Light
Sending email to many people with Emacs Wanderlust
Sa, 11/10/2012 - 17:08 — DraketoI recently needed to send an email to many people1.
Putting all of them into the BCC field did not work (mail rejected by provider) and when I split it into 2 emails, many did not see my mail because it was flagged as potential spam (they were not in the To-Field)2.
I did not want to put them all into the To-Field, because that would have spread their email-addresses around, which many would not want3.
So I needed a different solution. Which I found in the extensibility of emacs and wanderlust4. It now carries the name wl-draft-send-to-multiple-receivers-from-buffer.
You simply write the email as usual via wl-draft, then put all email addresses you want write to into a buffer and call M-x wl-draft-send-to-multiple-receivers-from-buffer. It asks you about the buffer with email addresses, then shows you all addresses and asks for confirmation.
Then it sends one email after the other, with a randomized wait of 0-10 seconds between messages to avoid flagging as spam.
If you want to use it, just add the following to your .emacs:
(defun wl-draft-clean-mail-address (address) (replace-regexp-in-string "," "" address))
(defun wl-draft-send-to-multiple-receivers (addresses) (loop for address in addresses do (progn (wl-user-agent-insert-header "To" (wl-draft-clean-mail-address address)) (let ((wl-interactive-send nil)) (wl-draft-send)) (sleep-for (random 10)))))
(defun wl-draft-send-to-multiple-receivers-from-buffer (&optional addresses-buffer-name) "Send a mail to multiple recipients - one recipient at a time" (interactive "BBuffer with one address per line") (let ((addresses nil)) (with-current-buffer addresses-buffer-name (setq addresses (split-string (buffer-string) "\n"))) (if (y-or-n-p (concat "Send this mail to " (mapconcat 'identity addresses ", "))) (wl-draft-send-to-multiple-receivers addresses))))
Happy Hacking!
-
The email was about the birth of my second child, and I wanted to inform all people I care about (of whom I have the email address), which amounted to 220 recipients. ↩
-
Naturally this technique could be used for real spamming, but to be frank: People who send spam won’t need it. They will already have much more sophisticated methods. This little trick just reduces the inconvenience brought upon us by the measures which are necessary due to spam. Otherwise I could just send a mail with 1000 receivers in the BCC field - which is how it should be. ↩
-
It only needs one careless friend, and your connections to others get tracked in facebook and the likes. For more information on Facebook, see Stallman about Facebook. ↩
-
Sure, there are also template mails and all such, but learning to use these would consume just as much time as extending emacs - and would be much less flexible: Should I need other ways to transform my mails, I’ll be able to just reuse my code. ↩
- Login to post comments
Bootstrapping the Freenet WoT with GnuPG - and GnuPG with Freenet
Do, 08/16/2012 - 23:38 — DraketoIntro
When you enter the freenet Web of Trust, you first need to get some trust from people by solving captchas. And even when people trust you somehow, you have no way to prove your identity in an automatic way, so you can’t create identities which freenet can label as trusted without manual intervention from your side.
Proposal
To change this, we can use the Web of Trust used in GnuPG to infer trust relationships between freenet WoT IDs.
Practically that means:
- Write a message: “I am the WoT ID USK@
” (replace with the
- Login to post comments
- Weiterlesen
Anonymous against trapwire - on camera??
Do, 08/16/2012 - 22:59 — DraketoAn answer to a reddit-comment by tedemang to the article 1540 Anonymous vs. TrapWire: "We must, at all costs, shut this system down and render it useless".
- Login to post comments
- Weiterlesen
Easily converting ris-citations to bibtex with emacs and bibutils
Do, 08/16/2012 - 12:44 — DraketoThe problem
Nature only gives me ris-formatted citations, but I use bibtex.
Also ris is far from human readable.
The background
ris can be reformatted to bibtext, but doing that manually disturbs my workflow when getting references while taking note about a paper in emacs.
I tend to search online for references, often just using google scholar, so when I find a ris reference, the first data I get for the ris-citation is a link.
The solution
- Login to post comments
- Weiterlesen
Emacs
Mi, 08/15/2012 - 14:57 — DraketoCross platform, Free Software, almost all features you can think of, graphical and in the shell: Learn once, use for everything.
» Get Emacs «
Emacs is a self-documenting, extensible editor, a development environment and a platform for lisp-programs - for example programs to make programming easier, but also for todo-lists on steroids, reading email, posting to identi.ca, and a host of other stuff (learn lisp).
It is one of the origins of GNU and free software (Emacs History).
In Markdown-mode it looks like this:
- Login to post comments
- Weiterlesen
A complete Mercurial branching strategy
Di, 08/14/2012 - 23:54 — DraketoNew version: draketo.de/software/mercurial-branching-strategy
This is a complete collaboration model for Mercurial. It shows you all the actions you may need to take, except for the basics already found in other tutorials like
- Mercurial in workflows (official guide, 15 minutes)
- hg init (more graphics and for Windows)
- hg init science (slides 12 to 23)
Adaptions optimize the model for special needs like maintaining multiple releases1, grafting micro-releases and an explicit code review stage.
Summary: 3 simple rules
Any model to be used by people should consist of simple, consistent rules. Programming is complex enough without having to worry about elaborate branching directives. Therefore this model boils down to 3 simple rules:
(1) you do all the work on
default2 - except for hotfixes.(2) on
stableyou only do hotfixes, merges for release3 and tagging for release. Only maintainers4 touch stable.(3) you can use arbitrary feature-branches5, as long as you don’t call them
defaultorstable. They always start at default (since you do all the work on default).
Diagram
To visualize the structure, here’s a 3-tiered diagram. To the left are the actions of programmers (commits and feature branches) and in the center the tasks for maintainers (release and hotfix). The users to the right just use the stable branch.6
An overview of the branching strategy. Click the image to get the emacs org-mode ditaa-source.
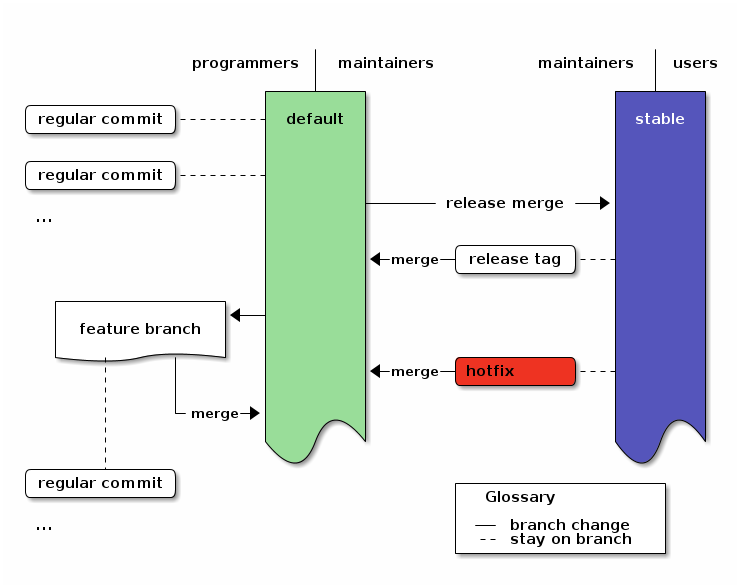
Table of Contents
Practial Actions
Now we can look at all the actions you will ever need to do in this model:7
Regular development
commit changes:
(edit); hg ci -m "message"continue development after a release:
hg update; (edit); hg ci -m "message"
Feature Branches
start a larger feature:
hg branch feature-x; (edit); hg ci -m "message"continue with the feature:
hg update feature-x; (edit); hg ci -m "message"merge the feature:
hg update default; hg merge feature-x; hg ci -m "merged feature x into default"close and merge the feature when you are done:
hg update feature-x; hg ci --close-branch -m "finished feature x"; hg update default; hg merge feature-x; hg ci -m "merged finished feature x into default"
Tasks for Maintainers
-
create the repo:
hg init reponame; cd reponamefirst commit:
(edit); hg ci -m "message"create the stable branch and do the first release:
hg branch stable; hg tag tagname; hg up default; hg merge stable; hg ci -m "merge stable into default: ready for more development"
apply a hotfix8:
hg up stable; (edit); hg ci -m "message"; hg up default; hg merge stable; hg ci -m "merge stable into default: ready for more development"do a release9:
hg up stable; hg merge default; hg ci -m "(description of the main changes since the last release)" ; hg tag tagname; hg up default ; hg merge stable ; hg ci -m "merged stable into default: ready for more development"
-
That’s it. All that follows are a detailed example which goes through all actions one-by-one, adaptions to this workflow and the final summary.
-
if you need to maintain multiple very different releases simultanously, see ⁰ or 10 for adaptions ↩
-
defaultis the default branch. That’s the named branch you use when you don’t explicitely set a branch. Its alias is the empty string, so if no branch is shown in the log (hg log), you’re on the default branch. Thanks to John for asking! ↩ -
If you want to release the changes from
defaultin smaller chunks, you can also graft specific changes into a release preparation branch and merge that instead of directly merging default into stable. This can be useful to get real-life testing of the distinct parts. For details see the extension Graft changes into micro-releases. ↩ -
Maintainers are those who do releases, while they do a release. At any other time, they follow the same patterns as everyone else. If the release tasks seem a bit long, keep in mind that you only need them when you do the release. Their goal is to make regular development as easy as possible, so you can tell your non-releasing colleagues “just work on default and everything will be fine”. ↩
-
This model does not use bookmarks, because they don’t offer benefits which outweight the cost of introducing another concept: If you use bookmarks for differenciating lines of development, you have to define the canonical revision to clone by setting the
@bookmark. For local work and small features, bookmarks can be used quite well, though, and since this model does not define their use, it also does not limit it.
Additionally bookmarks could be useful for feature branches, if you use many of them (in that case reusing names is a real danger and not just a rare annoyance) or if you use release branches:
“What are people working on right now?” →hg bookmarks
“Which lines of development do we have in the project?” →hg branches↩ -
Those users who want external verification can restrict themselves to the tagged releases - potentially GPG signed by trusted 3rd-party reviewers. GPG signatures are treated like hotfixes: reviewers sign on stable (via
hg signwithout options) and merge into default. Signing directly on stable reduces the possibility of signing the wrong revision. ↩ -
hg pullandhg pushto transfer changes andhg mergewhen you have multiple heads on one branch are implied in the actions: you can use any kind of repository structure and synchronization scheme. The practical actions only assume that you synchronize your repositories with the other contributors at some point. ↩ -
Here a hotfix is defined as a fix which must be applied quickly out-of-order, for example to fix a security hole. It prompts a bugfix-release which only contains already stable and tested changes plus the hotfix. ↩
-
If your project needs a certain release preparation phase (like translations), then you can simply assign a task branch. Instead of merging to stable, you merge to the task branch, and once the task is done, you merge the task branch to stable. An Example: Assume that you need to update translations before you release anything. (next part: init: you only need this once) When you want to do the first release which needs to be translated, you update to the revision from which you want to make the release and create the “translation” branch:
hg update default; hg branch translation; hg commit -m "prepared the translation branch". All translators now update to the translation branch and do the translations. Then you merge it into stable:hg update stable; hg merge translation; hg ci -m "merged translated source for release". After the release you merge stable back into default as usual. (regular releases) If you want to start translating the next time, you just merge the revision to release into the translation branch:hg update translation; hg merge default; hg commit -m "prepared translation branch". Afterwards you merge “translation” into stable and proceed as usual. ↩ -
If you want to adapt the model to multiple very distinct releases, simply add multiple release-branches (i.e.
release-x). Thenhg graftthe changes you want to use from default or stable into the releases and merge the releases into stable to ensure that the relationship of their changes to current changes is clear, recorded and will be applied automatically by Mercurial in future merges11. If you use multiple tagged releases, you need to merge the releases into each other in order - starting from the oldest and finishing by merging the most recent one into stable - to record the same information as with release branches. Additionally it is considered impolite to other developers to keep multiple heads in one branch, because with multiple heads other developers do not know the canonical tip of the branch which they should use to make their changes - or in case of stable, which head they should merge to for preparing the next release. That’s why you are likely better off creating a branch per release, if you want to maintain many very different releases for a long time. If you only use tags on stable for releases, you need one merge per maintained release to create a bugfix version of one old release. By adding release branches, you reduce that overhead to one single merge to stable per affected release by stating clearly, that changes to old versions should never affect new versions, except if those changes are explicitely merged into the new versions. If the bugfix affects all releases, release branches require two times as many actions as tagged releases, though: You need to graft the bugfix into every release and merge the release into stable.12 ↩ -
If for example you want to ignore that change to an old release for new releases, you simply merge the old release into stable and use
hg revert --all -r stablebefore committing the merge. ↩ -
A rule of thumb for deciding between tagged releases and release branches is: If you only have a few releases you maintain at the same time, use tagged releases. If you expect that most bugfixes will apply to all releases, starting with some old release, just use tagged releases. If bugfixes will only apply to one release and the current development, use tagged releases and merge hotfixes only to stable. If most bugfixes will only apply to one release and not to the current development, use release branches. ↩
- Login to post comments
- Weiterlesen
Creating nice logs with revsets in Mercurial
Di, 08/14/2012 - 13:22 — DraketoIn the mercurial list Stanimir Stamenkov asked how to get rid of intermediate merges in the log to simplify reading the history (and to not care about missing some of the details).
Update: Since Mercurial 2.4 you can simply use
hg log -Gr "branchpoint()"
I did some tests for that and I think the nicest representation I found is this:
hg log -Gr "(all() - merge()) or head()"
This article shows examples for this.
- Login to post comments
- Weiterlesen
What can Freenet do well already?
Mo, 08/13/2012 - 01:28 — DraketoFrom the #freenet IRC channel at freenode.net:
toad_1: what can freenet do well already?
- sharing and retrieving files asynchronously, freemail, IRC2, publishing sites without need of a central server, sharing code repositories
-
toad alias Matthew Toseland is the main developer of freenet. He tends to see more of the remaining challenges and fewer of the achievements than me - which is a pretty good trait for someone who builds a system to which we might have to entrust our basic right of free speech if the world goes on like this. From a PR perspective it is a pretty horrible trait, though, because he tends to forget to tell people what freenet can already do well :) ↩
- Login to post comments
- Weiterlesen
Recipes for presentations with beamer latex using emacs org-mode
Mi, 08/08/2012 - 19:42 — DraketoI wrote some recipes for creating the kinds of slides I need with emacs org-mode export to beamer latex.
Update: Read ox-beamer to see how to adapt this to work with the new export engine in org-mode 0.8.

Below is an html export of the org-mode file. Naturally it does not look as impressive as the real slides, but it captures all the sources, so I think it has some value.
Note: To be able to use the simple block-creation commands, you need to add #+startup: beamer to the header of your file or explicitely activate org-beamer with M-x org-beamer-mode.
PS: I hereby allow use of these slides under any of the licenses used by worg and/or the emacs wiki.
- Login to post comments
- Weiterlesen
Open Letter to Julia Hilden on her article about pay-per-use
Mi, 07/04/2012 - 16:16 — DraketoI just read your article on per use payments.
I think there are two serious flaws in per use payments:
(a) Good works of art need to last
As you stated correctly, I define myself partly through the media I "consume".
This does mean, that I want to have the assurance, that I can watch a great movie again a few years in the future.
Imagine this scenario:
- I found a really great book, read it and got entranced.
- It's 20 years later, now. and I want to read the book to my children.
- Login to post comments
- Weiterlesen
Background of Freenet Routing and the probes project (GSoC 2012)
Sa, 06/30/2012 - 20:40 — DraketoThe probes project is a google summer of code project of Steve Dougherty intended to optimize the network structure of freenet. Here I will give the background of his project very briefly:
The Small World Structure
- Login to post comments
- Weiterlesen
Minimal example for literate programming with noweb in emacs org-mode
Fr, 06/22/2012 - 11:33 — DraketoIf you want to use the literate programming features in emacs org-mode, you can try this minimal example to get started: Activate org-babel-tangle, then put this into the file noweb-test.org:
Minimal example for noweb in org-mode
* Assign
First we assign abc:
#+begin_src python :noweb-ref assign_abc
abc = "abc"
#+end_src
* Use
Then we use it in a function:
#+begin_src python :noweb tangle :tangle noweb-test.py
def x():
<<assign_abc>>
return abc
print(x())
#+end_src
- Login to post comments
- Weiterlesen
The ease of losing the spirit of your project by giving in to short-term convenience
Mo, 06/18/2012 - 17:02 — DraketoYesterday I said to my father
» Why does your whole cooperative have to meet for some minor legalese update which does not have an actual effect? Could you not just put into your statutes, that the elected leaders can take decisions which don’t affect the spirit of the statutes?
- Login to post comments
- Weiterlesen
Install and setup infocalypse on GNU/Linux (script)
Mo, 06/18/2012 - 16:39 — DraketoUpdate (2015-11-27): The script works again with newer Freenet versions.
Update 2024: Infocalypse is still recovering from Python 3 breakage. Most of it works again, but there may be rough edges left. Contributions to fix these are very welcome: hg.sr.ht/~arnebab/infocalypse or github.com/hyphanet/infocalypse.
Install and setup infocalypse on GNU/Linux:
Just download and run1 it via
wget https://www.draketo.de/files/setup_infocalypse_on_linux.sh_.txt
bash setup_infocalypse*
This script needs a running Hyphanet node to work! → Install Freenet ←
In-Freenet-link: CHK@rtJd8ThxJ~usEFOaWAvwXbHuPC6L1zOFWtKxlhUPfR8,21XedKU8YbKPGsYWu9szjY7hChX852zmFAYuvyihOd0,AAMC--8/setup_infocalypse_on_linux.sh
The script allows you to get and setup the infocalypse extension with a few keystrokes to be able to instantly use the Mercurial DVCS for decentral, anonymous code-sharing over freenet.
« Real Life Infocalypse »
DVCS in the Darknet. The decentralized p2p code repository (using Infocalypse)
-
On systems based on Debian or Gentoo - including Ubuntu and many others - this script will install all needed software except for freenet itself. You will have to give your sudo password in the process. Since the script is just a text file with a set of commands, you can simply read it to make sure that it won’t do anything evil with those sudo rights. ↩
- Login to post comments
- Weiterlesen
Custom link completion for org-mode in 25 lines (emacs)
Fr, 06/15/2012 - 22:29 — DraketoUpdate (2013-01-23): The new org-mode removed (org-make-link), so I replaced it with (concat) and uploaded a new example-file: org-custom-link-completion.el.
Happy Hacking!
Table of Contents
1 Intro
I recently set up custom completion for two of my custom link types in Emacs org-mode. When I wrote on identi.ca about that, Greg Tucker-Kellog said that he’d like to see that. So I decided, I’d publish my code.
Reducing the Python startup time
Di, 06/05/2012 - 09:47 — DraketoThe python startup time always nagged me (17-30ms) and I just searched again for a way to reduce it, when I found this:
The Python-Launcher caches GTK imports and forks new processes to reduce the startup time of python GUI programs.
Python-launcher does not solve my problem directly, but it points into an interesting direction: If you create a small daemon which you can contact via the shell to fork a new instance, you might be able to get rid of your startup time.
To get an example of the possibilities, downl
- Login to post comments
- Weiterlesen
The generation of cultural freedom
Do, 05/31/2012 - 21:15 — DraketoNew version of this article: draketo.de/politik/generation-of-cultural-freedom.html
I am part of a generation that experienced true cultural freedom—and experienced this freedom being destroyed.
We had access to the largest public library which ever existed and saw it burned down for lust for control.
I saw the Napster burn, I saw Gnutella burn, I saw edonkey burn, I saw Torrentsites burn, I saw one-click-hosters burn and now I see Youtube burn with blocked and deleted videos - even those from the artists themselves.
- Login to post comments
- Weiterlesen
El Kanban Org: parse org-mode todo-states to use org-tables as Kanban tables
So, 04/29/2012 - 14:39 — DraketoUpdate (2020): Kanban moved to sourcehut: https://hg.sr.ht/~arnebab/kanban.el
Update (2013-04-13): Kanban.el now lives in its own repository: on bitbucket and on a statically served http-repo (to be independent from unfree software).
Update (2013-04-10): Thanks to Han Duply, kanban links now work for entries from other files. And I uploaded kanban.el on marmalade.
Some time ago I learned about kanban, and the obvious next step was: “I want to have a kanban board from org-mode”. I searched for it, but did not find any. Not wanting to give up on the idea, I implemented my own :)
The result are two functions: kanban-todo and kanban-zero.
“Screenshot” :)
TODO DOING DONE Refactor in such a way that the let Presentation manage dumb sprites return all actions on every command: Make the UiState adhere the list of Turn the model into a pure state
- Login to post comments
- Weiterlesen
Read your python module documentation from emacs
Do, 04/12/2012 - 19:42 — DraketoUpdate 2021: Fixed links that died with Bitbuckets hosting.
I just found the excellent pydoc-info mode for emacs from Jon Waltman. It allows me to hit C-h S in a python file and enter a module name to see the documentation right away.
- Login to post comments
- Weiterlesen
Exploring the probability of successfully retrieving a file in freenet, given different redundancies and chunk lifetimes
Fr, 03/16/2012 - 16:20 — DraketoTable of Contents
In this text I want to explore the behaviour of the degrading yet redundant anonymous file storage in Freenet. It only applies to files which were not subsequently retrieved.
Every time you retrieve a file, it gets healed which effectively resets its timer as far as these calculations here are concerned. Due to this, popular files can and do live for years in freenet.
- Login to post comments
- Weiterlesen
The “Apple helps free software” myth
Mo, 03/12/2012 - 20:35 — Draketo→ Comment to “apple supports a number of opensource projects. Webkit and CUPS come to mind”.
Apple supports a number of copyleft projects, because they have to.
Write programs you can still hack when you feel dumb
So, 03/04/2012 - 22:55 — DraketoDebugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. — Brian Kernighan
In the article Hyperfocus and balance, Arc Riley from PySoy talks about trying to get to the Hyperfocus state without endangering his health.
- Login to post comments
- Weiterlesen
Effortless password protected sharing of files via Freenet
Sa, 02/25/2012 - 06:14 — DraketoTL;DR: Inserting a file into Freenet using the key KSK@<password> creates an invisible, password protected file which is available over Freenet.
Often you want to exchange some content only with people who know a given password and make it accessible to everyone in your little group but invisible to the outside world.
Until yesterday I thought that problem slightly complex, because everyone in your group needs a given encryption program, and you need a way to share the file without exposing the fact that you are sharing it.
Then I learned two handy facts about Freenet:
Content is invisible to all but those with the key
<ArneBab> evanbd: If I insert a tiny file without telling anyone the key, can they get the content in some way?
<evanbd> ArneBab: No.You generate a key from a password by using a KSK-key
<toad_> dogon: KSK@<any string of text> -> generate an SSK private key from the hash of the text
<toad_> dogon: if you know the string, you can both insert and retrieve it
In other words:
Just inserting a file into Freenet using the key KSK@<password> creates an invisible, password protected file which is shared over Freenet.
- Login to post comments
- Weiterlesen
Patent law overrides copyright breaks ownership
Mi, 02/01/2012 - 17:24 — DraketoConcise and clear.
In patent law, copyright and property there are two pillars: protection and control.
Protection
- Property: No person shall take that from me.
- Copyright: No person shall have the same without my permission. A monopoly.
- Patent Law: No person shall create something similar without my permission. An even stronger monopoly.
Control
- Property: I decide what happens with this.
- Copyright: I decide what happens to everything which is the same. Takes another ones property. → a monopoly¹.
- Login to post comments
- Weiterlesen
“regarding B.S. like SOPA, PIPA, … freenet seems like a good idea after all!”
Fr, 01/20/2012 - 17:22 — Draketo“Some years ago, I had a look at freenet and wasn't really convinced, now I'm back - a lot has changed, it grew bigger and insanely fast (in freenet terms), like it a lot, maybe this time I'll keep it. Especially regarding B.S. like SOPA, PIPA and other internet-crippling movements, freenet seems like a good idea after all!”
— sparky in Sone
So, if you know freenet and it did not work out for you in the past, it might be time to give it another try: freenetproject.org
- Login to post comments
- Weiterlesen
def censor_the_net()
Do, 01/19/2012 - 21:05 — Draketodef censor_the_net(): "wealth vs. democracy via media-control" try: SOPA() # see Stop Online Piracy Act except Protest: # see sopastrike.com try: PIPA() # see PROTECT IP Act except Protest: # see weak links try: OPEN() # see red herring except Protest: try: ACTA() # see Anti-Counterfeiting_Trade_Agreement except Protest: # see resignation⁽¹⁾, court, vote anyway and advise against try: CISPA() # see Stop the Online Spying Bill except Protest: # see Dangers try: CETA() # See Comprehensive Economic and Trade Agreement except Protest: # see ePetition 50705 try: TTIP() # See Transatlantic Trade and Investment Partnership except Protest: # see TTIP-Protest erreicht Brüssel and Wie wir TTIP gestoppt haben try: TISA() # See Secret Trade in Services Agreement (TISA) except Protest: # see Unter Ausschluss der Öffentlichkeit try: JEFTA() # See Wie TTIP und wieder hinter verschlossenen Türen except Protest: # see deep concern und TTIP auf Japanisch verhindern und Ein Kniefall vor Japan? und JEFTA Leaks try: Article11And13() # See Die Zensurmaschinen und das Leistungsschutzrecht kommen in die Zielgerade der EU-Gesetzgebung except Protest: # see Stop the censorship-machinery! Save the Internet! try: FreiwilligeRasterung() # See Mit Hashabgleich und TPM except Protest: # see nur für gute Menschen and „eine neue Zensursula-Kampagne“ and „Wenn Privatsphäre kriminalisiert wird, werden nur Kriminelle noch Privatsphäre haben.“ try: TERREG() # See TERREG-Verordnung except Protest: # see discord.savetheinternet and TERREG-Sharepics and Uploadfilter auf Steroiden and new online censorship powers try: Chatkontrolle() # See Nachrichtendurchleuchtung except Protest: # see KI Anzeige wegen Sexting and Wiretapping Children and Deutscher Anwaltsverein and Strategic autonomy in danger and Kinderschutzbund gegen anlasslose Scans verschlüsselter Nachrichten and droht unsere Strafverfolgung…lahmzulegen and das verdächtige Bild try: CETA_in_Gruen() # See Ratifizierung im Galopp except Protest: # see Ceta bleibt falsch and Zu wenig staatliche Kontrolle try: Danish_Chatkontrolle() # See Schattentreffen and Anwaltsverein warnt except Protest: # see Warum ist Chatkontrolle so gefährlich für uns alle? and Apothekenumschau and Forschende beklagen die Ignoranz try: Mandate_Voluntary_Control() # See Perfides Täuschungsmanöver except Protest: # See The public is being played for fools and Fight Chat Control Timeline if destroy_free_speech_and_computers(): # (english video) from __future__ import plutocracy
while wealth_breeds_wealth and wealth_gives_power: # (german text and english video) # see wealth vs. democracy via media-control (german) censor_the_net()
- Login to post comments
- Weiterlesen
Freenet anonymity: Best case and Worst case
So, 11/27/2011 - 12:00 — DraketoAs the i2p people say, anynomity is no boolean. Freenet allows you to take it a good deal further than i2p or tor, though. If you do it right.
Worst case: If all of Apple would want to find you, because you declared that you would post the videos of the new iDing - and already sent them your videos as teaser before starting to upload them from an Apple computer (and that just after they lost their beloved dictator), you might be in problems if you use Opennet. You are about as safe as with tor or i2p.
Best case: If a local politician would want to find you, after you uploaded proof that he takes bribes, and you uploaded the files to a new safe key (SSK) and used Freenet in Darknet-mode with connections only to friends who would rather die than let someone take over their computer, there’s no way in hell, you’d get found due to Freenet (the file data could betray you, or they could find you by other means, but Freenet won’t be your weak spot).
- Login to post comments
- Weiterlesen
Shackle-Feats: The poisoned Apple
Di, 10/18/2011 - 20:37 — DraketoMaking an ability mandatory which forces you to wear shackles takes your Freedom away
Making an ability mandatory which forces you to wear shackles takes your Freedom away
This is an email I sent as listener comment to Free as in Freedom.
Hi Bradley, Hi Karen,
I am currently listening to your Steve Jobs show (yes, late, but time is scarce these days).
And I side with Karen (though I use KDE):
Steve Jobs managed to make a user interface which feels very natural. And that is no problem in itself. Apple solved a problem: User interfaces are hard to use for people who don’t have computer experience and who don’t have time to learn using computers right.
But they then used that solution to lure people into traps they set up to get our money and our freedom.
- Login to post comments
- Weiterlesen
Richard M. Stallman stands for Free Software
Mi, 09/14/2011 - 05:58 — Draketo→ a comment to 10 Hackers Who Made History by Gizmodo.
As DDevine says, Richard Stallman is no proponent of Open Source, but of Free Software. Open Source was forked from the Free Software movement to the great displeasure of Stallman.
He really does not like the term Open Source, because that implies that it is only about being able to read the sources.
Different from that, Free Software is about the freedom to be in control of the programs one uses, and to change them.
More exactly it defines 4 Freedoms:
50€ for the Freenet Project - and against censorship
Mo, 09/12/2011 - 17:56 — DraketoAs I pledged1, I just donated to freenet 50€ of the money I got back because I cannot go to FilkCONtinental. Thanks go to Nemesis, a proud member of the “FiB: Filkers in Black” who will take my place at the Freusburg and fill these old walls with songs of stars and dreams - and happy laughter.
It’s a hard battle against censorship, and as I now had some money at hand, I decided to do my part (freenetproject.org/donate.html).
-
The pledge can be seen in identi.ca and in a Sone post in freenet (including a comment thread; needs a running freenet node (install freenet in a few clicks) and the Sone plugin). ↩
- Login to post comments
- Weiterlesen
Diese Seite nutzt Cookies. Und Bilder. Manchmal auch Text. Eins davon muss ich wohl erwähnen — sagen die meisten anderen, und ich habe grade keine Zeit, Rechtstexte dazu zu lesen…