Git
Conveniently merge a NEWS file without conflicts
Do, 06/09/2016 - 19:42 — DraketoWriting a NEWS file (a list of changes per version, targeted at end-users) significantly reduces the effort for doing a release: To write your release notes, just copy the latest entries from the NEWS file into a message. It is one of the gems in the GNU coding standards: Simple yet extremely useful. (For a detailed realization, refer to the Perl Specification for CPAN Changes files.)
However when you’re developing features in parallel, for example by using a pull-request workflow and requiring contributors to update the NEWS file, you will often run into merge conflicts. Resolving these takes time, though the resolution is trivial: Just use the lines from both heads.
To resolve the problem, you can set your version tracking system to use union-merge for NEWS files.
- Login to post comments
- Weiterlesen
git vs. hg - offensive
Mi, 02/19/2014 - 22:09 — DraketoIn many discussions on DVCS over the years I have been fair, friendly and technical while receiving vitriol and misinformation and FUD. This strip visualizes the impression which stuck to my mind when speaking with casual git-users.
Update: I found a very calm discussion at a place where I did not expect it: reddit. I’m sorry to you, guys. Thank you for proving that a constructive discussion is possible from both sides! I hope that you are not among the ones offended by this strip.
To Hg-users: There are git users who really understand what they are doing and who stick to arguments and friendly competition. This comic arose from the many frustrating experiences with the many other git users. Please don’t let this strip trick you into going down to non-constructive arguments. Let’s stay friendly. I already feel slightly bad about this short move into competition-like visualization for a topic where I much prefer friendly, constructive discussions. But it sucks to see contributors stumble over git, so I think it was time for this.
»I also think that git isn’t the most beginner-friendly program. That’s why I’m using only its elementary features«
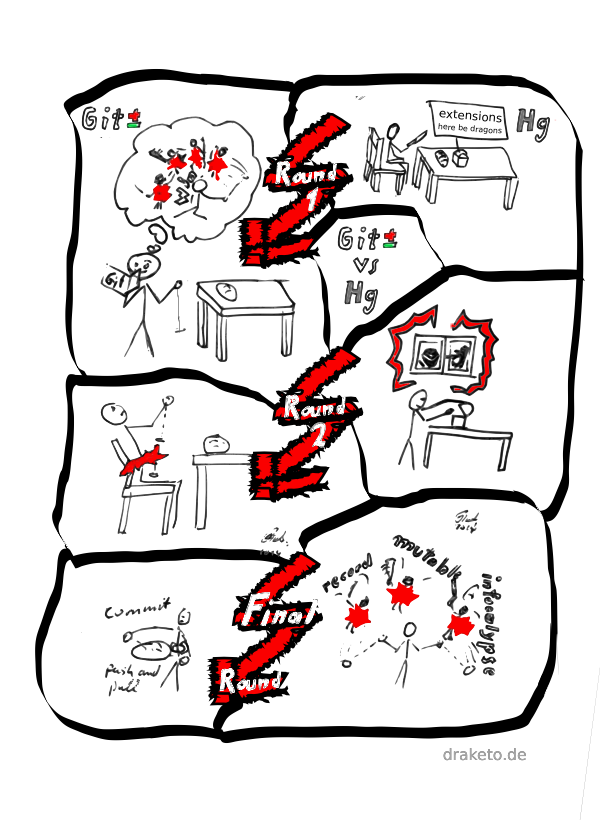
To put the strip in words, let’s complete the quote:
»I also think that git isn’t the most beginner-friendly program.
That’s why I’m using only its elementary features«
<ArneBab> I hear that from many git-users…
»oh, maybe I should have another look at hg after all«
Why this?
Because there are far too many Git-Users who only dare using the most basic commands which makes git at best useless and at worst harmful.
This is not the fault of the users. It is the fault of the tool.
This strip is horrible!
If you are offended by this strip: You knew the title when you came here, right?
And if you are offended enough, that you want to make your own strip and set things right, go grab the source-file, fire up krita and go for it! This strip is free.1
Commentary
If you feel that this strip fits Mercurial and Git perfectly, keep in mind, that this is only one aspect of the situation, and that using Git is still much better than being forced to use centralized or proprietary version tracking (and people who survive the initial phase mostly unscarred can actually do the same with Git as they could with Mercurial).
-
All the graphics in this strip are available under free licenses: creative-commons attribution or GPLv3 or later — you decide which of those you use. If it is cc attribution, call me Arne Babenhauserheide and link to this article. You’ll find all the sources as well as some preliminary works and SVGs in git-vs-hg-offensive.tar_.gz or git-vs-hg-offensive.zip (whichever you prefer)


- Login to post comments
- Weiterlesen
Factual Errors in “Git vs Mercurial: Why Git?” -- and corrections shown by example
Fr, 01/31/2014 - 16:42 — DraketoUpdate 2016: Instead of fixing the article, the Atlassian web workers removed the comments which point out the misinformation in the article. *sigh*
Summary:
In the Atlassian Blog, a Git proponent spread blatant misinformation which the Atlassian folks are leaving uncommented even though the falseness has been shown by multiple people and even in examples in the article itself.
The claims and corrections:
- Claim: Git never loses unreferenced data. Mercurial needs special handling to retrieve unreferenced data. Reality: Due to automatic garbage collection, history editing in git unpredictably loses unreferenced history while Mercurial stores permanent backups which can be retrieved with core commands.
- Claim: Only git branches are namespaced. Reality: Mercurial bookmarks are namespaced with
bookmark@path, when there could be confusion. This is equivalent to git’s use ofpath/branch, but only used where it is needed, while git forces the user to always make that distinction. - Claim: Only git can provide a staging area. Reality: Activating mercurial queues (
mq) and the record extension provides a staging area like the git index — for those who want it. - Claim: Git is more powerful. Reality: Both have the same raw power (as proven by transparent access with Mercurial to Git repos via hg-git), but
- its “cuddly command line” gives Mercurial an efficiency during actual usage which most people do not find in Git.
2 years ago, Atlassian developer Charles O’Farrell published the article Git vs. Mercurial: Why Git? in which he claimed to show "the winning side of Git”. This article was part of the Dev Tools series at Atlassian and written as a reply to the article Why Mercurial?. It was spiced with so much misinformation about Mercurial (statements which were factually wrong) that the comments exploded right away. But the article was never corrected. Just now I was referred to the text again, and I decided to do what I should have done 2 years ago: Write an answer which debunks the myths.
“I also think that git isn’t the most beginner-friendly program. That’s why I’m only using its elementary features” — “I hear that from many git-users …” — part of the discussion which got me to write this article
Table of Contents
- Login to post comments
- Weiterlesen
Basic usecases for DVCS: Workflow Failures
Mi, 04/17/2013 - 18:51 — DraketoIf you came here searching for a way to set the username in Mercurial: just run
hg config --editand add
[ui]
username = YOURNAME <EMAIL>
to the file which gets opened. If you have a very old version of Mercurial (<3.0), open$HOME/.hgrcmanually.Update (2015-02-05): For the Git breakage there is now a partial solution in Git v2.3.0: You can push into a checked out branch when you prepare the target repo via
git config receive.denyCurrentBranch updateInstead, but only if nothing was changed there. This does not fully address the workflow breakage (the success of the operation is still state-dependent), but at least it makes it work. With Git providing a partial solution for the breakage I reported and Mercurial providing a full solution since 2014-05-01, I call this blog post a success. Thank you Git and Mercurial devs!Update (2014-05-01): The Mercurial breakage is fixed in Mercurial 3.0: When you commit without username it now says “Abort: no username supplied (use "hg config --edit" to set your username)”. The editor shows a template with a commented-out field for the username. Just put your name and email after the pre-filled
username =and save the file. The Git breakage still exists.Update (2013-04-18): In #mercurial @ irc.freenode.net there were discussions yesterday for improving the help output if you do not have your username setup, yet.
1 Intro
I recently tried contributing to a new project again, and I was quite surprised which hurdles can be in your way, when you did not setup your environment, yet.
So I decided to put together a small test for the basic workflow: Cloning a project, doing and testing a change and pushing it back.
I did that for Git and Mercurial, because both break at different points.
I’ll express the basic usecase in Subversion:
- svn checkout [project]
- (hack, test, repeat)
- (request commit rights)
- svn commit -m "added X"
You can also replace the request for commit rights with creating a patch and sending it to a mailing list. But let’s take the easiest case of a new contributor who is directly welcomed into the project as trusted committer.

A slightly more advanced workflow adds testing in a clean tree. In Subversion it looks almost like the simple commit:

- Login to post comments
- Weiterlesen
A complete Mercurial branching strategy
Di, 08/14/2012 - 23:54 — DraketoNew version: draketo.de/software/mercurial-branching-strategy
This is a complete collaboration model for Mercurial. It shows you all the actions you may need to take, except for the basics already found in other tutorials like
- Mercurial in workflows (official guide, 15 minutes)
- hg init (more graphics and for Windows)
- hg init science (slides 12 to 23)
Adaptions optimize the model for special needs like maintaining multiple releases1, grafting micro-releases and an explicit code review stage.
Summary: 3 simple rules
Any model to be used by people should consist of simple, consistent rules. Programming is complex enough without having to worry about elaborate branching directives. Therefore this model boils down to 3 simple rules:
(1) you do all the work on
default2 - except for hotfixes.(2) on
stableyou only do hotfixes, merges for release3 and tagging for release. Only maintainers4 touch stable.(3) you can use arbitrary feature-branches5, as long as you don’t call them
defaultorstable. They always start at default (since you do all the work on default).
Diagram
To visualize the structure, here’s a 3-tiered diagram. To the left are the actions of programmers (commits and feature branches) and in the center the tasks for maintainers (release and hotfix). The users to the right just use the stable branch.6
An overview of the branching strategy. Click the image to get the emacs org-mode ditaa-source.
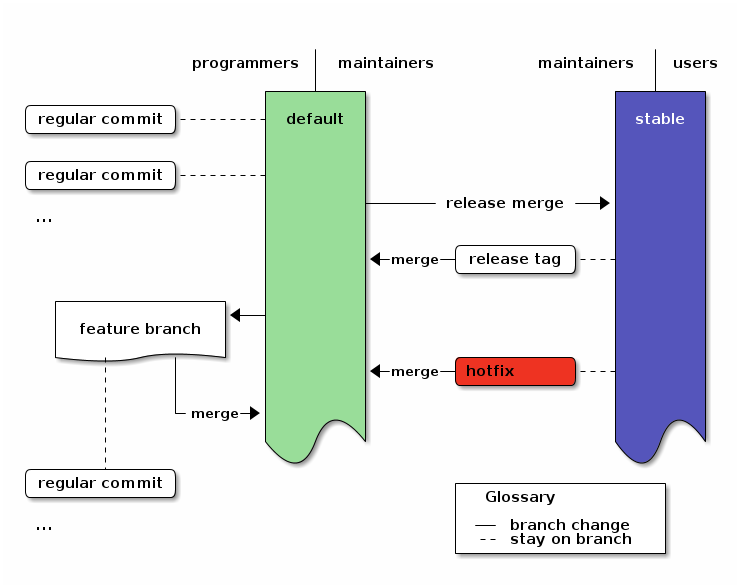
Table of Contents
Practial Actions
Now we can look at all the actions you will ever need to do in this model:7
Regular development
commit changes:
(edit); hg ci -m "message"continue development after a release:
hg update; (edit); hg ci -m "message"
Feature Branches
start a larger feature:
hg branch feature-x; (edit); hg ci -m "message"continue with the feature:
hg update feature-x; (edit); hg ci -m "message"merge the feature:
hg update default; hg merge feature-x; hg ci -m "merged feature x into default"close and merge the feature when you are done:
hg update feature-x; hg ci --close-branch -m "finished feature x"; hg update default; hg merge feature-x; hg ci -m "merged finished feature x into default"
Tasks for Maintainers
-
create the repo:
hg init reponame; cd reponamefirst commit:
(edit); hg ci -m "message"create the stable branch and do the first release:
hg branch stable; hg tag tagname; hg up default; hg merge stable; hg ci -m "merge stable into default: ready for more development"
apply a hotfix8:
hg up stable; (edit); hg ci -m "message"; hg up default; hg merge stable; hg ci -m "merge stable into default: ready for more development"do a release9:
hg up stable; hg merge default; hg ci -m "(description of the main changes since the last release)" ; hg tag tagname; hg up default ; hg merge stable ; hg ci -m "merged stable into default: ready for more development"
-
That’s it. All that follows are a detailed example which goes through all actions one-by-one, adaptions to this workflow and the final summary.
-
if you need to maintain multiple very different releases simultanously, see ⁰ or 10 for adaptions ↩
-
defaultis the default branch. That’s the named branch you use when you don’t explicitely set a branch. Its alias is the empty string, so if no branch is shown in the log (hg log), you’re on the default branch. Thanks to John for asking! ↩ -
If you want to release the changes from
defaultin smaller chunks, you can also graft specific changes into a release preparation branch and merge that instead of directly merging default into stable. This can be useful to get real-life testing of the distinct parts. For details see the extension Graft changes into micro-releases. ↩ -
Maintainers are those who do releases, while they do a release. At any other time, they follow the same patterns as everyone else. If the release tasks seem a bit long, keep in mind that you only need them when you do the release. Their goal is to make regular development as easy as possible, so you can tell your non-releasing colleagues “just work on default and everything will be fine”. ↩
-
This model does not use bookmarks, because they don’t offer benefits which outweight the cost of introducing another concept: If you use bookmarks for differenciating lines of development, you have to define the canonical revision to clone by setting the
@bookmark. For local work and small features, bookmarks can be used quite well, though, and since this model does not define their use, it also does not limit it.
Additionally bookmarks could be useful for feature branches, if you use many of them (in that case reusing names is a real danger and not just a rare annoyance) or if you use release branches:
“What are people working on right now?” →hg bookmarks
“Which lines of development do we have in the project?” →hg branches↩ -
Those users who want external verification can restrict themselves to the tagged releases - potentially GPG signed by trusted 3rd-party reviewers. GPG signatures are treated like hotfixes: reviewers sign on stable (via
hg signwithout options) and merge into default. Signing directly on stable reduces the possibility of signing the wrong revision. ↩ -
hg pullandhg pushto transfer changes andhg mergewhen you have multiple heads on one branch are implied in the actions: you can use any kind of repository structure and synchronization scheme. The practical actions only assume that you synchronize your repositories with the other contributors at some point. ↩ -
Here a hotfix is defined as a fix which must be applied quickly out-of-order, for example to fix a security hole. It prompts a bugfix-release which only contains already stable and tested changes plus the hotfix. ↩
-
If your project needs a certain release preparation phase (like translations), then you can simply assign a task branch. Instead of merging to stable, you merge to the task branch, and once the task is done, you merge the task branch to stable. An Example: Assume that you need to update translations before you release anything. (next part: init: you only need this once) When you want to do the first release which needs to be translated, you update to the revision from which you want to make the release and create the “translation” branch:
hg update default; hg branch translation; hg commit -m "prepared the translation branch". All translators now update to the translation branch and do the translations. Then you merge it into stable:hg update stable; hg merge translation; hg ci -m "merged translated source for release". After the release you merge stable back into default as usual. (regular releases) If you want to start translating the next time, you just merge the revision to release into the translation branch:hg update translation; hg merge default; hg commit -m "prepared translation branch". Afterwards you merge “translation” into stable and proceed as usual. ↩ -
If you want to adapt the model to multiple very distinct releases, simply add multiple release-branches (i.e.
release-x). Thenhg graftthe changes you want to use from default or stable into the releases and merge the releases into stable to ensure that the relationship of their changes to current changes is clear, recorded and will be applied automatically by Mercurial in future merges11. If you use multiple tagged releases, you need to merge the releases into each other in order - starting from the oldest and finishing by merging the most recent one into stable - to record the same information as with release branches. Additionally it is considered impolite to other developers to keep multiple heads in one branch, because with multiple heads other developers do not know the canonical tip of the branch which they should use to make their changes - or in case of stable, which head they should merge to for preparing the next release. That’s why you are likely better off creating a branch per release, if you want to maintain many very different releases for a long time. If you only use tags on stable for releases, you need one merge per maintained release to create a bugfix version of one old release. By adding release branches, you reduce that overhead to one single merge to stable per affected release by stating clearly, that changes to old versions should never affect new versions, except if those changes are explicitely merged into the new versions. If the bugfix affects all releases, release branches require two times as many actions as tagged releases, though: You need to graft the bugfix into every release and merge the release into stable.12 ↩ -
If for example you want to ignore that change to an old release for new releases, you simply merge the old release into stable and use
hg revert --all -r stablebefore committing the merge. ↩ -
A rule of thumb for deciding between tagged releases and release branches is: If you only have a few releases you maintain at the same time, use tagged releases. If you expect that most bugfixes will apply to all releases, starting with some old release, just use tagged releases. If bugfixes will only apply to one release and the current development, use tagged releases and merge hotfixes only to stable. If most bugfixes will only apply to one release and not to the current development, use release branches. ↩
- Login to post comments
- Weiterlesen
Leistungstests und Vergleiche, DVCS: Mercurial (hg) vs. Git vs. Bazaar(bzr), ...
Fr, 05/30/2008 - 08:38 — DraketoVergleiche | Comparisions
| Es gibt inzwischen einige schöne Vergleiche von verschiedenen verteilten Versionsverwaltungssystemen im Netz, und da ich sie sowieso lese, habe ich hier jetzt eine Linkliste erstellt. | There is now a nice collection of comparisions between distributed version tracking systems, and since I read them anyway, I decided to create a list of links. |
Englisch
Diese Seite nutzt Cookies. Und Bilder. Manchmal auch Text. Eins davon muss ich wohl erwähnen — sagen die meisten anderen, und ich habe grade keine Zeit, Rechtstexte dazu zu lesen…