenet/email-vorlage
[82] https://freenetproject.org/download.html#autostart
[83] https://www.draketo.de/deutsch/freenet
[84] http://blog.die-linke.de/digitalelinke/koalition-peitscht-vorratsdatenspeicherung-durch-den-bundestag-die-linke-wehrt-sich-2/
[85] https://de.wikipedia.org/w/index.php?title=Vorratsdatenspeicherung_in_Deutschland&oldid=263380764#Erneute_Verabschiedung_2015
[86] https://netzpolitik.org/2026/gesetzentwurf-vorratsdatenspeicherung-deutlich-laenger-als-drei-monate/?replytocom=2598241
[87] https://www.hyphanet.org
[88] https://www.hyphanet.org/download.html#autostart
[89] https://www.draketo.de/deutsch/freenet/sicher-kommunizieren
[90] http://freesocial.draketo.de/fms_en.html
[91] http://d6.gnutella2.info/freenet/USK@P9~Usj8ZA4ukGv6G-7d7tueqlZx7m5SZ05eS4E4~7Rg,41Vflug56dncema6naDfHNwFS2dXK-wnNFuR382zLdY,AQACAAE/ShareWiki/0/
[92] http://freesocial.draketo.de/flip_en.html
[93] https://digitalcourage.de/blog/2015/protest-gegen-vorratsdatenspeicherung
[94] https://www.draketo.de/english/freenet/forgotten-cryptopunk-paradise
[95] https://twitter.com/Asher_Wolf/status/653555718620971008
[96] http://www.bundestag.de/dokumente/tagesordnungen/tagesordnung_131/383284
[97] http://www.sbs.com.au/news/article/2015/10/13/comment-nothing-hide-data-retention-dignity-and-tampons
[98] https://netzpolitik.org/2015/netzpolitischer-wochenrueckblick-kw-24-der-bundestag-haette-gerne-sein-it-netzwerk-zurueck/
[99] https://www.torproject.org/
[100] https://geti2p.net/de/
[101] http://blog.die-linke.de/digitalelinke/rechtsausschuss-stimmt-fuer-vorratsdatenspeicherung/
[102] https://www.bundesverfassungsgericht.de/SharedDocs/Entscheidungen/DE/2015/09/es20150922_2bve000111.html
[103] https://digitalcourage.de/blog/2016/aktuelles-zur-verfassungsbeschwerde-gegen-die-vorratsdatenspeicherung
[104] http://wissen.dradio.de/index.36.de.html?dram:article_id=3999
[105] http://wissen.dradio.de/
[106] http://www.google.com/trends?q=censorship&ctab=0&geo=all&date=ytd&sort=0
[107] https://www.draketo.de/files/freenet_graphs-2010-11-16-with_trend.png
[108] http://127.0.0.1:8888/USK@gjw6StjZOZ4OAG-pqOxIp5Nk11udQZOrozD4jld42Ac,BYyqgAtc9p0JGbJ~18XU6mtO9ChnBZdf~ttCn48FV7s,AQACAAE/graphs/895/
[109] http://127.0.0.1:8888/USK@85gZTCiQO9IEPDAGvjktO9d-ZMS1lIABR6JB85m4ens,VGDItiCVzCcWAay51faZzcIfAepzeHpzXYvChlueWYE,AQACAAE/stats/1161/
[110] https://www.draketo.de/files/freenet_graphs-2010-12-15-network_size.png
[111] http://freenetproject.org/download.html
[112] http://new-wiki.freenetproject.org/Darknet
[113] http://127.0.0.1:8888/addfriend/
[114] https://www.draketo.de/files/freenet_graphs-2010-11-17-network_size-associated-google-trend.png
[115] https://www.draketo.de/files/freenet_graphs-2010-11-17-network_size.png
[116] https://www.draketo.de/files/freenet_graphs-2010-11-16-with_trend_small.png
[117] https://www.draketo.de/files/freenet_graphs-2010-12-15-network_size_small.png
[118] http://freesocial.draketo.de/wot_en.html
[119] http://freesocial.draketo.de/freemail_en.html
[120] https://www.draketo.de/light/english/freenet/effortless-password-protected-sharing-files
[121] http://draketo.de/proj/freenet-funding/suma-slides.pdf
[122] https://www.noname-ev.de/w/File:FreenetSlides.pdf
[123] https://www.draketo.de/files/2011-04-06-freenet-sone.png
[124] http://freesocial.draketo.de/sone_en.html
[125] http://127.0.0.1:8888/plugins/
[126] http://127.0.0.1:8888/WoT/OwnIdentities
[127] http://127.0.0.1:8888/WoT/KnownIdentities
[128] http://sn.1w6.org/drak/
[129] http://twitter.com/ArneBab/
[130] http://127.0.0.1:8888/Sone/viewSone.html?sone=nwa8lHa271k2QvJ8aa0Ov7IHAV-DFOCFgmDt3X6BpCI
[131] http://gnu.org/licenses/gpl.html
[132] https://github.com/Bombe/Sone/
[133] https://www.draketo.de/files/2011-04-06-freenet-sone_small.png
[134] http://www.golem.de/news/freenet-das-anonyme-netzwerk-mit-der-schmuddelecke-1502-112577.html
[135] https://twitter.com/zambaloelek/status/570699773470248962
[136] http://freesocial.draketo.de/
[137] https://d6.gnutella2.info/freenet/USK@tiYrPDh~fDeH5V7NZjpp~QuubaHwgks88iwlRXXLLWA,yboLMwX1dChz8fWKjmbdtl38HR5uiCOdIUT86ohUyRg,AQACAAE/nerdageddon/173/
[138] https://d6.gnutella2.info/freenet//USK@pxtehd-TmfJwyNUAW2Clk4pwv7Nshyg21NNfXcqzFv4,LTjcTWqvsq3ju6pMGe9Cqb3scvQgECG81hRdgj5WO4s,AQACAAE/statistics/781/week_900x300_plot_datastore.png
[139] https://www.torproject.org/docs/faq.html.en#Torisdifferent
[140] https://freenetproject.org/faq.html#attack
[141] https://wiki.freenetproject.org/Security_summary
[142] https://wiki.freenetproject.org/Opennet_attacks
[143] https://twitter.com/zambaloelek
[144] https://twitter.com/golem
[145] https://twitter.com/ArneBab/status/570705255425576960
[146] https://twitter.com/ArneBab/status/570864497373646848
[147] http://de.wikipedia.org/wiki/Kleine-Welt-Ph%C3%A4nomen
[148] https://www.draketo.de/licht/freie-software/freenet
[149] http://www.heise.de/tp/foren/S-Verwendet-Freenet-Programm-es-ist-zensurfrei-anonym-und-frei-lizensiert/forum-162683/msg-17120481/read/
[150] http://www.heise.de/tp/r4/artikel/30/30762/1.html
[151] https://youtu.be/dZpsBSPsHDI?t=5m56s
[152] https://www.draketo.de/files/2014-11-01-ueber-freenet-verbinden-mail.html
[153] http://127.0.0.1:8888/friends/myref.txt
[154] http://127.0.0.1:8888/friends/
[155] http://127.0.0.1:8888/insertfile/
[156] http://daserste.ndr.de/panorama/archiv/2014/Quellcode-entschluesselt-Beweis-fuer-NSA-Spionage-in-Deutschland,nsa224.html
[157] https://www.noname-ev.de/chaotische_viertelstunde.html#c14h_173
[158] http://youtu.be/sC9ULiB7QrI
[159] https://www.draketo.de/files/2014-11-01-ueber-freenet-verbinden-mail.txt
[160] http://www.draketo.de/proj/freenet-funding/suma-slides.pdf
[161] http://praegnanz.de/weblog/freie-schriften-anspruch-und-wirklichkeit#c022526
[162] http://praegnanz.de/weblog/freie-schriften-anspruch-und-wirklichkeit
[163] http://1w6.org
[164] https://bitbucket.org/ArneBab/1w6/src/679c4edeb3fc/Quelldateien/Schriften
[165] http://blog.stevieswebsite.de/2012/12/open-source-ist-tot/
[166] http://1w6.org/flyer/graswurzel2012
[167] http://pypy.org/py3donate.html
[168] http://www.gnu.org/software/hurd/community/weblogs/ArneBab/niches_for_the_hurd.html
[169] http://www.spreadkde.org/
[170] https://mail.kde.org/mailman/listinfo/kde-promo
[171] http://www.vimeo.com/2097773
[172] http://hurd.gnu.org
[173] http://www.bigchampagne.com/
[174] http://gentoo.org
[175] http://pkgcore.org
[176] http://mczyzewski.com/post/keeping-your-gentoo-clean
[177] http://en.gentoo-wiki.com/wiki/Broadcom_43xx
[178] http://neo-layout.org
[179] http://identi.ca/notice/19279629
[180] http://userbase.kde.org/Konsole
[181] http://www.gentoo.org/proj/de/desktop/x/x11/xorg-server-1.5-upgrade-guide.xml#doc_chap2
[182] http://wiki.neo-layout.org/wiki/Neo%20unter%20Linux%20einrichten
[183] http://neo-layout.org/grafik/aufsteller/neo20-aufsteller.pdf
[184] http://annalist.noblogs.org/post/2009/01/04/bka-ratespielchen-rund-um-gnupg
[185] http://gnupg.org/index.de.html
[186] http://kde.org
[187] https://www.draketo.de/files/2008-02-06-fullscreen-settings-dolphin.png
[188] https://www.draketo.de/files/2008-06-24-desktop.png
[189] https://www.draketo.de/deutsch/freie-software/licht/kde/kde-in-gentoo
[190] https://www.draketo.de/files/2008-06-24-desktop-small.png
[191] http://kde-look.org/content/show.php/KDE+4.3.3+Ghost+and+Dragons?content=115023
[192] https://www.draketo.de/files/screenshot-dragons-ghost-gpl.png
[193] http://kde-look.org/content/show.php/Aurorae+Theme+Engine?content=107158
[194] http://kde-look.org/content/show.php/Ghost+(Aurorae)?content=108675
[195] http://kde-look.org/content/show.php/Ghost?content=107902
[196] http://kde-look.org/content/show.php/Buuf+Deuce+KDE?content=76340
[197] http://www.kde-look.org/content/show.php/Dragons?content=81125
[198] http://www.kde-look.org/content/show.php/Dragons?content=81023
[199] http://dot.kde.org/2010/06/27/first-release-candidate-sc-45-ready-go
[200] https://www.draketo.de/files/2010-06-30-KDE-4.5-rc1-plasma-drak.png
[201] https://www.draketo.de/licht/freie-software/kde/kde-433
[202] http://kde-look.org/content/show.php/Dragons?content=81125
[203] http://blackthumbstudios.artworkfolio.com/gallery/354050
[204] http://kde-look.org/content/show.php/Dragons?content=81023
[205] http://wesnoth.org
[206] http://bitbucket.org/ArneBab/1w6/src/tip/Quelldateien/Wesnoth/
[207] http://www.gentoo.org/proj/en/desktop/kde/#doc_chap2
[208] http://draketo.de/comment/reply/321#comment-form
[209] https://www.draketo.de/files/2010-06-30-plasma-drak.png
[210] https://www.draketo.de/files/2010-06-30-KDE-4.5-rc1-plasma-drak-small.png
[211] http://gentoo-portage.com/kde-base/kdelibs
[212] http://forums.gentoo.org/viewtopic-t-708282.html
[213] http://forums.gentoo.org/viewtopic.php?p=5107843
[214] https://dyscour.se/post/58639636506/named-let
[215] http://www.phyast.pitt.edu/~micheles/scheme/
[216] http://www.phyast.pitt.edu/~micheles/scheme/scheme5.html#there-are-no-for-loops-in-scheme
[217] http://draketo.de/light/english/wisp-lisp-indentation-preprocessor
[218] http://gnu.org/s/guile/
[219] https://www.draketo.de/licht/freie-software/let-rekursion#sec-3
[220] http://python.org
[221] http://validator.w3.org/check?uri=referer
[222] https://www.draketo.de/files/2013-08-11-So-let-rekursion.org
[223] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fib.w
[224] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fib.scm
[225] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fibloop.py_.txt
[226] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fibrek.py_.txt
[227] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fibrek2.py_.txt
[228] https://www.draketo.de/files/2013-08-11-So-let-rekursion-fibrek3.py_.txt
[229] https://www.draketo.de/files/2013-08-11-So-let-rekursion-skipindent.w
[230] https://www.draketo.de/files/2013-08-11-So-let-rekursion-skipindent.scm
[231] http://freedomdefined.org/Licenses
[232] http://lizenz.draketo.de
[233] http://www.gnu.de/documents/gpl.de.html
[234] http://www.gnu.org/licenses/gpl.html
[235] https://creativecommons.org/licenses/by-sa/4.0/
[236] http://www.giese-online.de/gnufdl-de.html
[237] http://www.gnu.org/copyleft/fdl.html
[238] http://artlibre.org/licence/lal/de/
[239] http://artlibre.org/
[240] http://www.webstar.eu.tt/
[241] http://www.heise.de/newsticker/foren/S-GPL-und-BSD/forum-146801/msg-15827542/read/
[242] http://de.wikipedia.org/wiki/BSD-Lizenz
[243] http://www.gnu.de/documents/gpl-3.0.de.html
[244] http://openbsd.org/lyrics.html#42
[245] https://www.draketo.de/light/english/gnu-head-redrawn
[246] http://neo-tastatur.de
[247] http://gnu.org
[248] http://infinite-hands.draketo.de
[249] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-1.JPG
[250] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-2.JPG
[251] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-3.JPG
[252] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-0.JPG
[253] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-1-thumb.JPG
[254] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-2-thumb.JPG
[255] https://www.draketo.de/files/neo-tastatur-mit-gnu-plussy-und-infinite-hands-3-thumb.JPG
[256] http://selenic.com/mercurial
[257] http://bitbucket.org
[258] https://NUTZER:PWD@bitbucket.org/NUTZER/PROJEKT/
[259] https://bitbucket.org/NUTZER/PROJEKT/
[260] http://tortoisehg.bitbucket.org/manual/2.9/quick.html
[261] http://tortoisehg.sf.net
[262] http://www.bitbucket.org/ArneBab/md-esw-2009
[263] http://bitbucket.org/tortoisehg/stable/wiki/intro
[264] http://betterexplained.com/articles/intro-to-distributed-version-control-illustrated/
[265] http://steamlogic.com
[266] http://draketo.de/english/
[267] http://draketo.de/light/english/mercurial/short-introduction-mercurial-tortoisehg
[268] https://www.draketo.de/files/tortoisehg-clone.png
[269] https://www.draketo.de/files/tortoisehg-commit.png
[270] https://www.draketo.de/files/tortoisehg-synchronize.png
[271] https://www.draketo.de/files/tortoisehg-synchronize-pull.png
[272] https://www.draketo.de/files/tortoisehg-update.png
[273] https://www.draketo.de/files/tortoisehg-update-result.png
[274] http://draketo.de/proj/hg-vs-git-server/test-results.html
[275] http://importantshock.wordpress.com/2008/08/07/git-vs-mercurial/
[276] http://joshcarter.com/productivity/svn_hg_git_for_home_directory
[277] http://sayspy.blogspot.com/2006/11/bazaar-vs-mercurial-unscientific.html
[278] http://www.infoq.com/articles/dvcs-guide
[279] http://laserjock.wordpress.com/2008/05/09/bzr-git-and-hg-performance-on-the-linux-tree/
[280] http://bazaar-vcs.org/BzrVsGit
[281] http://bazaar-vcs.org/BzrVsHg
[282] http://www.selenic.com/mercurial/wiki/index.cgi/BzrVsHg
[283] http://blogs.gnome.org/newren/tag/vcses/
[284] http://better-scm.berlios.de/comparison/comparison.html
[285] https://www.draketo.de/deutsch/freie-software/licht/mercurial/hg-vs-git-local-operations-unscientific
[286] http://www.dribin.org/dave/blog/archives/2007/12/30/why_mercurial/
[287] http://docs.google.com/View?docid=dg7fctr4_40dvjkdg64
[288] http://selenic.com/pipermail/mercurial/2008-November/022199.html
[289] http://code.python.org/python/trunk
[290] http://code.python.org/hg/trunk/
[291] https://www.draketo.de/english/free-software/light/mercurial-vs-bazaar-speedtest-clone-and-log
[292] http://www.bitbucket.org/ArneBab/hg-vs-bzr-speedtest-unscientific/
[293] http://bazaar-vcs.org/
[294] http://www.python.org/dev/peps/pep-0374/#why-mercurial-over-other-dvcss
[295] http://www.bitbucket.org/ArneBab/hg-vs-bzr-speedtest-unscientific/src/tip/results/evaluation-2008-12-15.txt
[296] https://www.draketo.de/deutsch/freie-software/licht/dvcs-vergleiche-mercurial-git-bazaar-links
[297] https://www.draketo.de/deutsch/freie-software/licht/python/mercurial-vs-bazaar-link
[298] http://www.selenic.com/mercurial/
[299] http://linux.maruhn.com/sec/lftp.html
[300] http://USER:PASSWORD@freehg.org/u/ArneBab/erynnia/
[301] ftp://FTP_SERVER
[302] http://draketo.de/proj/pymarkdown_minisite/
[303] https://www.draketo.de/deutsch/freie-software/licht/mercurial
[304] http://python.org/download/
[305] https://www.draketo.de/files/blob_swarm-0.3.tar.gz
[306] https://www.draketo.de/files/blob_swarm-0.2.tar.gz
[307] http://python.org/download
[308] https://www.draketo.de/files/blob_valentine-0.3.tar.gz
[309] https://www.draketo.de/files/blob_valentine_screenshot-2008-02-15.png
[310] http://svn.python.org/view/python/trunk/Tools/?rev=38228#dirlist
[311] http://docs.python.org/lib/node740.html
[312] http://www.python.org/doc/current/lib/node738.html
[313] http://www.python.org/doc/current/lib/i18n.html
[314] http://www.python.org/workshops/1997-10/proceedings/loewis.html
[315] http://wiki.wxpython.org/Internationalization
[316] https://www.draketo.de/files/summen.f90
[317] https://www.draketo.de/files/summen.py_.txt
[318] https://www.draketo.de/files/summe.cpp_.txt
[319] https://www.draketo.de/files/summieren_sum.py.txt
[320] https://www.draketo.de/files/summieren_selbst.py.txt
[321] https://www.draketo.de/files/summe.f90__.txt
[322] http://bitbucket.org/ArneBab/python_tests/
[323] https://www.draketo.de/files/for-loops-geschwindigkeitstest.py_2.txt
[324] http://www.riverbankcomputing.co.uk/pyqt/
[325] http://simeonfranklin.com/blog/2012/jul/1/python-decorators-in-12-steps/
[326] http://gnu.org/s/emacs
[327] https://www.draketo.de/files/python_memory_cleaning_test.py_0.txt
[328] http://identi.ca/notice/100260976
[329] http://identi.ca/notice/100258278
[330] https://taz.de/!146693/
[331] http://taz.de
[332] http://gnu.org/s/bash
[333] http://www.horde3d.org/
[334] http://www.panda3d.org/
[335] http://www.ogre3d.org/
[336] http://www.lesfleursdunormal.fr/static/informatique/soya3d/index_en.html
[337] http://www.pyglet.org/
[338] http://www.pygame.org
[339] http://wiki.python.org/moin/GameProgramming
[340] http://www.manning.com/sande/
[341] https://greenteapress.com/wp/think-python-2e/
[342] https://github.com/pairochjulrat/swfk
[343] https://theswissbay.ch/pdf/Gentoomen%20Library/Programming/Python/Snake%20Wrangling%20for%20Kids%20-%20Learning%20to%20Program%20with%20Python%203%2C%20mac-v0.7.7%20%282007%29.pdf
[344] https://www.draketo.de/files/swfk-linux-by-nc-sa.pdf
[345] https://hg.sr.ht/~arnebab/swfk-de
[346] http://www.blender.org/education-help/tutorials/#c836
[347] http://www.ohloh.net/p?query=game
[348] http://www.yofrankie.org/
[349] https://www.draketo.de/licht/politik/leserbriefe/digitaler-diebstahl
[350] http://www.tagesschau.de/inland/telemedien100.html
[351] http://www.gnu.org/software/wget/
[352] http://www.swr.de/buffet/guten-appetit/-/id=257024/nid=257024/did=307880/xlslkj/index.html
[353] http://mail.kde.org/pipermail/amarok/2006-October/001619.html
[354] http://forums.gentoo.org/viewtopic-t-625940-highlight-radeonhd.html
[355] http://forums.gentoo.org/viewtopic-t-606785-highlight-ati+screens.html
[356] http://gentoo-wiki.com/HOWTO_DRI_with_ATi_Open-Source_Drivers
[357] http://forums.gentoo.org
[358] http://pihalbe.org/audio/picast-—-folge-27-—-strategie-ebenen-778#comment-4559
[359] http://pihalbe.org/audio/picast-—-folge-27-—-strategie-ebenen-778
[360] http://www.outflux.net/blog/archives/2009/04/19/recording-from-pulseaudio/
[361] https://www.draketo.de/files/public-bashrc
[362] http://osdir.com/ml/printing.hplip.devel/2007-10/msg00009.html
[363] https://bytebucket.org/ArneBab/evolve-keyboard-layout/raw/8ae830ce6b69bb8b0c67b2d9f2096d7f7bd267dc/empirie/cry.svg
[364] https://bitbucket.org/ArneBab/evolve-keyboard-layout/src/8ae830ce6b69bb8b0c67b2d9f2096d7f7bd267dc/empirie/crie.xmodmap?at=default
[365] https://bitbucket.org/ArneBab/evolve-keyboard-layout/src/8ae830ce6b69bb8b0c67b2d9f2096d7f7bd267dc/empirie/crie-truly.xmodmap?at=default
[366] https://bitbucket.org/ArneBab/evolve-keyboard-layout/src/8ae830ce6b69bb8b0c67b2d9f2096d7f7bd267dc/empirie/crie-truly-109.xmodmap?at=default
[367] http://bitbucket.org/ArneBab/evolve-keyboard-layout/
[368] http://neo-layout.org/
[369] http://lists.neo-layout.org/pipermail/diskussion/
[370] http://wiki.neo-layout.org/wiki/EvolvedLayouts
[371] http://wiki.neo-layout.org/wiki/Neo3
[372] http://wiki.neo-layout.org/
[373] http://wiki.neo-layout.org/wiki/Geschichte
[374] http://bitbucket.org/ArneBab/evolve-keyboard-layout/src/tip/check_neo.py
[375] https://www.draketo.de/files/dvorak_klein.png
[376] https://www.draketo.de/files/haeik_klein.png
[377] https://www.draketo.de/files/neo2_klein.png
[378] https://www.draketo.de/files/qwertz_klein.png
[379] https://www.draketo.de/files/tnrs_klein.png
[380] http://de.wikipedia.org/wiki/Testament
[381] http://camendesign.com/code/video_for_everybody
[382] http://caca.zoy.org/wiki/libcaca
[383] http://infinite-hands.draketo.de/filme/Infinite_Hands-FilkCONtinental2008-only-song.mp4
[384] http://infinite-hands.draketo.de/filme/Infinite_Hands-FilkCONtinental2008-only-song.ogv
[385] http://getfirefox.com
[386] http://apple.com/safari
[387] http://get.adobe.com/flashplayer/
[388] http://apple.com/quicktime/download/
[389] https://www.draketo.de/files/video-done-right-generic.html
[390] https://www.draketo.de/files/htaccess
[391] http://videoencoding.websmith.de/encoding-praxis/encoding-praxis.html
[392] http://en.wikipedia.org/wiki/Theora#Encoding
[393] http://camendesign.com/code/video_for_everybody
[394] http://openoffice.org
[395] http://snarky.ca/why-python-3-exists
[396] http://snarky.ca/how-to-pitch-python-3-to-management
[397] https://identi.ca/notice/19512396
[398] https://identi.ca/notice/19512901
[399] http://de.wikipedia.org/wiki/Freie_Software
[400] http://identi.ca
[401] http://twitter.com
[402] http://identi.ca/tzk
[403] http://identi.ca/jargon
[404] http://identi.ca/freezombie
[405] https://twitter.com/chaosstar666
[406] https://identi.ca/akfoerster
[407] http://identi.ca/arnebab
[408] http://identi.ca/notice/57917956
[409] http://identi.ca/notice/57921152
[410] http://identi.ca/notice/57924448
[411] http://identi.ca/notice/57922710
[412] http://identi.ca/notice/57922988
[413] http://identi.ca/notice/57923509
[414] http://identi.ca/notice/57923772
[415] http://identi.ca/notice/57924486
[416] http://identi.ca/notice/57932179
[417] http://identi.ca/notice/57933334
[418] http://identi.ca/notice/62938271
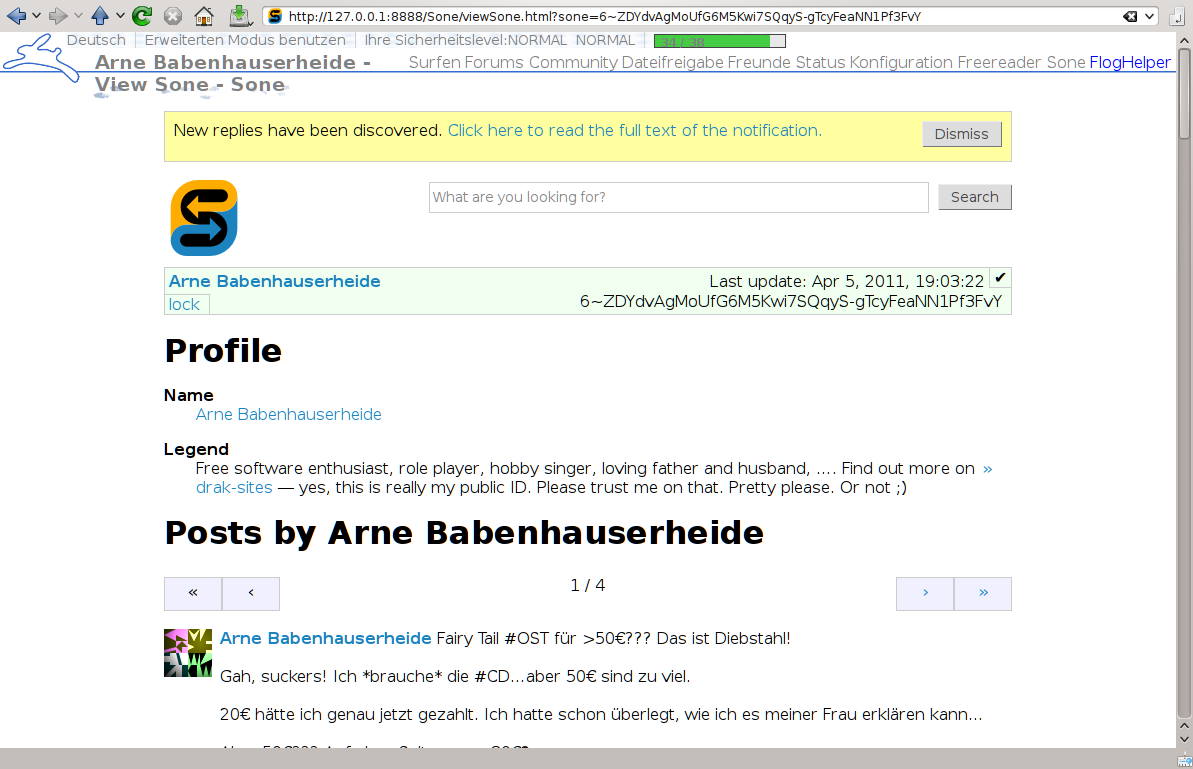
{kind=link}
{kind=link}
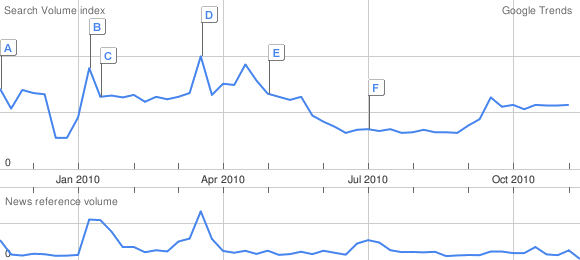{kind=link}
{kind=link}
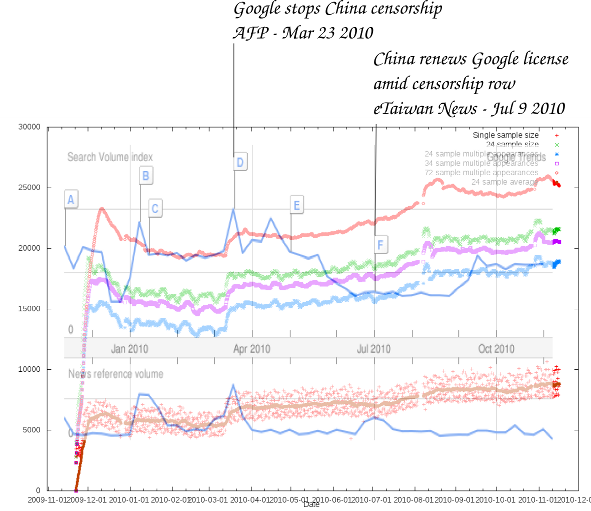{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}